 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCasual as an Anchor: Resolving Supervision Misalignment in Formality Transfer Dataset
May 28, 2026Formality transfer is commonly framed as a symmetric bidirectional task between informal and formal registers. We argue that this framing conceals a supervision design flaw in existing benchmarks such as GYAFC: binary human rewrites encode relative stylistic shifts rather than absolute human notions of formality. Consequently, models learn to generate pseudo-formal outputs that satisfy benchmark labels while failing to produce genuinely formal language. We quantify this misalignment by re-evaluating benchmark formal labels under a human-aligned definition of formality, revealing substantial discrepancies that propagate to consistent informal-to-formal failures across model families. To address this issue, we reconceptualize formality transfer as a graded dimension rather than a binary attribute. We introduce a three-level spectrum: informal, casual, and formal, where casual serves as an explicit intermediate state that clarifies supervision signals. Based on this framework, we introduce 3LF, a dataset providing parallel supervision across all three levels. Training on 3LF substantially reduces informal-to-formal failures and improves alignment with human perception. For example, GPT-4.1-nano improves from 0.06 to 0.88 F1 in the informal-to- formal direction despite 3LF being significantly smaller than GYAFC. We further demonstrate that these gains cannot be reproduced through in-context learning alone and provide qualitative analyses of ambiguity-driven errors and meaning distortions. Overall, our findings demonstrate how supervision design shapes stylistic alignment and highlight the importance of alignment-aware benchmark construction in controllable text generation.
ELMoE-3D: Leveraging Intrinsic Elasticity of MoE for Hybrid-Bonding-Enabled Self-Speculative Decoding in On-Premises Serving
Apr 16, 2026Mixture-of-Experts (MoE) models have become the dominant architecture for large-scale language models, yet on-premises serving remains fundamentally memory-bound as batching turns sparse per-token compute into dense memory activation. Memory-centric architectures (PIM, NMP) improve bandwidth but leave compute underutilized under MoE's low arithmetic intensity at high batch sizes. Speculative decoding (SD) trades idle compute for fewer target invocations, yet verification must load experts even for rejected tokens, severely limiting its benefit in MoE especially at low batch sizes. We propose ELMoE-3D, a hybrid-bonding (HB)-based HW-SW co-designed framework that unifies cache-based acceleration and speculative decoding to offer overall speedup across batch sizes. We identify two intrinsic elasticity axes of MoE-expert and bit-and jointly scale them to construct Elastic Self-Speculative Decoding (Elastic-SD), which serves as both an expert cache and a strongly aligned self-draft model accelerated by high HB bandwidth. Our LSB-augmented bit-sliced architecture exploits inherent redundancy in bit-slice representations to natively support bit-nested execution. On our 3D-stacked hardware, ELMoE-3D achieves an average $6.6\times$ speedup and $4.4\times$ energy efficiency gain over naive MoE serving on xPU across batch sizes 1-16, and delivers $2.2\times$ speedup and $1.4\times$ energy efficiency gain over the best-performing prior accelerator baseline.
Erase or Hide? Suppressing Spurious Unlearning Neurons for Robust Unlearning
Sep 26, 2025



Large language models trained on web-scale data can memorize private or sensitive knowledge, raising significant privacy risks. Although some unlearning methods mitigate these risks, they remain vulnerable to "relearning" during subsequent training, allowing a substantial portion of forgotten knowledge to resurface. In this paper, we show that widely used unlearning methods cause shallow alignment: instead of faithfully erasing target knowledge, they generate spurious unlearning neurons that amplify negative influence to hide it. To overcome this limitation, we introduce Ssiuu, a new class of unlearning methods that employs attribution-guided regularization to prevent spurious negative influence and faithfully remove target knowledge. Experimental results confirm that our method reliably erases target knowledge and outperforms strong baselines across two practical retraining scenarios: (1) adversarial injection of private data, and (2) benign attack using an instruction-following benchmark. Our findings highlight the necessity of robust and faithful unlearning methods for safe deployment of language models.
Bilinear relational structure fixes reversal curse and enables consistent model editing
Sep 26, 2025The reversal curse -- a language model's (LM) inability to infer an unseen fact ``B is A'' from a learned fact ``A is B'' -- is widely considered a fundamental limitation. We show that this is not an inherent failure but an artifact of how models encode knowledge. By training LMs from scratch on a synthetic dataset of relational knowledge graphs, we demonstrate that bilinear relational structure emerges in their hidden representations. This structure substantially alleviates the reversal curse, enabling LMs to infer unseen reverse facts. Crucially, we also find that this bilinear structure plays a key role in consistent model editing. When a fact is updated in a LM with this structure, the edit correctly propagates to its reverse and other logically dependent facts. In contrast, models lacking this representation not only suffer from the reversal curse but also fail to generalize edits, further introducing logical inconsistencies. Our results establish that training on a relational knowledge dataset induces the emergence of bilinear internal representations, which in turn enable LMs to behave in a logically consistent manner after editing. This implies that the success of model editing depends critically not just on editing algorithms but on the underlying representational geometry of the knowledge being modified.
FaithUn: Toward Faithful Forgetting in Language Models by Investigating the Interconnectedness of Knowledge
Feb 26, 2025



