 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Role of Token Retrieval in Multi-Vector Retrieval
Apr 04, 2023Multi-vector retrieval models such as ColBERT [Khattab and Zaharia, 2020] allow token-level interactions between queries and documents, and hence achieve state of the art on many information retrieval benchmarks. However, their non-linear scoring function cannot be scaled to millions of documents, necessitating a three-stage process for inference: retrieving initial candidates via token retrieval, accessing all token vectors, and scoring the initial candidate documents. The non-linear scoring function is applied over all token vectors of each candidate document, making the inference process complicated and slow. In this paper, we aim to simplify the multi-vector retrieval by rethinking the role of token retrieval. We present XTR, ConteXtualized Token Retriever, which introduces a simple, yet novel, objective function that encourages the model to retrieve the most important document tokens first. The improvement to token retrieval allows XTR to rank candidates only using the retrieved tokens rather than all tokens in the document, and enables a newly designed scoring stage that is two-to-three orders of magnitude cheaper than that of ColBERT. On the popular BEIR benchmark, XTR advances the state-of-the-art by 2.8 nDCG@10 without any distillation. Detailed analysis confirms our decision to revisit the token retrieval stage, as XTR demonstrates much better recall of the token retrieval stage compared to ColBERT.
Open-domain Visual Entity Recognition: Towards Recognizing Millions of Wikipedia Entities
Feb 24, 2023



Large-scale multi-modal pre-training models such as CLIP and PaLI exhibit strong generalization on various visual domains and tasks. However, existing image classification benchmarks often evaluate recognition on a specific domain (e.g., outdoor images) or a specific task (e.g., classifying plant species), which falls short of evaluating whether pre-trained foundational models are universal visual recognizers. To address this, we formally present the task of Open-domain Visual Entity recognitioN (OVEN), where a model need to link an image onto a Wikipedia entity with respect to a text query. We construct OVEN-Wiki by re-purposing 14 existing datasets with all labels grounded onto one single label space: Wikipedia entities. OVEN challenges models to select among six million possible Wikipedia entities, making it a general visual recognition benchmark with the largest number of labels. Our study on state-of-the-art pre-trained models reveals large headroom in generalizing to the massive-scale label space. We show that a PaLI-based auto-regressive visual recognition model performs surprisingly well, even on Wikipedia entities that have never been seen during fine-tuning. We also find existing pretrained models yield different strengths: while PaLI-based models obtain higher overall performance, CLIP-based models are better at recognizing tail entities.
Can Pre-trained Vision and Language Models Answer Visual Information-Seeking Questions?
Feb 24, 2023



Large language models have demonstrated an emergent capability in answering knowledge intensive questions. With recent progress on web-scale visual and language pre-training, do these models also understand how to answer visual information seeking questions? To answer this question, we present InfoSeek, a Visual Question Answering dataset that focuses on asking information-seeking questions, where the information can not be answered by common sense knowledge. We perform a multi-stage human annotation to collect a natural distribution of high-quality visual information seeking question-answer pairs. We also construct a large-scale, automatically collected dataset by combining existing visual entity recognition datasets and Wikidata, which provides over one million examples for model fine-tuning and validation. Based on InfoSeek, we analyzed various pre-trained Visual QA systems to gain insights into the characteristics of different pre-trained models. Our analysis shows that it is challenging for the state-of-the-art multi-modal pre-trained models to answer visual information seeking questions, but this capability is improved through fine-tuning on the automated InfoSeek dataset. We hope our analysis paves the way to understand and develop the next generation of multi-modal pre-training.
Meta-Learning Fast Weight Language Models
Dec 05, 2022



Dynamic evaluation of language models (LMs) adapts model parameters at test time using gradient information from previous tokens and substantially improves LM performance. However, it requires over 3x more compute than standard inference. We present Fast Weight Layers (FWLs), a neural component that provides the benefits of dynamic evaluation much more efficiently by expressing gradient updates as linear attention. A key improvement over dynamic evaluation is that FWLs can also be applied at training time so the model learns to make good use of gradient updates. FWLs can easily be added on top of existing transformer models, require relatively little extra compute or memory to run, and significantly improve language modeling perplexity.
