 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovieCORE: COgnitive REasoning in Movies
Aug 26, 2025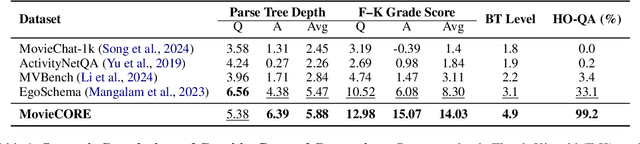
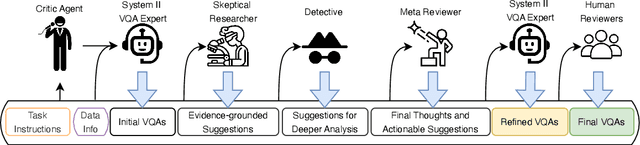
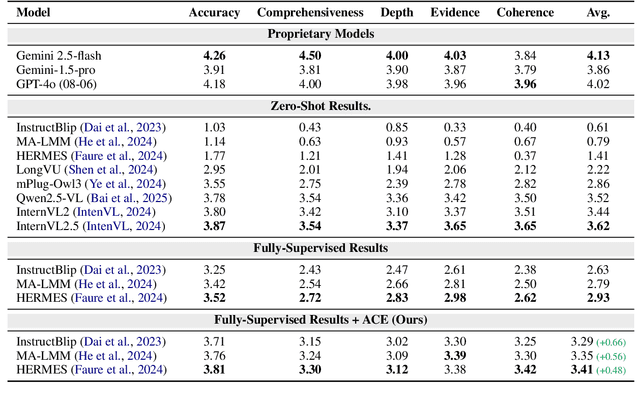

This paper introduces MovieCORE, a novel video question answering (VQA) dataset designed to probe deeper cognitive understanding of movie content. Unlike existing datasets that focus on surface-level comprehension, MovieCORE emphasizes questions that engage System-2 thinking while remaining specific to the video material. We present an innovative agentic brainstorming approach, utilizing multiple large language models (LLMs) as thought agents to generate and refine high-quality question-answer pairs. To evaluate dataset quality, we develop a set of cognitive tests assessing depth, thought-provocation potential, and syntactic complexity. We also propose a comprehensive evaluation scheme for assessing VQA model performance on deeper cognitive tasks. To address the limitations of existing video-language models (VLMs), we introduce an agentic enhancement module, Agentic Choice Enhancement (ACE), which improves model reasoning capabilities post-training by up to 25%. Our work contributes to advancing movie understanding in AI systems and provides valuable insights into the capabilities and limitations of current VQA models when faced with more challenging, nuanced questions about cinematic content. Our project page, dataset and code can be found at https://joslefaure.github.io/assets/html/moviecore.html.
Autoregressive Universal Video Segmentation Model
Aug 26, 2025



Recent video foundation models such as SAM2 excel at prompted video segmentation by treating masks as a general-purpose primitive. However, many real-world settings require unprompted segmentation that aims to detect and track all objects in a video without external cues, leaving today's landscape fragmented across task-specific models and pipelines. We recast streaming video segmentation as sequential mask prediction, analogous to language modeling, and introduce the Autoregressive Universal Segmentation Model (AUSM), a single architecture that unifies both prompted and unprompted video segmentation. Built on recent state-space models, AUSM maintains a fixed-size spatial state and scales to video streams of arbitrary length. Furthermore, all components of AUSM are designed for parallel training across frames, yielding substantial speedups over iterative training. On standard benchmarks (DAVIS17, YouTube-VOS 2018 & 2019, MOSE, YouTube-VIS 2019 & 2021, and OVIS) AUSM outperforms prior universal streaming video segmentation methods and achieves up to 2.5x faster training on 16-frame sequences.
LongSplat: Robust Unposed 3D Gaussian Splatting for Casual Long Videos
Aug 19, 2025



LongSplat addresses critical challenges in novel view synthesis (NVS) from casually captured long videos characterized by irregular camera motion, unknown camera poses, and expansive scenes. Current methods often suffer from pose drift, inaccurate geometry initialization, and severe memory limitations. To address these issues, we introduce LongSplat, a robust unposed 3D Gaussian Splatting framework featuring: (1) Incremental Joint Optimization that concurrently optimizes camera poses and 3D Gaussians to avoid local minima and ensure global consistency; (2) a robust Pose Estimation Module leveraging learned 3D priors; and (3) an efficient Octree Anchor Formation mechanism that converts dense point clouds into anchors based on spatial density. Extensive experiments on challenging benchmarks demonstrate that LongSplat achieves state-of-the-art results, substantially improving rendering quality, pose accuracy, and computational efficiency compared to prior approaches. Project page: https://linjohnss.github.io/longsplat/
ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning
Jul 22, 2025