Various studies have attempted to remove sensitive or private knowledge from a language model to prevent its unauthorized exposure. However, prior studies have overlooked the complex and interconnected nature of knowledge, where related knowledge must be carefully examined. Specifically, they have failed to evaluate whether an unlearning method faithfully erases interconnected knowledge that should be removed, retaining knowledge that appears relevant but exists in a completely different context. To resolve this problem, we first define a new concept called superficial unlearning, which refers to the phenomenon where an unlearning method either fails to erase the interconnected knowledge it should remove or unintentionally erases irrelevant knowledge. Based on the definition, we introduce a new benchmark, FaithUn, to analyze and evaluate the faithfulness of unlearning in real-world knowledge QA settings. Furthermore, we propose a novel unlearning method, KLUE, which updates only knowledge-related neurons to achieve faithful unlearning. KLUE identifies knowledge neurons using an explainability method and updates only those neurons using selected unforgotten samples. Experimental results demonstrate that widely-used unlearning methods fail to ensure faithful unlearning, while our method shows significant effectiveness in real-world QA unlearning.
Generating Diverse Hypotheses for Inductive Reasoning
Dec 18, 2024Inductive reasoning - the process of inferring general rules from a small number of observations - is a fundamental aspect of human intelligence. Recent works suggest that large language models (LLMs) can engage in inductive reasoning by sampling multiple hypotheses about the rules and selecting the one that best explains the observations. However, due to the IID sampling, semantically redundant hypotheses are frequently generated, leading to significant wastage of compute. In this paper, we 1) demonstrate that increasing the temperature to enhance the diversity is limited due to text degeneration issue, and 2) propose a novel method to improve the diversity while maintaining text quality. We first analyze the effect of increasing the temperature parameter, which is regarded as the LLM's diversity control, on IID hypotheses. Our analysis shows that as temperature rises, diversity and accuracy of hypotheses increase up to a certain point, but this trend saturates due to text degeneration. To generate hypotheses that are more semantically diverse and of higher quality, we propose a novel approach inspired by human inductive reasoning, which we call Mixture of Concepts (MoC). When applied to several inductive reasoning benchmarks, MoC demonstrated significant performance improvements compared to standard IID sampling and other approaches.
Fine-grained Gender Control in Machine Translation with Large Language Models
Jul 21, 2024



In machine translation, the problem of ambiguously gendered input has been pointed out, where the gender of an entity is not available in the source sentence. To address this ambiguity issue, the task of controlled translation that takes the gender of the ambiguous entity as additional input have been proposed. However, most existing works have only considered a simplified setup of one target gender for input. In this paper, we tackle controlled translation in a more realistic setting of inputs with multiple entities and propose Gender-of-Entity (GoE) prompting method for LLMs. Our proposed method instructs the model with fine-grained entity-level gender information to translate with correct gender inflections. By utilizing four evaluation benchmarks, we investigate the controlled translation capability of LLMs in multiple dimensions and find that LLMs reach state-of-the-art performance in controlled translation. Furthermore, we discover an emergence of gender interference phenomenon when controlling the gender of multiple entities. Finally, we address the limitations of existing gender accuracy evaluation metrics and propose leveraging LLMs as an evaluator for gender inflection in machine translation.
VLind-Bench: Measuring Language Priors in Large Vision-Language Models
Jun 17, 2024Large Vision-Language Models (LVLMs) have demonstrated outstanding performance across various multimodal tasks. However, they suffer from a problem known as language prior, where responses are generated based solely on textual patterns while disregarding image information. Addressing the issue of language prior is crucial, as it can lead to undesirable biases or hallucinations when dealing with images that are out of training distribution. Despite its importance, current methods for accurately measuring language priors in LVLMs are poorly studied. Although existing benchmarks based on counterfactual or out-of-distribution images can partially be used to measure language priors, they fail to disentangle language priors from other confounding factors. To this end, we propose a new benchmark called VLind-Bench, which is the first benchmark specifically designed to measure the language priors, or blindness, of LVLMs. It not only includes tests on counterfactual images to assess language priors but also involves a series of tests to evaluate more basic capabilities such as commonsense knowledge, visual perception, and commonsense biases. For each instance in our benchmark, we ensure that all these basic tests are passed before evaluating the language priors, thereby minimizing the influence of other factors on the assessment. The evaluation and analysis of recent LVLMs in our benchmark reveal that almost all models exhibit a significant reliance on language priors, presenting a strong challenge in the field.
Target-Agnostic Gender-Aware Contrastive Learning for Mitigating Bias in Multilingual Machine Translation
May 23, 2023