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
Oct 07, 2022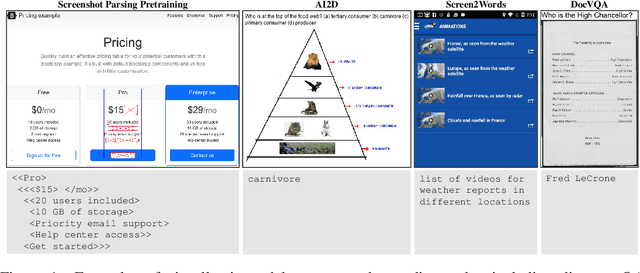


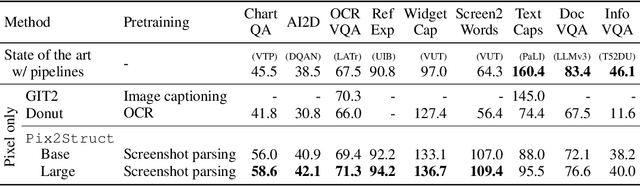
Visually-situated language is ubiquitous -- sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and forms. Perhaps due to this diversity, previous work has typically relied on domain-specific recipes with limited sharing of the underlying data, model architectures, and objectives. We present Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy, we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions are rendered directly on top of the input image. For the first time, we show that a single pretrained model can achieve state-of-the-art results in six out of nine tasks across four domains: documents, illustrations, user interfaces, and natural images.
Promptagator: Few-shot Dense Retrieval From 8 Examples
Sep 23, 2022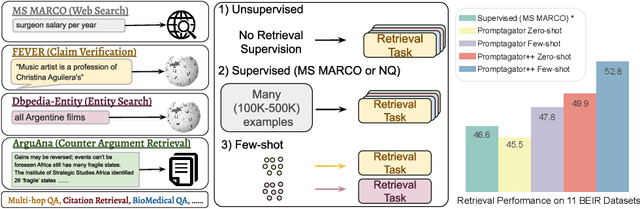
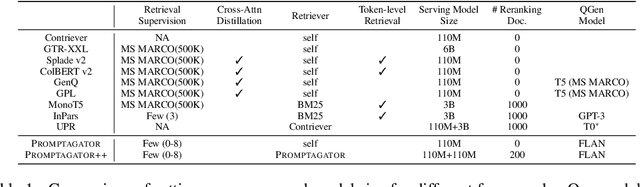
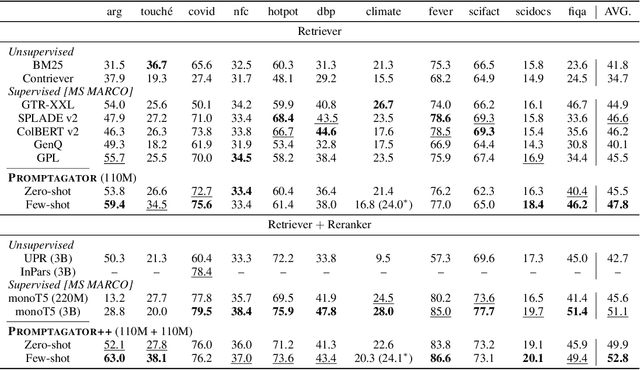
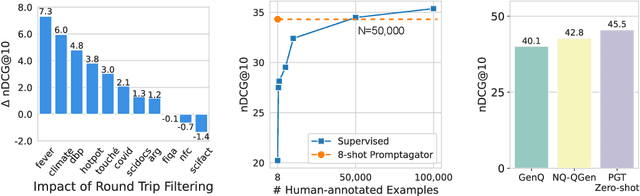
Much recent research on information retrieval has focused on how to transfer from one task (typically with abundant supervised data) to various other tasks where supervision is limited, with the implicit assumption that it is possible to generalize from one task to all the rest. However, this overlooks the fact that there are many diverse and unique retrieval tasks, each targeting different search intents, queries, and search domains. In this paper, we suggest to work on Few-shot Dense Retrieval, a setting where each task comes with a short description and a few examples. To amplify the power of a few examples, we propose Prompt-base Query Generation for Retriever (Promptagator), which leverages large language models (LLM) as a few-shot query generator, and creates task-specific retrievers based on the generated data. Powered by LLM's generalization ability, Promptagator makes it possible to create task-specific end-to-end retrievers solely based on a few examples {without} using Natural Questions or MS MARCO to train %question generators or dual encoders. Surprisingly, LLM prompting with no more than 8 examples allows dual encoders to outperform heavily engineered models trained on MS MARCO like ColBERT v2 by more than 1.2 nDCG on average on 11 retrieval sets. Further training standard-size re-rankers using the same generated data yields another 5.0 point nDCG improvement. Our studies determine that query generation can be far more effective than previously observed, especially when a small amount of task-specific knowledge is given.