Vision-language-action (VLA) reasoning tasks require agents to interpret multimodal instructions, perform long-horizon planning, and act adaptively in dynamic environments. Existing approaches typically train VLA models in an end-to-end fashion, directly mapping inputs to actions without explicit reasoning, which hinders their ability to plan over multiple steps or adapt to complex task variations. In this paper, we propose ThinkAct, a dual-system framework that bridges high-level reasoning with low-level action execution via reinforced visual latent planning. ThinkAct trains a multimodal LLM to generate embodied reasoning plans guided by reinforcing action-aligned visual rewards based on goal completion and trajectory consistency. These reasoning plans are compressed into a visual plan latent that conditions a downstream action model for robust action execution on target environments. Extensive experiments on embodied reasoning and robot manipulation benchmarks demonstrate that ThinkAct enables few-shot adaptation, long-horizon planning, and self-correction behaviors in complex embodied AI tasks.
AuraFusion360: Augmented Unseen Region Alignment for Reference-based 360° Unbounded Scene Inpainting
Feb 07, 2025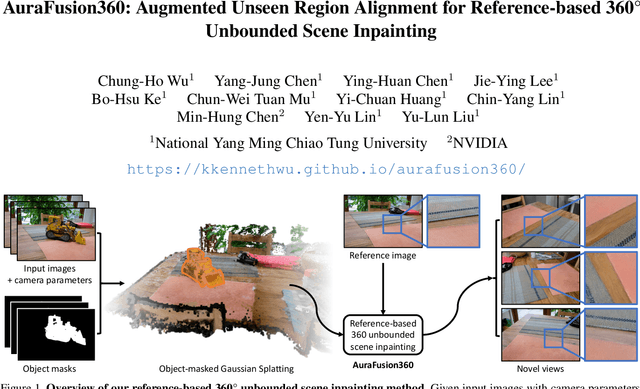
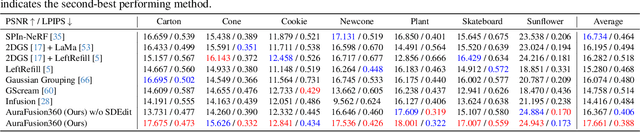

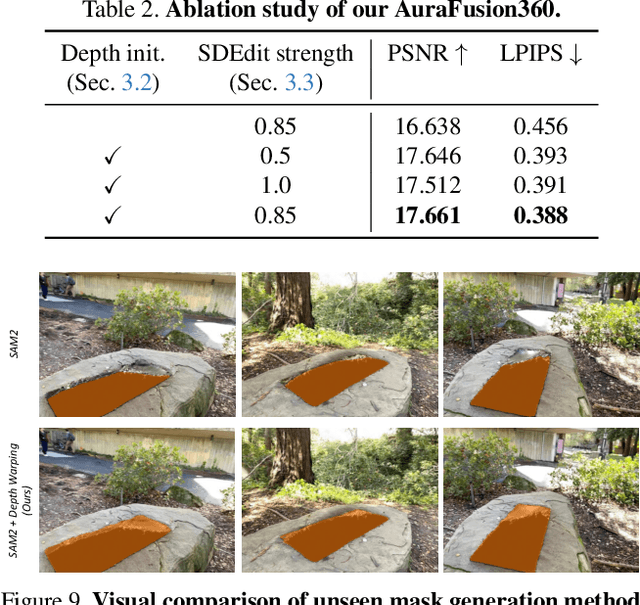
Three-dimensional scene inpainting is crucial for applications from virtual reality to architectural visualization, yet existing methods struggle with view consistency and geometric accuracy in 360{\deg} unbounded scenes. We present AuraFusion360, a novel reference-based method that enables high-quality object removal and hole filling in 3D scenes represented by Gaussian Splatting. Our approach introduces (1) depth-aware unseen mask generation for accurate occlusion identification, (2) Adaptive Guided Depth Diffusion, a zero-shot method for accurate initial point placement without requiring additional training, and (3) SDEdit-based detail enhancement for multi-view coherence. We also introduce 360-USID, the first comprehensive dataset for 360{\deg} unbounded scene inpainting with ground truth. Extensive experiments demonstrate that AuraFusion360 significantly outperforms existing methods, achieving superior perceptual quality while maintaining geometric accuracy across dramatic viewpoint changes. See our project page for video results and the dataset at https://kkennethwu.github.io/aurafusion360/.
Omni-RGPT: Unifying Image and Video Region-level Understanding via Token Marks
Jan 14, 2025We present Omni-RGPT, a multimodal large language model designed to facilitate region-level comprehension for both images and videos. To achieve consistent region representation across spatio-temporal dimensions, we introduce Token Mark, a set of tokens highlighting the target regions within the visual feature space. These tokens are directly embedded into spatial regions using region prompts (e.g., boxes or masks) and simultaneously incorporated into the text prompt to specify the target, establishing a direct connection between visual and text tokens. To further support robust video understanding without requiring tracklets, we introduce an auxiliary task that guides Token Mark by leveraging the consistency of the tokens, enabling stable region interpretation across the video. Additionally, we introduce a large-scale region-level video instruction dataset (RegVID-300k). Omni-RGPT achieves state-of-the-art results on image and video-based commonsense reasoning benchmarks while showing strong performance in captioning and referring expression comprehension tasks.
CorrFill: Enhancing Faithfulness in Reference-based Inpainting with Correspondence Guidance in Diffusion Models
Jan 04, 2025In the task of reference-based image inpainting, an additional reference image is provided to restore a damaged target image to its original state. The advancement of diffusion models, particularly Stable Diffusion, allows for simple formulations in this task. However, existing diffusion-based methods often lack explicit constraints on the correlation between the reference and damaged images, resulting in lower faithfulness to the reference images in the inpainting results. In this work, we propose CorrFill, a training-free module designed to enhance the awareness of geometric correlations between the reference and target images. This enhancement is achieved by guiding the inpainting process with correspondence constraints estimated during inpainting, utilizing attention masking in self-attention layers and an objective function to update the input tensor according to the constraints. Experimental results demonstrate that CorrFill significantly enhances the performance of multiple baseline diffusion-based methods, including state-of-the-art approaches, by emphasizing faithfulness to the reference images.
ORFormer: Occlusion-Robust Transformer for Accurate Facial Landmark Detection
Dec 17, 2024



