 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Reward Hacking in RLHF via Bayesian Non-negative Reward Modeling
Feb 11, 2026Reward models learned from human preferences are central to aligning large language models (LLMs) via reinforcement learning from human feedback, yet they are often vulnerable to reward hacking due to noisy annotations and systematic biases such as response length or style. We propose Bayesian Non-Negative Reward Model (BNRM), a principled reward modeling framework that integrates non-negative factor analysis into Bradley-Terry (BT) preference model. BNRM represents rewards through a sparse, non-negative latent factor generative process that operates at two complementary levels: instance-specific latent variables induce disentangled reward representations, while sparsity over global latent factors acts as an implicit debiasing mechanism that suppresses spurious correlations. Together, this disentanglement-then-debiasing structure enables robust uncertainty-aware reward learning. To scale BNRM to modern LLMs, we develop an amortized variational inference network conditioned on deep model representations, allowing efficient end-to-end training. Extensive empirical results demonstrate that BNRM substantially mitigates reward over-optimization, improves robustness under distribution shifts, and yields more interpretable reward decompositions than strong baselines.
Enhancing Uncertainty Estimation and Interpretability via Bayesian Non-negative Decision Layer
May 28, 2025



Although deep neural networks have demonstrated significant success due to their powerful expressiveness, most models struggle to meet practical requirements for uncertainty estimation. Concurrently, the entangled nature of deep neural networks leads to a multifaceted problem, where various localized explanation techniques reveal that multiple unrelated features influence the decisions, thereby undermining interpretability. To address these challenges, we develop a Bayesian Non-negative Decision Layer (BNDL), which reformulates deep neural networks as a conditional Bayesian non-negative factor analysis. By leveraging stochastic latent variables, the BNDL can model complex dependencies and provide robust uncertainty estimation. Moreover, the sparsity and non-negativity of the latent variables encourage the model to learn disentangled representations and decision layers, thereby improving interpretability. We also offer theoretical guarantees that BNDL can achieve effective disentangled learning. In addition, we developed a corresponding variational inference method utilizing a Weibull variational inference network to approximate the posterior distribution of the latent variables. Our experimental results demonstrate that with enhanced disentanglement capabilities, BNDL not only improves the model's accuracy but also provides reliable uncertainty estimation and improved interpretability.
Treating Brain-inspired Memories as Priors for Diffusion Model to Forecast Multivariate Time Series
Sep 27, 2024Forecasting Multivariate Time Series (MTS) involves significant challenges in various application domains. One immediate challenge is modeling temporal patterns with the finite length of the input. These temporal patterns usually involve periodic and sudden events that recur across different channels. To better capture temporal patterns, we get inspiration from humans' memory mechanisms and propose a channel-shared, brain-inspired memory module for MTS. Specifically, brain-inspired memory comprises semantic and episodic memory, where the former is used to capture general patterns, such as periodic events, and the latter is employed to capture special patterns, such as sudden events, respectively. Meanwhile, we design corresponding recall and update mechanisms to better utilize these patterns. Furthermore, acknowledging the capacity of diffusion models to leverage memory as a prior, we present a brain-inspired memory-augmented diffusion model. This innovative model retrieves relevant memories for different channels, utilizing them as distinct priors for MTS predictions. This incorporation significantly enhances the accuracy and robustness of predictions. Experimental results on eight datasets consistently validate the superiority of our approach in capturing and leveraging diverse recurrent temporal patterns across different channels.
Disentangled Generative Graph Representation Learning
Aug 24, 2024Recently, generative graph models have shown promising results in learning graph representations through self-supervised methods. However, most existing generative graph representation learning (GRL) approaches rely on random masking across the entire graph, which overlooks the entanglement of learned representations. This oversight results in non-robustness and a lack of explainability. Furthermore, disentangling the learned representations remains a significant challenge and has not been sufficiently explored in GRL research. Based on these insights, this paper introduces DiGGR (Disentangled Generative Graph Representation Learning), a self-supervised learning framework. DiGGR aims to learn latent disentangled factors and utilizes them to guide graph mask modeling, thereby enhancing the disentanglement of learned representations and enabling end-to-end joint learning. Extensive experiments on 11 public datasets for two different graph learning tasks demonstrate that DiGGR consistently outperforms many previous self-supervised methods, verifying the effectiveness of the proposed approach.
