 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 7th AI City Challenge
Apr 15, 2023



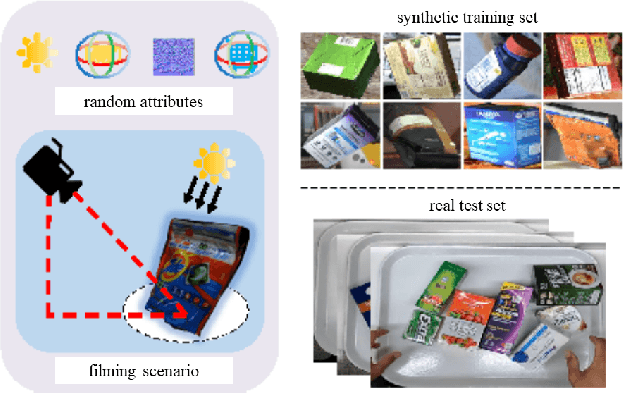
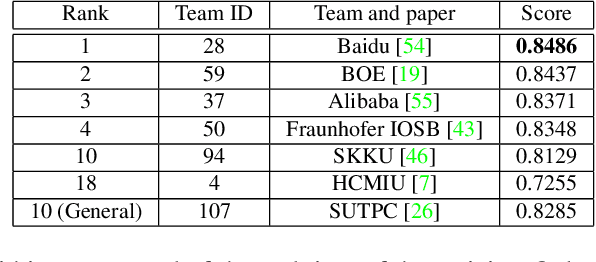
The AI City Challenge's seventh edition emphasizes two domains at the intersection of computer vision and artificial intelligence - retail business and Intelligent Traffic Systems (ITS) - that have considerable untapped potential. The 2023 challenge had five tracks, which drew a record-breaking number of participation requests from 508 teams across 46 countries. Track 1 was a brand new track that focused on multi-target multi-camera (MTMC) people tracking, where teams trained and evaluated using both real and highly realistic synthetic data. Track 2 centered around natural-language-based vehicle track retrieval. Track 3 required teams to classify driver actions in naturalistic driving analysis. Track 4 aimed to develop an automated checkout system for retail stores using a single view camera. Track 5, another new addition, tasked teams with detecting violations of the helmet rule for motorcyclists. Two leader boards were released for submissions based on different methods: a public leader board for the contest where external private data wasn't allowed and a general leader board for all results submitted. The participating teams' top performances established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.
SMILEtrack: SiMIlarity LEarning for Multiple Object Tracking
Nov 17, 2022



Multiple Object Tracking (MOT) is widely investigated in computer vision with many applications. Tracking-By-Detection (TBD) is a popular multiple-object tracking paradigm. TBD consists of the first step of object detection and the subsequent of data association, tracklet generation, and update. We propose a Similarity Learning Module (SLM) motivated from the Siamese network to extract important object appearance features and a procedure to combine object motion and appearance features effectively. This design strengthens the modeling of object motion and appearance features for data association. We design a Similarity Matching Cascade (SMC) for the data association of our SMILEtrack tracker. SMILEtrack achieves 81.06 MOTA and 80.5 IDF1 on the MOTChallenge and the MOT17 test set, respectively.
Scale-Aware Crowd Counting Using a Joint Likelihood Density Map and Synthetic Fusion Pyramid Network
Nov 13, 2022We develop a Synthetic Fusion Pyramid Network (SPF-Net) with a scale-aware loss function design for accurate crowd counting. Existing crowd-counting methods assume that the training annotation points were accurate and thus ignore the fact that noisy annotations can lead to large model-learning bias and counting error, especially for counting highly dense crowds that appear far away. To the best of our knowledge, this work is the first to properly handle such noise at multiple scales in end-to-end loss design and thus push the crowd counting state-of-the-art. We model the noise of crowd annotation points as a Gaussian and derive the crowd probability density map from the input image. We then approximate the joint distribution of crowd density maps with the full covariance of multiple scales and derive a low-rank approximation for tractability and efficient implementation. The derived scale-aware loss function is used to train the SPF-Net. We show that it outperforms various loss functions on four public datasets: UCF-QNRF, UCF CC 50, NWPU and ShanghaiTech A-B datasets. The proposed SPF-Net can accurately predict the locations of people in the crowd, despite training on noisy training annotations.
