 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWater Simulation and Rendering from a Still Photograph
Oct 05, 2022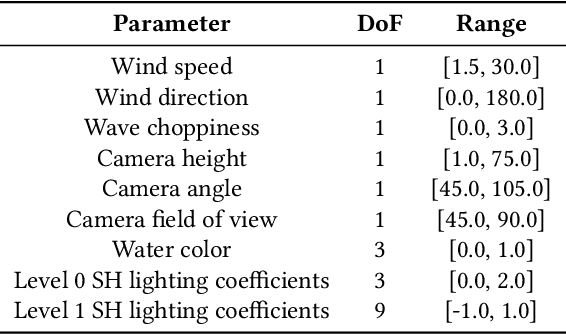
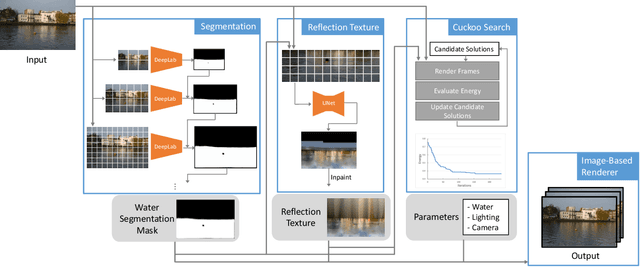


We propose an approach to simulate and render realistic water animation from a single still input photograph. We first segment the water surface, estimate rendering parameters, and compute water reflection textures with a combination of neural networks and traditional optimization techniques. Then we propose an image-based screen space local reflection model to render the water surface overlaid on the input image and generate real-time water animation. Our approach creates realistic results with no user intervention for a wide variety of natural scenes containing large bodies of water with different lighting and water surface conditions. Since our method provides a 3D representation of the water surface, it naturally enables direct editing of water parameters and also supports interactive applications like adding synthetic objects to the scene.
DenseGAP: Graph-Structured Dense Correspondence Learning with Anchor Points
Dec 13, 2021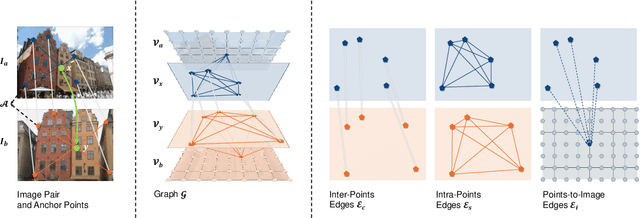
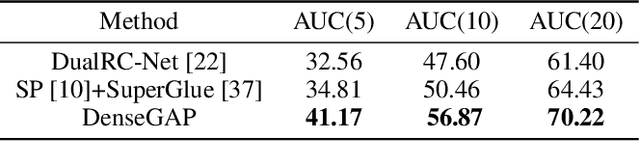

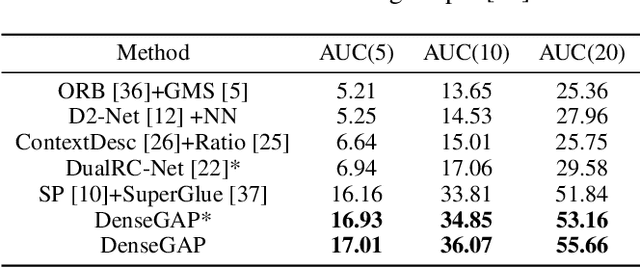
Establishing dense correspondence between two images is a fundamental computer vision problem, which is typically tackled by matching local feature descriptors. However, without global awareness, such local features are often insufficient for disambiguating similar regions. And computing the pairwise feature correlation across images is both computation-expensive and memory-intensive. To make the local features aware of the global context and improve their matching accuracy, we introduce DenseGAP, a new solution for efficient Dense correspondence learning with a Graph-structured neural network conditioned on Anchor Points. Specifically, we first propose a graph structure that utilizes anchor points to provide sparse but reliable prior on inter- and intra-image context and propagates them to all image points via directed edges. We also design a graph-structured network to broadcast multi-level contexts via light-weighted message-passing layers and generate high-resolution feature maps at low memory cost. Finally, based on the predicted feature maps, we introduce a coarse-to-fine framework for accurate correspondence prediction using cycle consistency. Our feature descriptors capture both local and global information, thus enabling a continuous feature field for querying arbitrary points at high resolution. Through comprehensive ablative experiments and evaluations on large-scale indoor and outdoor datasets, we demonstrate that our method advances the state-of-the-art of correspondence learning on most benchmarks.
CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields
Dec 09, 2021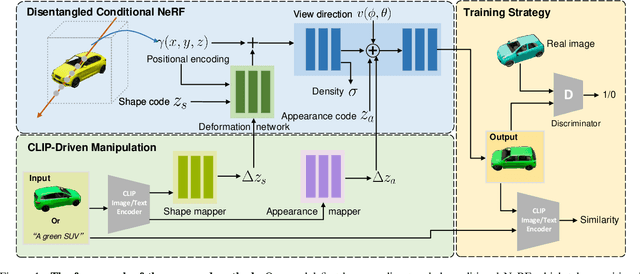
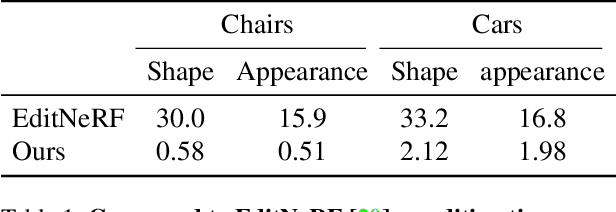
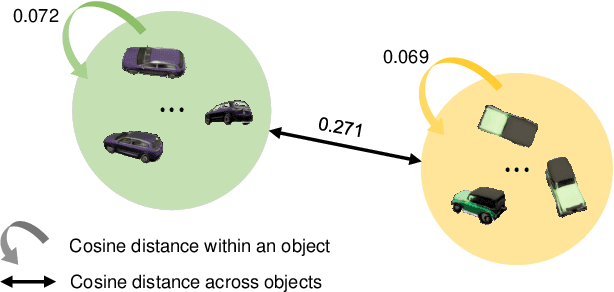
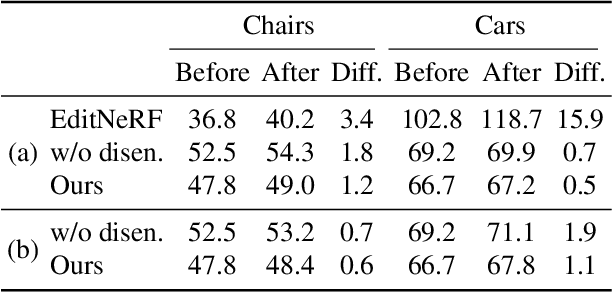
We present CLIP-NeRF, a multi-modal 3D object manipulation method for neural radiance fields (NeRF). By leveraging the joint language-image embedding space of the recent Contrastive Language-Image Pre-Training (CLIP) model, we propose a unified framework that allows manipulating NeRF in a user-friendly way, using either a short text prompt or an exemplar image. Specifically, to combine the novel view synthesis capability of NeRF and the controllable manipulation ability of latent representations from generative models, we introduce a disentangled conditional NeRF architecture that allows individual control over both shape and appearance. This is achieved by performing the shape conditioning via applying a learned deformation field to the positional encoding and deferring color conditioning to the volumetric rendering stage. To bridge this disentangled latent representation to the CLIP embedding, we design two code mappers that take a CLIP embedding as input and update the latent codes to reflect the targeted editing. The mappers are trained with a CLIP-based matching loss to ensure the manipulation accuracy. Furthermore, we propose an inverse optimization method that accurately projects an input image to the latent codes for manipulation to enable editing on real images. We evaluate our approach by extensive experiments on a variety of text prompts and exemplar images and also provide an intuitive interface for interactive editing. Our implementation is available at https://cassiepython.github.io/clipnerf/
DisUnknown: Distilling Unknown Factors for Disentanglement Learning
Sep 16, 2021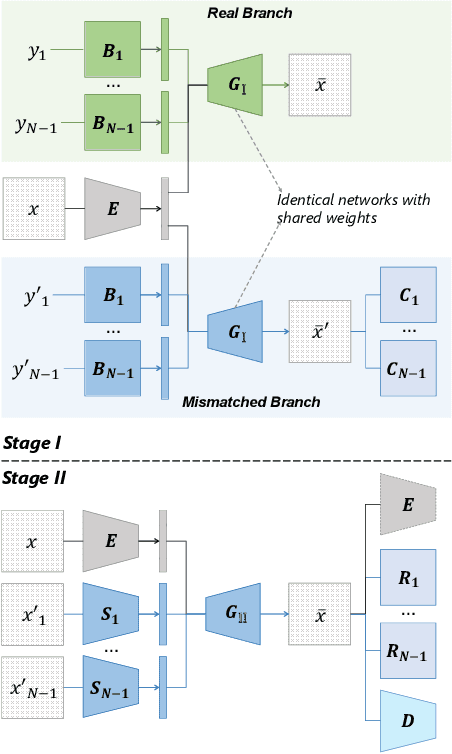
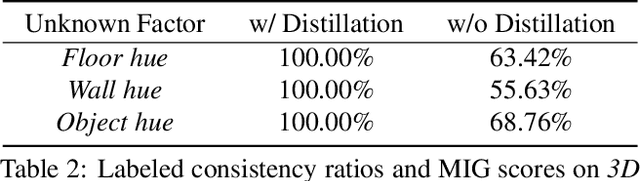
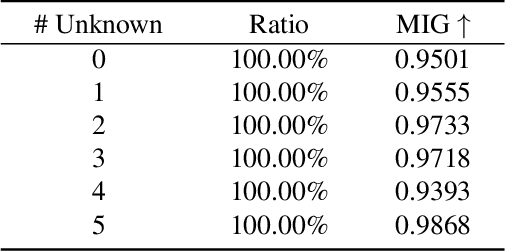

Disentangling data into interpretable and independent factors is critical for controllable generation tasks. With the availability of labeled data, supervision can help enforce the separation of specific factors as expected. However, it is often expensive or even impossible to label every single factor to achieve fully-supervised disentanglement. In this paper, we