A Non-negative VAE:the Generalized Gamma Belief Network
Aug 06, 2024The gamma belief network (GBN), often regarded as a deep topic model, has demonstrated its potential for uncovering multi-layer interpretable latent representations in text data. Its notable capability to acquire interpretable latent factors is partially attributed to sparse and non-negative gamma-distributed latent variables. However, the existing GBN and its variations are constrained by the linear generative model, thereby limiting their expressiveness and applicability. To address this limitation, we introduce the generalized gamma belief network (Generalized GBN) in this paper, which extends the original linear generative model to a more expressive non-linear generative model. Since the parameters of the Generalized GBN no longer possess an analytic conditional posterior, we further propose an upward-downward Weibull inference network to approximate the posterior distribution of the latent variables. The parameters of both the generative model and the inference network are jointly trained within the variational inference framework. Finally, we conduct comprehensive experiments on both expressivity and disentangled representation learning tasks to evaluate the performance of the Generalized GBN against state-of-the-art Gaussian variational autoencoders serving as baselines.
Contrastive Factor Analysis
Aug 01, 2024



Factor analysis, often regarded as a Bayesian variant of matrix factorization, offers superior capabilities in capturing uncertainty, modeling complex dependencies, and ensuring robustness. As the deep learning era arrives, factor analysis is receiving less and less attention due to their limited expressive ability. On the contrary, contrastive learning has emerged as a potent technique with demonstrated efficacy in unsupervised representational learning. While the two methods are different paradigms, recent theoretical analysis has revealed the mathematical equivalence between contrastive learning and matrix factorization, providing a potential possibility for factor analysis combined with contrastive learning. Motivated by the interconnectedness of contrastive learning, matrix factorization, and factor analysis, this paper introduces a novel Contrastive Factor Analysis framework, aiming to leverage factor analysis's advantageous properties within the realm of contrastive learning. To further leverage the interpretability properties of non-negative factor analysis, which can learn disentangled representations, contrastive factor analysis is extended to a non-negative version. Finally, extensive experimental validation showcases the efficacy of the proposed contrastive (non-negative) factor analysis methodology across multiple key properties, including expressiveness, robustness, interpretability, and accurate uncertainty estimation.
Patch-Token Aligned Bayesian Prompt Learning for Vision-Language Models
Mar 16, 2023For downstream applications of vision-language pre-trained models, there has been significant interest in constructing effective prompts. Existing works on prompt engineering, which either require laborious manual designs or optimize the prompt tuning as a point estimation problem, may fail to describe diverse characteristics of categories and limit their applications. We introduce a Bayesian probabilistic resolution to prompt learning, where the label-specific stochastic prompts are generated hierarchically by first sampling a latent vector from an underlying distribution and then employing a lightweight generative model. Importantly, we semantically regularize prompt learning with the visual knowledge and view images and the corresponding prompts as patch and token sets under optimal transport, which pushes the prompt tokens to faithfully capture the label-specific visual concepts, instead of overfitting the training categories. Moreover, the proposed model can also be straightforwardly extended to the conditional case where the instance-conditional prompts are generated to improve the generalizability. Extensive experiments on 15 datasets show promising transferability and generalization performance of our proposed model.