ASQA: Factoid Questions Meet Long-Form Answers
Apr 12, 2022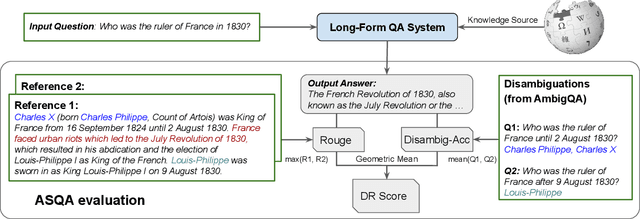

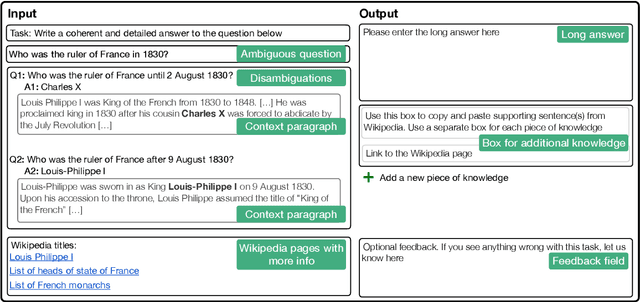
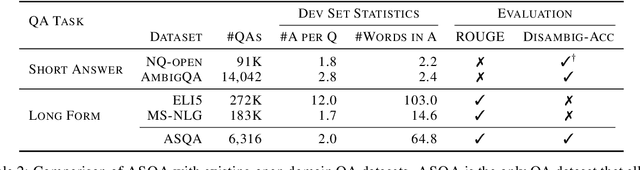
An abundance of datasets and availability of reliable evaluation metrics have resulted in strong progress in factoid question answering (QA). This progress, however, does not easily transfer to the task of long-form QA, where the goal is to answer questions that require in-depth explanations. The hurdles include (i) a lack of high-quality data, and (ii) the absence of a well-defined notion of the answer's quality. In this work, we address these problems by (i) releasing a novel dataset and a task that we call ASQA (Answer Summaries for Questions which are Ambiguous); and (ii) proposing a reliable metric for measuring performance on ASQA. Our task focuses on factoid questions that are ambiguous, that is, have different correct answers depending on interpretation. Answers to ambiguous questions should synthesize factual information from multiple sources into a long-form summary that resolves the ambiguity. In contrast to existing long-form QA tasks (such as ELI5), ASQA admits a clear notion of correctness: a user faced with a good summary should be able to answer different interpretations of the original ambiguous question. We use this notion of correctness to define an automated metric of performance for ASQA. Our analysis demonstrates an agreement between this metric and human judgments, and reveals a considerable gap between human performance and strong baselines.
FRUIT: Faithfully Reflecting Updated Information in Text
Dec 16, 2021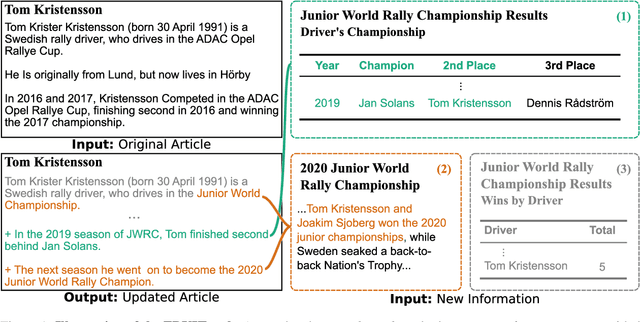
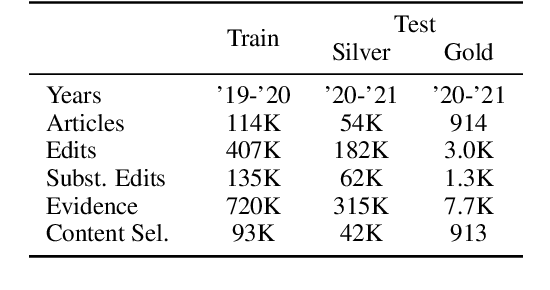
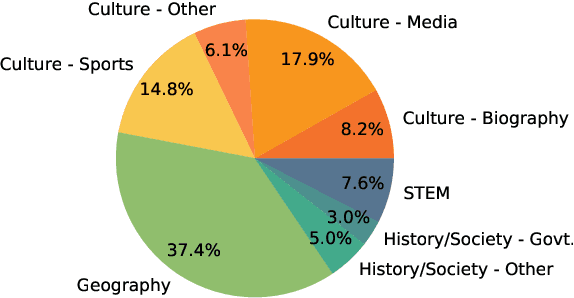

Textual knowledge bases such as Wikipedia require considerable effort to keep up to date and consistent. While automated writing assistants could potentially ease this burden, the problem of suggesting edits grounded in external knowledge has been under-explored. In this paper, we introduce the novel generation task of *faithfully reflecting updated information