FedDig: Robust Federated Learning Using Data Digest to Represent Absent Clients
Oct 05, 2022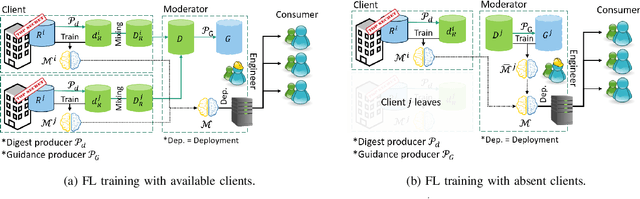
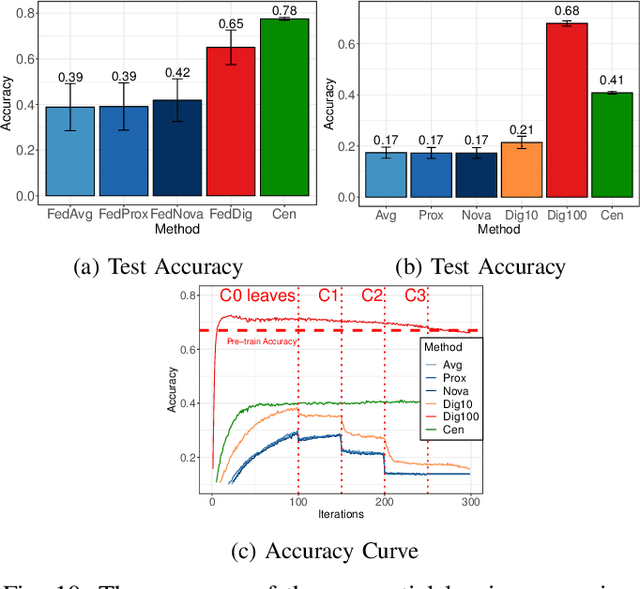
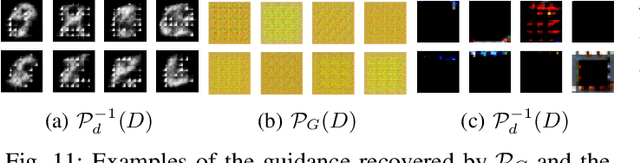
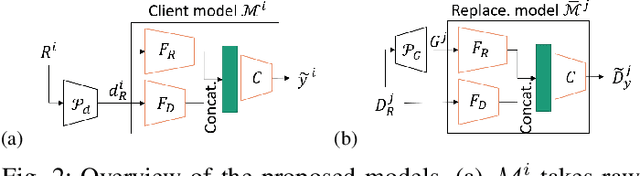
Federated Learning (FL) effectively protects client data privacy. However, client absence or leaving during training can seriously degrade model performances, particularly for unbalanced and non-IID client data. We address this issue by generating data digests from the raw data and using them to guide training at the FL moderator. The proposed FL framework, called FedDig, can tolerate unexpected client absence in cross-silo scenarios while preserving client data privacy because the digests de-identify the raw data by mixing encoded features in the features space. We evaluate FedDig using EMNIST, CIFAR-10, and CIFAR-100; the results consistently outperform against three baseline algorithms (FedAvg, FedProx, and FedNova) by large margins in various client absence scenarios.