adopt a general setting where all factors that are hard to label or identify are encapsulated as a single unknown factor. Under this setting, we propose a flexible weakly-supervised multi-factor disentanglement framework DisUnknown, which Distills Unknown factors for enabling multi-conditional generation regarding both labeled and unknown factors. Specifically, a two-stage training approach is adopted to first disentangle the unknown factor with an effective and robust training method, and then train the final generator with the proper disentanglement of all labeled factors utilizing the unknown distillation. To demonstrate the generalization capacity and scalability of our method, we evaluate it on multiple benchmark datasets qualitatively and quantitatively and further apply it to various real-world applications on complicated datasets.
Exemplar-Based 3D Portrait Stylization
Apr 29, 2021

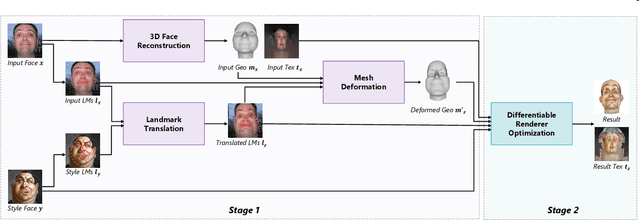

Exemplar-based portrait stylization is widely attractive and highly desired. Despite recent successes, it remains challenging, especially when considering both texture and geometric styles. In this paper, we present the first framework for one-shot 3D portrait style transfer, which can generate 3D face models with both the geometry exaggerated and the texture stylized while preserving the identity from the original content. It requires only one arbitrary style image instead of a large set of training examples for a particular style, provides geometry and texture outputs that are fully parameterized and disentangled, and enables further graphics applications with the 3D representations. The framework consists of two stages. In the first geometric style transfer stage, we use facial landmark translation to capture the coarse geometry style and guide the deformation of the dense 3D face geometry. In the second texture style transfer stage, we focus on performing style transfer on the canonical texture by adopting a differentiable renderer to optimize the texture in a multi-view framework. Experiments show that our method achieves robustly good results on different artistic styles and outperforms existing methods. We also demonstrate the advantages of our method via various 2D and 3D graphics applications. Project page is https://halfjoe.github.io/projs/3DPS/index.html.
