 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Directed Acyclic Hypergraph Learning
Jun 19, 2026Continuous optimization methods for learning Directed Acyclic Graphs (DAGs) operate on weighted adjacency matrices and are therefore limited to pairwise causal relationships. We propose a framework for learning Directed Acyclic Hypergraphs (DAHGs) from observational data, capturing joint parental influences that pairwise models cannot represent. Our approach rests on three components: (i) a generalized linear structural equation model (SEM) with multiplicative interaction terms whose non-zero weights correspond one-to-one with directed hyperedges; (ii) a weighted adjacency tensor representation whose acyclicity is characterized via nilpotency under the tensor t-product; and (iii) a differentiable acyclicity constraint derived through the Fourier decomposition of the t-product, which reduces tensor nilpotency to slice-wise matrix nilpotency and enables least-squares learning via the augmented Lagrangian method.
An AI-native experimental laboratory for autonomous biomolecular engineering
Jul 03, 2025



Autonomous scientific research, capable of independently conducting complex experiments and serving non-specialists, represents a long-held aspiration. Achieving it requires a fundamental paradigm shift driven by artificial intelligence (AI). While autonomous experimental systems are emerging, they remain confined to areas featuring singular objectives and well-defined, simple experimental workflows, such as chemical synthesis and catalysis. We present an AI-native autonomous laboratory, targeting highly complex scientific experiments for applications like autonomous biomolecular engineering. This system autonomously manages instrumentation, formulates experiment-specific procedures and optimization heuristics, and concurrently serves multiple user requests. Founded on a co-design philosophy of models, experiments, and instruments, the platform supports the co-evolution of AI models and the automation system. This establishes an end-to-end, multi-user autonomous laboratory that handles complex, multi-objective experiments across diverse instrumentation. Our autonomous laboratory supports fundamental nucleic acid functions-including synthesis, transcription, amplification, and sequencing. It also enables applications in fields such as disease diagnostics, drug development, and information storage. Without human intervention, it autonomously optimizes experimental performance to match state-of-the-art results achieved by human scientists. In multi-user scenarios, the platform significantly improves instrument utilization and experimental efficiency. This platform paves the way for advanced biomaterials research to overcome dependencies on experts and resource barriers, establishing a blueprint for science-as-a-service at scale.
Learned Indexes for Dynamic Workloads
Feb 02, 2019
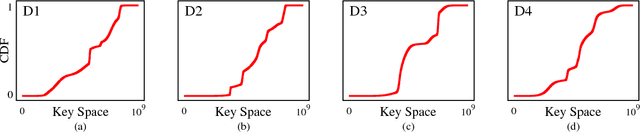
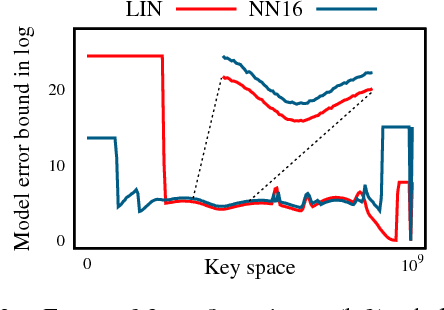
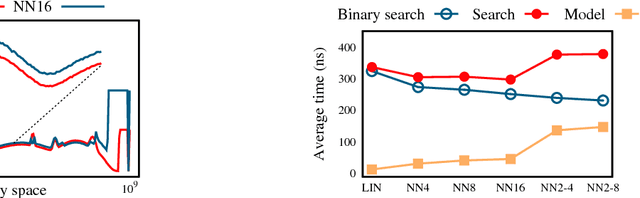
The recent proposal of learned index structures opens up a new perspective on how traditional range indexes can be optimized. However, the current learned indexes assume the data distribution is relatively static and the access pattern is uniform, while real-world scenarios consist of skew query distribution and evolving data. In this paper, we demonstrate that the missing consideration of access patterns and dynamic data distribution notably hinders the applicability of learned indexes. To this end, we propose solutions for learned indexes for dynamic workloads (called Doraemon). To improve the latency for skew queries, Doraemon augments the training data with access frequencies. To address the slow model re-training when data distribution shifts, Doraemon caches the previously-trained models and incrementally fine-tunes them for similar access patterns and data distribution. Our preliminary result shows that, Doraemon improves the query latency by 45.1% and reduces the model re-training time to 1/20.