NAS-based Recursive Stage Partial Network for Light-Weight Semantic Segmentation
Oct 03, 2022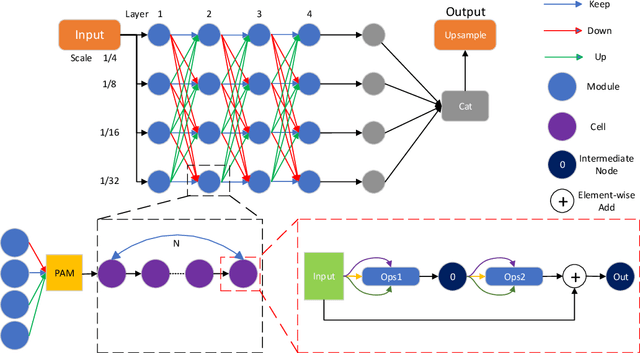

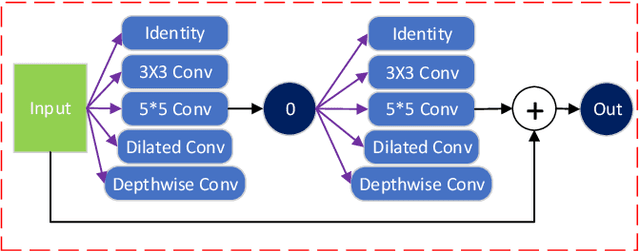
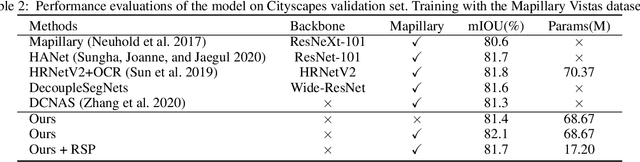
Current NAS-based semantic segmentation methods focus on accuracy improvements rather than light-weight design. In this paper, we proposed a two-stage framework to design our NAS-based RSPNet model for light-weight semantic segmentation. The first architecture search determines the inner cell structure, and the second architecture search considers exponentially growing paths to finalize the outer structure of the network. It was shown in the literature that the fusion of high- and low-resolution feature maps produces stronger representations. To find the expected macro structure without manual design, we adopt a new path-attention mechanism to efficiently search for suitable paths to fuse useful information for better segmentation. Our search for repeatable micro-structures from cells leads to a superior network architecture in semantic segmentation. In addition, we propose an RSP (recursive Stage Partial) architecture to search a light-weight design for NAS-based semantic segmentation. The proposed architecture is very efficient, simple, and effective that both the macro- and micro- structure searches can be completed in five days of computation on two V100 GPUs. The light-weight NAS architecture with only 1/4 parameter size of SoTA architectures can achieve SoTA performance on semantic segmentation on the Cityscapes dataset without using any backbones.
Class-Specific Channel Attention for Few-Shot Learning
Sep 03, 2022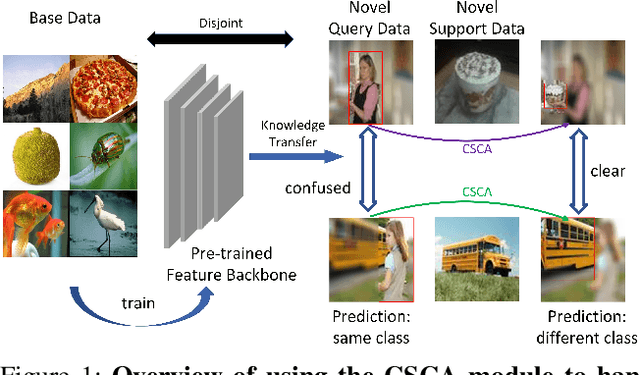
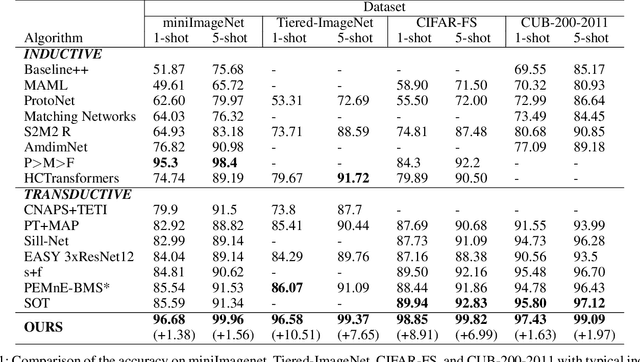
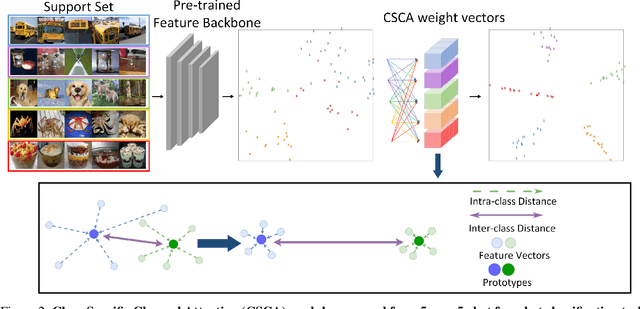
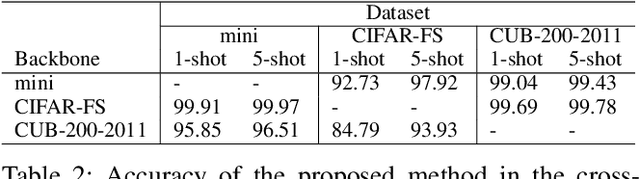