in text*(FRUIT) where the goal is to update an existing article given new evidence. We release the FRUIT-WIKI dataset, a collection of over 170K distantly supervised data produced from pairs of Wikipedia snapshots, along with our data generation pipeline and a gold evaluation set of 914 instances whose edits are guaranteed to be supported by the evidence. We provide benchmark results for popular generation systems as well as EDIT5 -- a T5-based approach tailored to editing we introduce that establishes the state of the art. Our analysis shows that developing models that can update articles faithfully requires new capabilities for neural generation models, and opens doors to many new applications.
Large Dual Encoders Are Generalizable Retrievers
Dec 15, 2021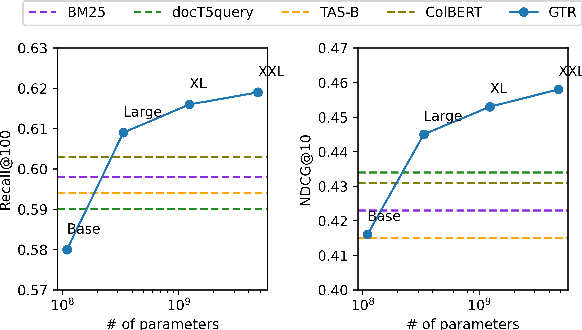
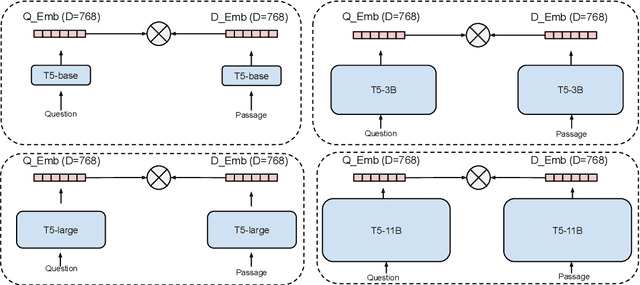

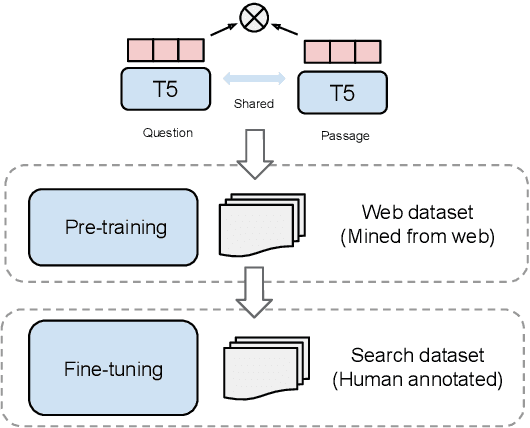
It has been shown that dual encoders trained on one domain often fail to generalize to other domains for retrieval tasks. One widespread belief is that the bottleneck layer of a dual encoder, where the final score is simply a dot-product between a query vector and a passage vector, is too limited to make dual encoders an effective retrieval model for out-of-domain generalization. In this paper, we challenge this belief by scaling up the size of the dual encoder model {\em while keeping the bottleneck embedding size fixed.} With multi-stage training, surprisingly, scaling up the model size brings significant improvement on a variety of retrieval tasks, especially for out-of-domain generalization. Experimental results show that our dual encoders, \textbf{G}eneralizable \textbf{T}5-based dense \textbf{R}etrievers (GTR), outperform %ColBERT~\cite{khattab2020colbert} and existing sparse and dense retrievers on the BEIR dataset~\cite{thakur2021beir} significantly. Most surprisingly, our ablation study finds that GTR is very data efficient, as it only needs 10\% of MS Marco supervised data to achieve the best out-of-domain performance. All the GTR models are released at https://tfhub.dev/google/collections/gtr/1.