Cross-Domain and Disentangled Face Manipulation with 3D Guidance
Apr 22, 2021
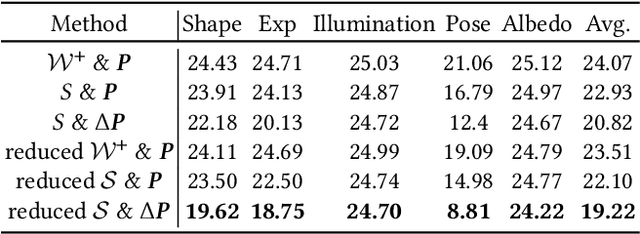
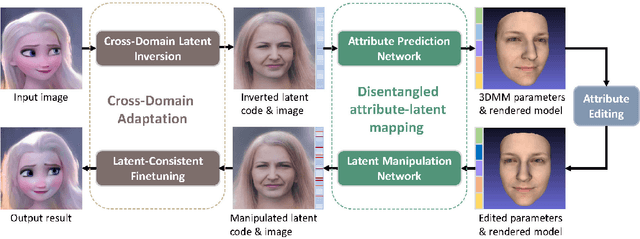
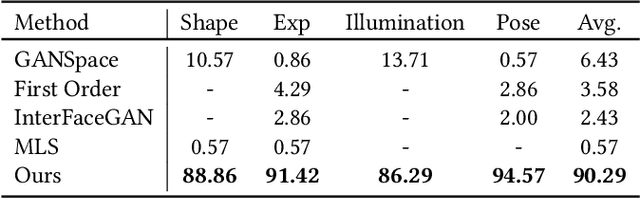
Face image manipulation via three-dimensional guidance has been widely applied in various interactive scenarios due to its semantically-meaningful understanding and user-friendly controllability. However, existing 3D-morphable-model-based manipulation methods are not directly applicable to out-of-domain faces, such as non-photorealistic paintings, cartoon portraits, or even animals, mainly due to the formidable difficulties in building the model for each specific face domain. To overcome this challenge, we propose, as far as we know, the first method to manipulate faces in arbitrary domains using human 3DMM. This is achieved through two major steps: 1) disentangled mapping from 3DMM parameters to the latent space embedding of a pre-trained StyleGAN2 that guarantees disentangled and precise controls for each semantic attribute; and 2) cross-domain adaptation that bridges domain discrepancies and makes human 3DMM applicable to out-of-domain faces by enforcing a consistent latent space embedding. Experiments and comparisons demonstrate the superiority of our high-quality semantic manipulation method on a variety of face domains with all major 3D facial attributes controllable: pose, expression, shape, albedo, and illumination. Moreover, we develop an intuitive editing interface to support user-friendly control and instant feedback. Our project page is https://cassiepython.github.io/sigasia/cddfm3d.html.