Few-Shot Learning (FSL) has attracted growing attention in computer vision due to its capability in model training without the need for excessive data. FSL is challenging because the training and testing categories (the base vs. novel sets) can be largely diversified. Conventional transfer-based solutions that aim to transfer knowledge learned from large labeled training sets to target testing sets are limited, as critical adverse impacts of the shift in task distribution are not adequately addressed. In this paper, we extend the solution of transfer-based methods by incorporating the concept of metric-learning and channel attention. To better exploit the feature representations extracted by the feature backbone, we propose Class-Specific Channel Attention (CSCA) module, which learns to highlight the discriminative channels in each class by assigning each class one CSCA weight vector. Unlike general attention modules designed to learn global-class features, the CSCA module aims to learn local and class-specific features with very effective computation. We evaluated the performance of the CSCA module on standard benchmarks including miniImagenet, Tiered-ImageNet, CIFAR-FS, and CUB-200-2011. Experiments are performed in inductive and in/cross-domain settings. We achieve new state-of-the-art results.
Open-Eye: An Open Platform to Study Human Performance on Identifying AI-Synthesized Faces
May 13, 2022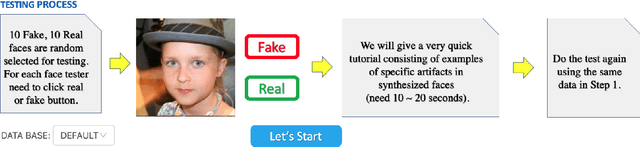


AI-synthesized faces are visually challenging to discern from real ones. They have been used as profile images for fake social media accounts, which leads to high negative social impacts. Although progress has been made in developing automatic methods to detect AI-synthesized faces, there is no open platform to study the human performance of AI-synthesized faces detection. In this work, we develop an online platform called Open-eye to study the human performance of AI-synthesized face detection. We describe the design and workflow of the Open-eye in this paper.