Although facial landmark detection (FLD) has gained significant progress, existing FLD methods still suffer from performance drops on partially non-visible faces, such as faces with occlusions or under extreme lighting conditions or poses. To address this issue, we introduce ORFormer, a novel transformer-based method that can detect non-visible regions and recover their missing features from visible parts. Specifically, ORFormer associates each image patch token with one additional learnable token called the messenger token. The messenger token aggregates features from all but its patch. This way, the consensus between a patch and other patches can be assessed by referring to the similarity between its regular and messenger embeddings, enabling non-visible region identification. Our method then recovers occluded patches with features aggregated by the messenger tokens. Leveraging the recovered features, ORFormer compiles high-quality heatmaps for the downstream FLD task. Extensive experiments show that our method generates heatmaps resilient to partial occlusions. By integrating the resultant heatmaps into existing FLD methods, our method performs favorably against the state of the arts on challenging datasets such as WFLW and COFW.
Hymba: A Hybrid-head Architecture for Small Language Models
Nov 20, 2024



We propose Hymba, a family of small language models featuring a hybrid-head parallel architecture that integrates transformer attention mechanisms with state space models (SSMs) for enhanced efficiency. Attention heads provide high-resolution recall, while SSM heads enable efficient context summarization. Additionally, we introduce learnable meta tokens that are prepended to prompts, storing critical information and alleviating the "forced-to-attend" burden associated with attention mechanisms. This model is further optimized by incorporating cross-layer key-value (KV) sharing and partial sliding window attention, resulting in a compact cache size. During development, we conducted a controlled study comparing various architectures under identical settings and observed significant advantages of our proposed architecture. Notably, Hymba achieves state-of-the-art results for small LMs: Our Hymba-1.5B-Base model surpasses all sub-2B public models in performance and even outperforms Llama-3.2-3B with 1.32% higher average accuracy, an 11.67x cache size reduction, and 3.49x throughput.
EoRA: Training-free Compensation for Compressed LLM with Eigenspace Low-Rank Approximation
Oct 28, 2024In this work, we re-formulate the model compression problem into the customized compensation problem: Given a compressed model, we aim to introduce residual low-rank paths to compensate for compression errors under customized requirements from users (e.g., tasks, compression ratios), resulting in greater flexibility in adjusting overall capacity without being constrained by specific compression formats. However, naively applying SVD to derive residual paths causes suboptimal utilization of the low-rank representation capacity. Instead, we propose Training-free Eigenspace Low-Rank Approximation (EoRA), a method that directly minimizes compression-induced errors without requiring gradient-based training, achieving fast optimization in minutes using a small amount of calibration data. EoRA projects compression errors into the eigenspace of input activations, leveraging eigenvalues to effectively prioritize the reconstruction of high-importance error components. Moreover, EoRA can be seamlessly integrated with fine-tuning and quantization to further improve effectiveness and efficiency. EoRA consistently outperforms previous methods in compensating errors for compressed LLaMA2/3 models on various tasks, such as language generation, commonsense reasoning, and math reasoning tasks (e.g., 31.31%/12.88% and 9.69% improvements on ARC-Easy/ARC-Challenge and MathQA when compensating LLaMA3-8B that is quantized to 4-bit and pruned to 2:4 sparsity). EoRA offers a scalable, training-free solution to compensate for compression errors, making it a powerful tool to deploy LLMs in various capacity and efficiency requirements.