Semantic Image Synthesis via Efficient Class-Adaptive Normalization
Dec 08, 2020

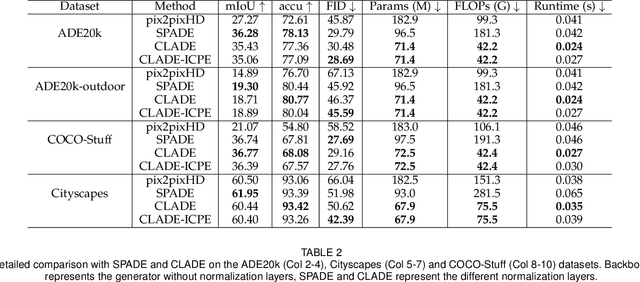
Spatially-adaptive normalization (SPADE) is remarkably successful recently in conditional semantic image synthesis, which modulates the normalized activation with spatially-varying transformations learned from semantic layouts, to prevent the semantic information from being washed away. Despite its impressive performance, a more thorough understanding of the advantages inside the box is still highly demanded to help reduce the significant computation and parameter overhead introduced by this novel structure. In this paper, from a return-on-investment point of view, we conduct an in-depth analysis of the effectiveness of this spatially-adaptive normalization and observe that its modulation parameters benefit more from semantic-awareness rather than spatial-adaptiveness, especially for high-resolution input masks. Inspired by this observation, we propose class-adaptive normalization (CLADE), a lightweight but equally-effective variant that is only adaptive to semantic class. In order to further improve spatial-adaptiveness, we introduce intra-class positional map encoding calculated from semantic layouts to modulate the normalization parameters of CLADE and propose a truly spatially-adaptive variant of CLADE, namely CLADE-ICPE. %Benefiting from this design, CLADE greatly reduces the computation cost while being able to preserve the semantic information in the generation. Through extensive experiments on multiple challenging datasets, we demonstrate that the proposed CLADE can be generalized to different SPADE-based methods while achieving comparable generation quality compared to SPADE, but it is much more efficient with fewer extra parameters and lower computational cost. The code is available at https://github.com/tzt101/CLADE.git
Dynamic Facial Asset and Rig Generation from a Single Scan
Oct 05, 2020
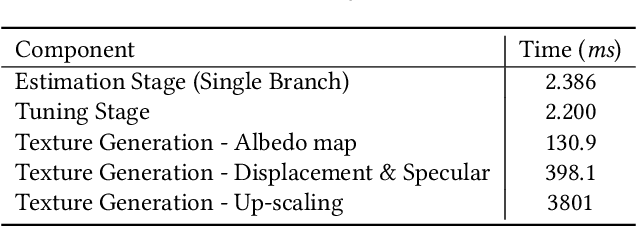
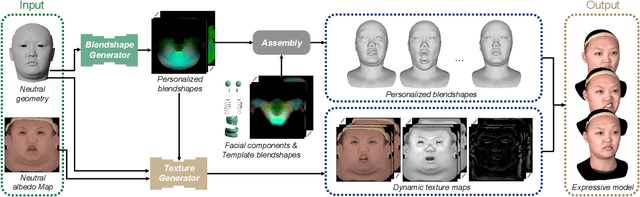

The creation of high-fidelity computer-generated (CG) characters used in film and gaming requires intensive manual labor and a comprehensive set of facial assets to be captured with complex hardware, resulting in high cost and long production cycles. In order to simplify and accelerate this digitization process, we propose a framework for the automatic generation of high-quality dynamic facial assets, including rigs which can be readily deployed for artists to polish. Our framework takes a single scan as input to generate a set of personalized blendshapes, dynamic and physically-based textures, as well as secondary facial components (e.g., teeth and eyeballs). Built upon a facial database consisting of pore-level details, with over $4,000$ scans of varying expressions and identities, we adopt a self-supervised neural network to learn personalized blendshapes from a set of template expressions. We also model the joint distribution between identities and expressions, enabling the inference of the full set of personalized blendshapes with dynamic appearances from a single neutral input scan. Our generated personalized face rig assets are seamlessly compatible with cutting-edge industry pipelines for facial animation and rendering. We demonstrate that our framework is robust and effective by inferring on a wide range of novel subjects, and illustrate compelling rendering results while animating faces with generated customized physically-based dynamic textures.