Gender bias is a significant issue in machine translation, leading to ongoing research efforts in developing bias mitigation techniques. However, most works focus on debiasing of bilingual models without consideration for multilingual systems. In this paper, we specifically target the unambiguous gender bias issue of multilingual machine translation models and propose a new mitigation method based on a novel perspective on the problem. We hypothesize that the gender bias in unambiguous settings is due to the lack of gender information encoded into the non-explicit gender words and devise a scheme to encode correct gender information into their latent embeddings. Specifically, we employ Gender-Aware Contrastive Learning, GACL, based on gender pseudo-labels to encode gender information on the encoder embeddings. Our method is target-language-agnostic and applicable to already trained multilingual machine translation models through post-fine-tuning. Through multilingual evaluation, we show that our approach improves gender accuracy by a wide margin without hampering translation performance. We also observe that incorporated gender information transfers and benefits other target languages regarding gender accuracy. Finally, we demonstrate that our method is applicable and beneficial to models of various sizes.
Bag of Tricks for Developing Diabetic Retinopathy Analysis Framework to Overcome Data Scarcity
Oct 18, 2022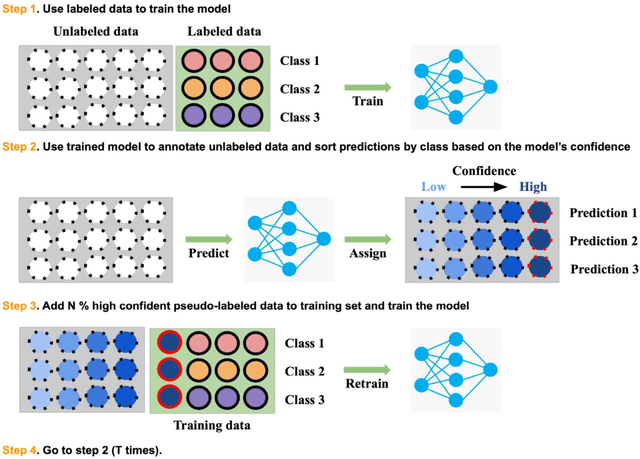
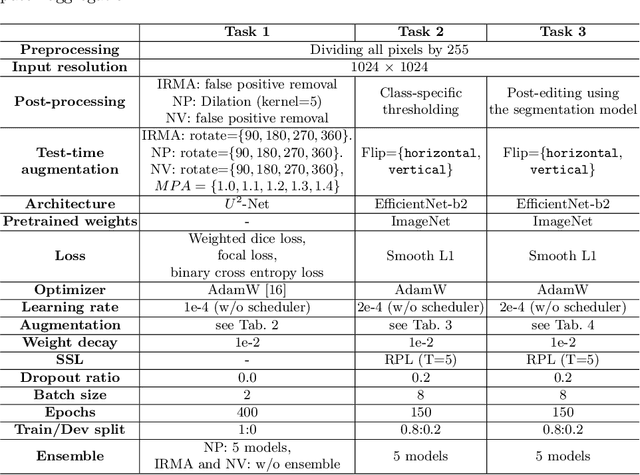


Recently, diabetic retinopathy (DR) screening utilizing ultra-wide optical coherence tomography angiography (UW-OCTA) has been used in clinical practices to detect signs of early DR. However, developing a deep learning-based DR analysis system using UW-OCTA images is not trivial due to the difficulty of data collection and the absence of public datasets. By realistic constraints, a model trained on small datasets may obtain sub-par performance. Therefore, to help ophthalmologists be less confused about models' incorrect decisions, the models should be robust even in data scarcity settings. To address the above practical challenging, we present a comprehensive empirical study for DR analysis tasks, including lesion segmentation, image quality assessment, and DR grading. For each task, we introduce a robust training scheme by leveraging ensemble learning, data augmentation, and semi-supervised learning. Furthermore, we propose reliable pseudo labeling that excludes uncertain pseudo-labels based on the model's confidence scores to reduce the negative effect of noisy pseudo-labels. By exploiting the proposed approaches, we achieved 1st place in the Diabetic Retinopathy Analysis Challenge.