HyperMiner: Topic Taxonomy Mining with Hyperbolic Embedding
Oct 16, 2022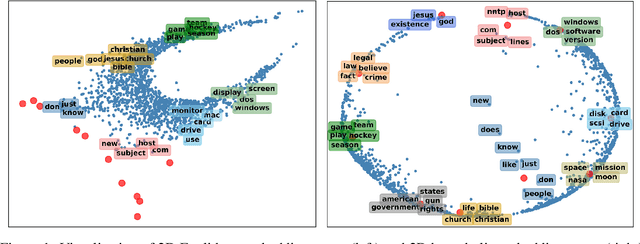
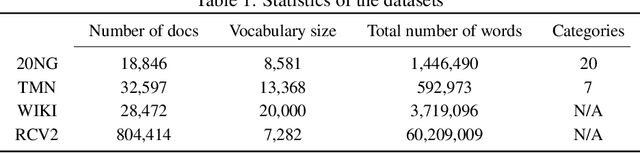
Embedded topic models are able to learn interpretable topics even with large and heavy-tailed vocabularies. However, they generally hold the Euclidean embedding space assumption, leading to a basic limitation in capturing hierarchical relations. To this end, we present a novel framework that introduces hyperbolic embeddings to represent words and topics. With the tree-likeness property of hyperbolic space, the underlying semantic hierarchy among words and topics can be better exploited to mine more interpretable topics. Furthermore, due to the superiority of hyperbolic geometry in representing hierarchical data, tree-structure knowledge can also be naturally injected to guide the learning of a topic hierarchy. Therefore, we further develop a regularization term based on the idea of contrastive learning to inject prior structural knowledge efficiently. Experiments on both topic taxonomy discovery and document representation demonstrate that the proposed framework achieves improved performance against existing embedded topic models.
Knowledge-Aware Bayesian Deep Topic Model
Sep 20, 2022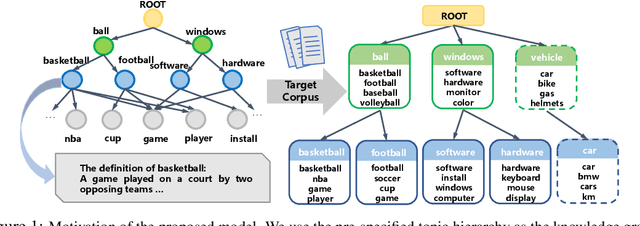
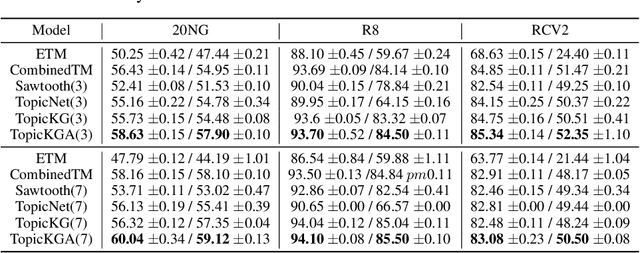

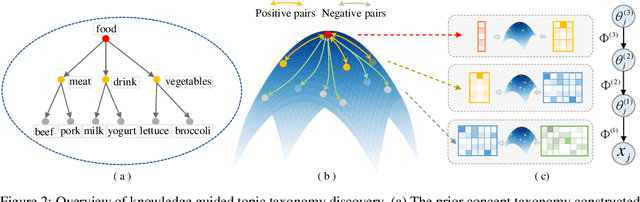
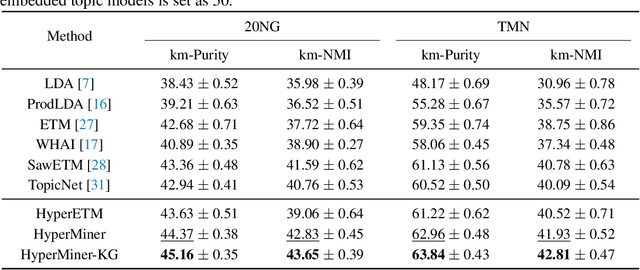
We propose a Bayesian generative model for incorporating prior domain knowledge into hierarchical topic modeling. Although embedded topic models (ETMs) and its variants have gained promising performance in text analysis, they mainly focus on mining word co-occurrence patterns, ignoring potentially easy-to-obtain prior topic hierarchies that could help enhance topic coherence. While several knowledge-based topic models have recently been proposed, they are either only applicable to shallow hierarchies or sensitive to the quality of the provided prior knowledge. To this end, we develop a novel deep ETM that jointly models the documents and the given prior knowledge by embedding the words and topics into the same space. Guided by the provided knowledge, the proposed model tends to discover topic hierarchies that are organized into interpretable taxonomies. Besides, with a technique for adapting a given graph, our extended version allows the provided prior topic structure to be finetuned to match the target corpus. Extensive experiments show that our proposed model efficiently integrates the prior knowledge and improves both hierarchical topic discovery and document representation.