One-Shot Identity-Preserving Portrait Reenactment
Apr 26, 2020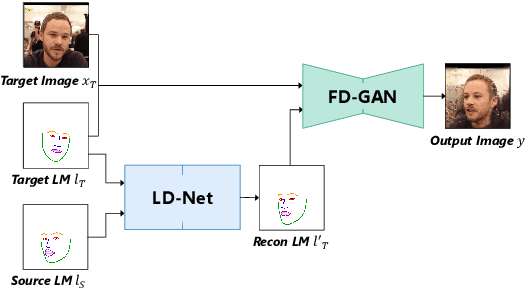

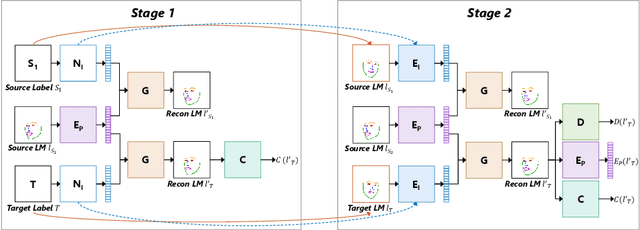
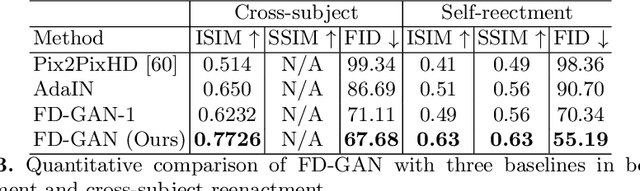
We present a deep learning-based framework for portrait reenactment from a single picture of a target (one-shot) and a video of a driving subject. Existing facial reenactment methods suffer from identity mismatch and produce inconsistent identities when a target and a driving subject are different (cross-subject), especially in one-shot settings. In this work, we aim to address identity preservation in cross-subject portrait reenactment from a single picture. We introduce a novel technique that can disentangle identity from expressions and poses, allowing identity preserving portrait reenactment even when the driver's identity is very different from that of the target. This is achieved by a novel landmark disentanglement network (LD-Net), which predicts personalized facial landmarks that combine the identity of the target with expressions and poses from a different subject. To handle portrait reenactment from unseen subjects, we also introduce a feature dictionary-based generative adversarial network (FD-GAN), which locally translates 2D landmarks into a personalized portrait, enabling one-shot portrait reenactment under large pose and expression variations. We validate the effectiveness of our identity disentangling capabilities via an extensive ablation study, and our method produces consistent identities for cross-subject portrait reenactment. Our comprehensive experiments show that our method significantly outperforms the state-of-the-art single-image facial reenactment methods. We will release our code and models for academic use.
Rethinking Spatially-Adaptive Normalization
Apr 06, 2020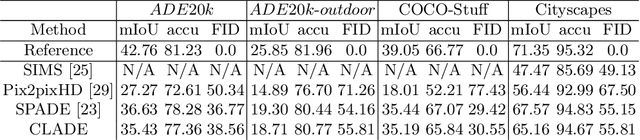
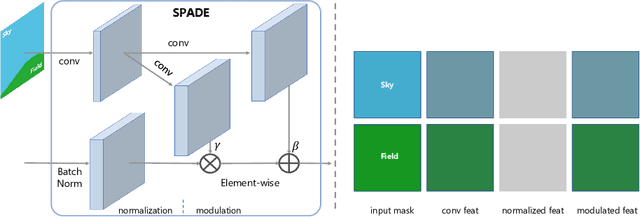


Spatially-adaptive normalization is remarkably successful recently in conditional semantic image synthesis, which modulates the normalized activation with spatially-varying transformations learned from semantic layouts, to preserve the semantic information from being washed away. Despite its impressive performance, a more thorough understanding of the true advantages inside the box is still highly demanded, to help reduce the significant computation and parameter overheads introduced by these new structures. In this paper, from a return-on-investment point of view, we present a deep analysis of the effectiveness of SPADE and observe that its advantages actually come mainly from its semantic-awareness rather than the spatial-adaptiveness. Inspired by this point, we propose class-adaptive normalization (CLADE), a lightweight variant that is not adaptive to spatial positions or layouts. Benefited from this design, CLADE greatly reduces the computation cost while still being able to preserve the semantic information during the generation. Extensive experiments on multiple challenging datasets demonstrate that while the resulting fidelity is on par with SPADE, its overhead is much cheaper than SPADE. Take the generator for ADE20k dataset as an example, the extra parameter and computation cost introduced by CLADE are only 4.57% and 0.07% while that of SPADE are 39.21% and 234.73% respectively.