The 6th AI City Challenge
Apr 21, 2022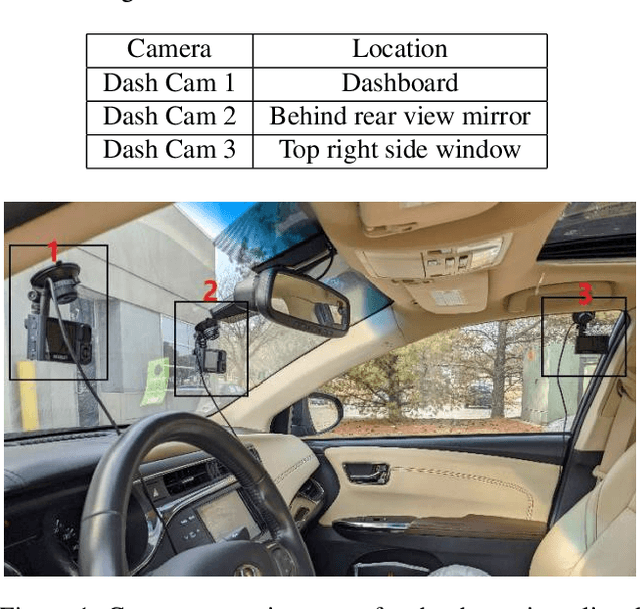
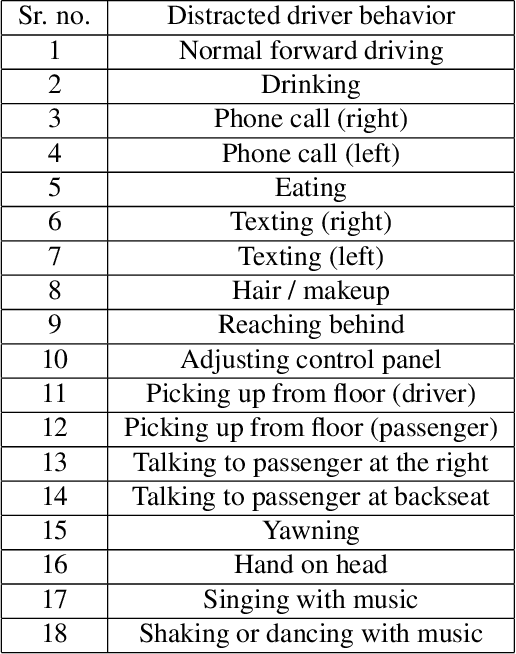
The 6th edition of the AI City Challenge specifically focuses on problems in two domains where there is tremendous unlocked potential at the intersection of computer vision and artificial intelligence: Intelligent Traffic Systems (ITS), and brick and mortar retail businesses. The four challenge tracks of the 2022 AI City Challenge received participation requests from 254 teams across 27 countries. Track 1 addressed city-scale multi-target multi-camera (MTMC) vehicle tracking. Track 2 addressed natural-language-based vehicle track retrieval. Track 3 was a brand new track for naturalistic driving analysis, where the data were captured by several cameras mounted inside the vehicle focusing on driver safety, and the task was to classify driver actions. Track 4 was another new track aiming to achieve retail store automated checkout using only a single view camera. We released two leader boards for submissions based on different methods, including a public leader board for the contest, where no use of external data is allowed, and a general leader board for all submitted results. The top performance of participating teams established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.
PseudoProp: Robust Pseudo-Label Generation for Semi-Supervised Object Detection in Autonomous Driving Systems
Mar 11, 2022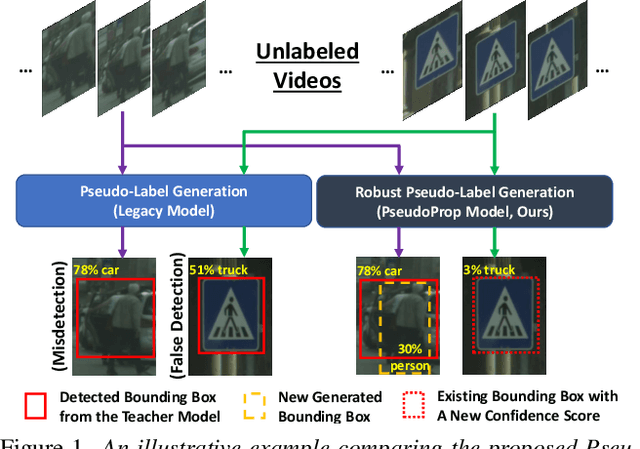
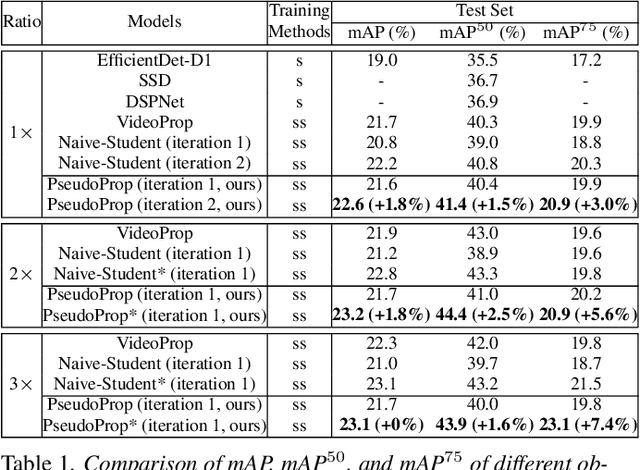
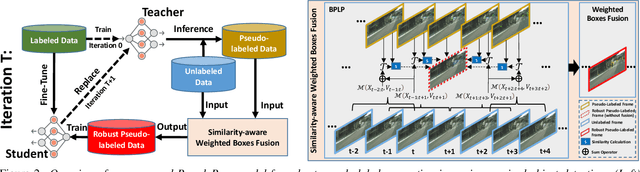
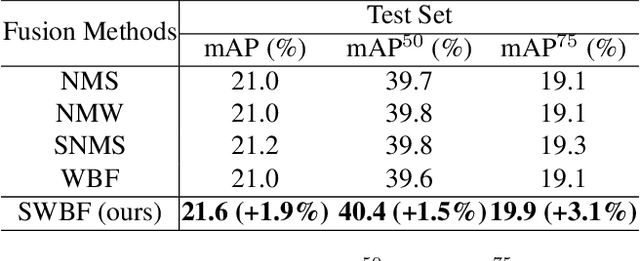