TopicNet: Semantic Graph-Guided Topic Discovery
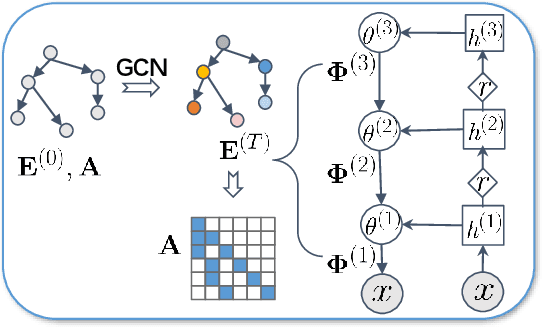
Oct 27, 2021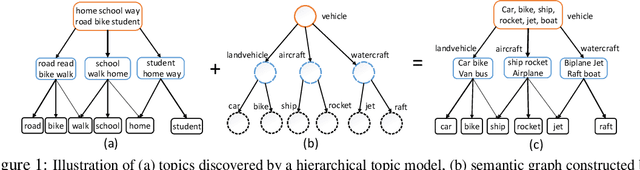
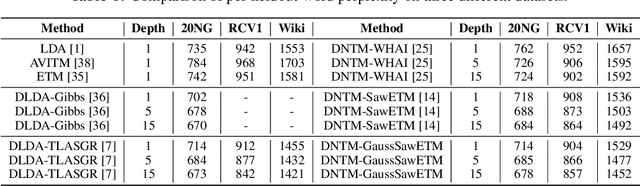
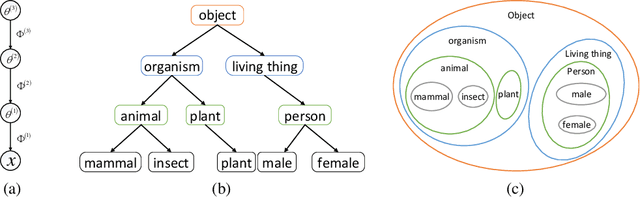
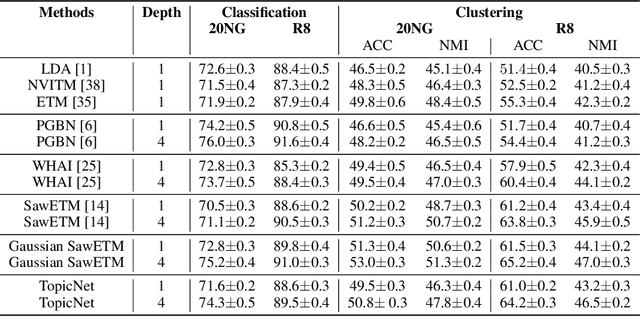
Existing deep hierarchical topic models are able to extract semantically meaningful topics from a text corpus in an unsupervised manner and automatically organize them into a topic hierarchy. However, it is unclear how to incorporate prior beliefs such as knowledge graph to guide the learning of the topic hierarchy. To address this issue, we introduce TopicNet as a deep hierarchical topic model that can inject prior structural knowledge as an inductive bias to influence learning. TopicNet represents each topic as a Gaussian-distributed embedding vector, projects the topics of all layers into a shared embedding space, and explores both the symmetric and asymmetric similarities between Gaussian embedding vectors to incorporate prior semantic hierarchies. With an auto-encoding variational inference network, the model parameters are optimized by minimizing the evidence lower bound and a regularization term via stochastic gradient descent. Experiments on widely used benchmarks show that TopicNet outperforms related deep topic models on discovering deeper interpretable topics and mining better document~representations.