Revisiting the Primacy of English in Zero-shot Cross-lingual Transfer
Jun 30, 2021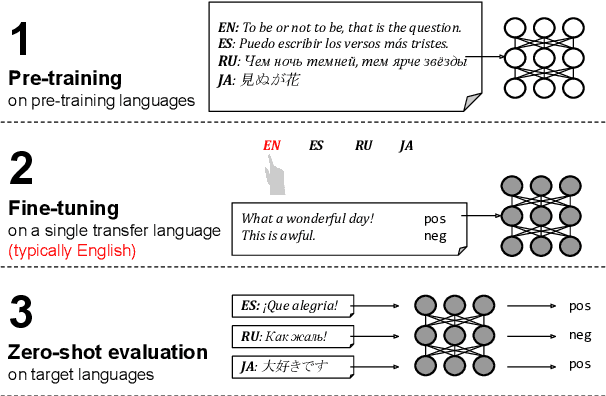
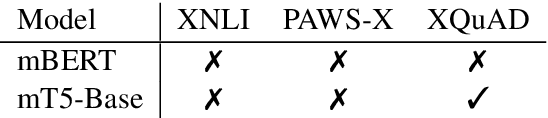
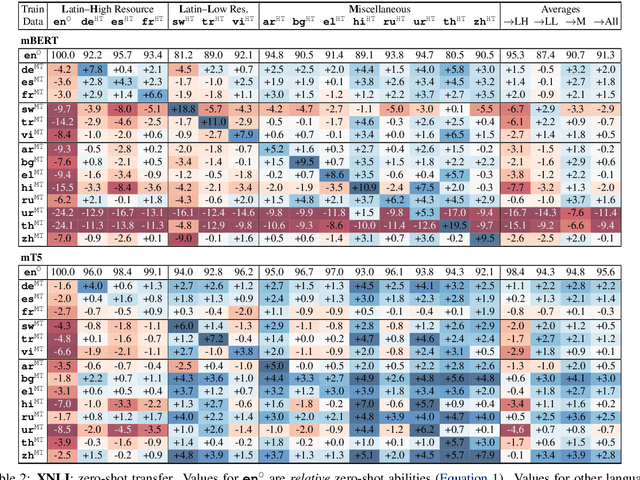
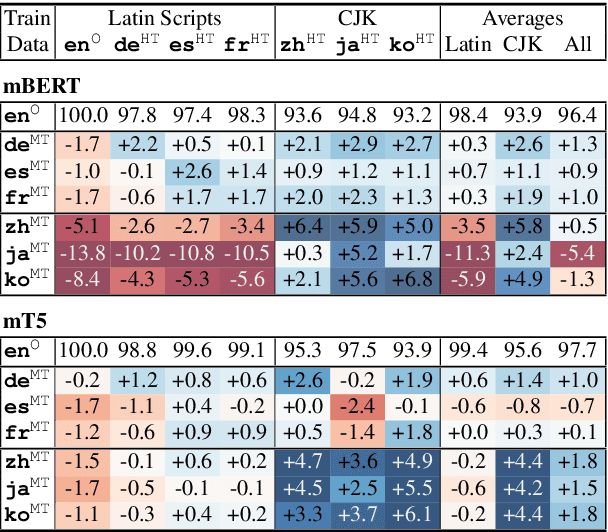
Despite their success, large pre-trained multilingual models have not completely alleviated the need for labeled data, which is cumbersome to collect for all target languages. Zero-shot cross-lingual transfer is emerging as a practical solution: pre-trained models later fine-tuned on one transfer language exhibit surprising performance when tested on many target languages. English is the dominant source language for transfer, as reinforced by popular zero-shot benchmarks. However, this default choice has not been systematically vetted. In our study, we compare English against other transfer languages for fine-tuning, on two pre-trained multilingual models (mBERT and mT5) and multiple classification and question answering tasks. We find that other high-resource languages such as German and Russian often transfer more effectively, especially when the set of target languages is diverse or unknown a priori. Unexpectedly, this can be true even when the training sets were automatically translated from English. This finding can have immediate impact on multilingual zero-shot systems, and should inform future benchmark designs.