Semi-supervised object detection methods are widely used in autonomous driving systems, where only a fraction of objects are labeled. To propagate information from the labeled objects to the unlabeled ones, pseudo-labels for unlabeled objects must be generated. Although pseudo-labels have proven to improve the performance of semi-supervised object detection significantly, the applications of image-based methods to video frames result in numerous miss or false detections using such generated pseudo-labels. In this paper, we propose a new approach, PseudoProp, to generate robust pseudo-labels by leveraging motion continuity in video frames. Specifically, PseudoProp uses a novel bidirectional pseudo-label propagation approach to compensate for misdetection. A feature-based fusion technique is also used to suppress inference noise. Extensive experiments on the large-scale Cityscapes dataset demonstrate that our method outperforms the state-of-the-art semi-supervised object detection methods by 7.4% on mAP75.
GAN-generated Faces Detection: A Survey and New Perspectives
Feb 15, 2022
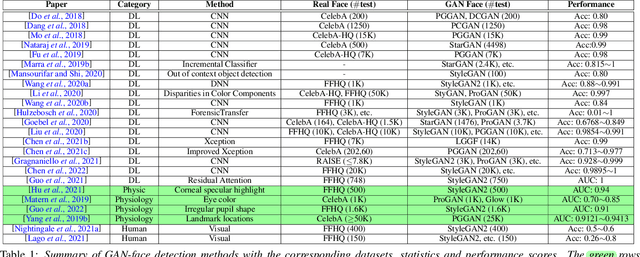
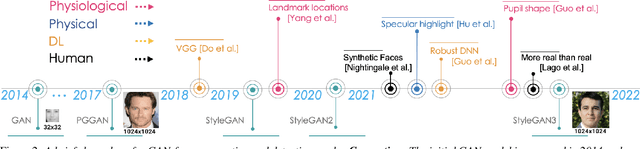
Generative Adversarial Networks (GAN) have led to the generation of very realistic face images, which have been used in fake social media accounts and other disinformation matters that can generate profound impacts. Therefore, the corresponding GAN-face detection techniques are under active development that can examine and expose such fake faces. In this work, we aim to provide a comprehensive review of recent progress in GAN-face detection. We focus on methods that can detect face images that are generated or synthesized from GAN models. We classify the existing detection works into four categories: (1) deep learning-based, (2) physical-based, (3) physiological-based methods, and (4) evaluation and comparison against human visual performance. For each category, we summarize the key ideas and connect them with method implementations. We also discuss open problems and suggest future research directions.