 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep End-to-end Causal Inference
Feb 04, 2022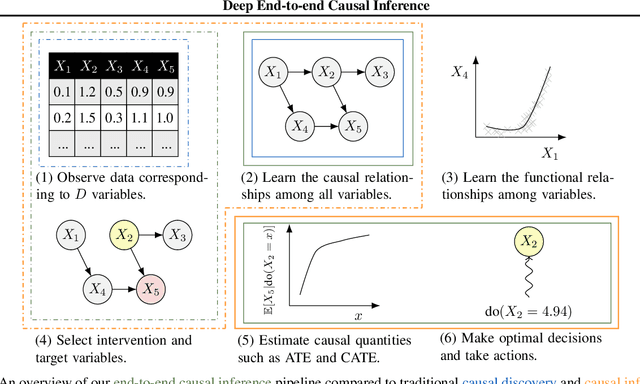
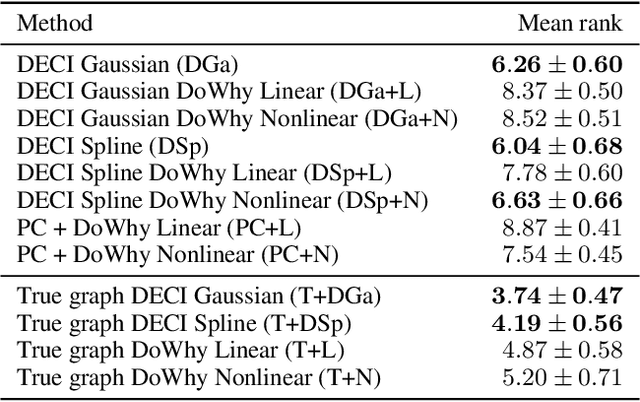
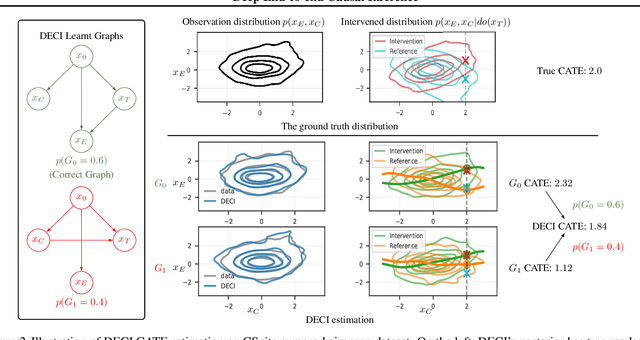
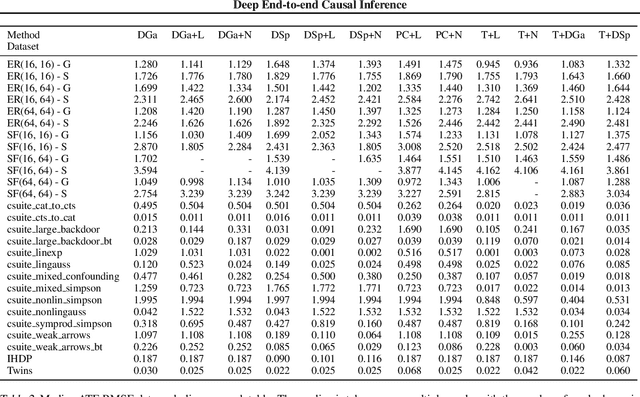
Causal inference is essential for data-driven decision making across domains such as business engagement, medical treatment or policy making. However, research on causal discovery and inference has evolved separately, and the combination of the two domains is not trivial. In this work, we develop Deep End-to-end Causal Inference (DECI), a single flow-based method that takes in observational data and can perform both causal discovery and inference, including conditional average treatment effect (CATE) estimation. We provide a theoretical guarantee that DECI can recover the ground truth causal graph under mild assumptions. In addition, our method can handle heterogeneous, real-world, mixed-type data with missing values, allowing for both continuous and discrete treatment decisions. Moreover, the design principle of our method can generalize beyond DECI, providing a general End-to-end Causal Inference (ECI) recipe, which enables different ECI frameworks to be built using existing methods. Our results show the superior performance of DECI when compared to relevant baselines for both causal discovery and (C)ATE estimation in over a thousand experiments on both synthetic datasets and other causal machine learning benchmark datasets.
HEAT: Hyperedge Attention Networks
Jan 28, 2022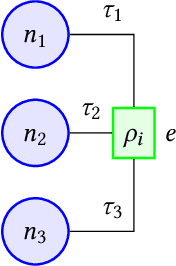
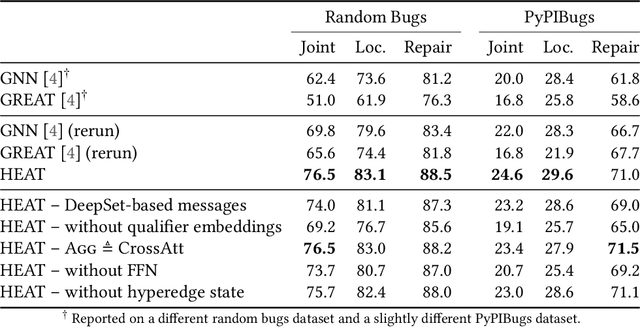
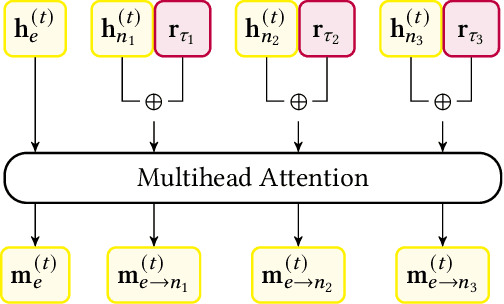

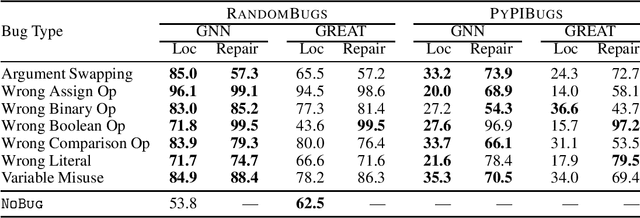
Learning from structured data is a core machine learning task. Commonly, such data is represented as graphs, which normally only consider (typed) binary relationships between pairs of nodes. This is a substantial limitation for many domains with highly-structured data. One important such domain is source code, where hypergraph-based representations can better capture the semantically rich and structured nature of code. In this work, we present HEAT, a neural model capable of representing typed and qualified hypergraphs, where each hyperedge explicitly qualifies how participating nodes contribute. It can be viewed as a generalization of both message passing neural networks and Transformers. We evaluate HEAT on knowledge base completion and on bug detection and repair using a novel hypergraph representation of programs. In both settings, it outperforms strong baselines, indicating its power and generality.
VICause: Simultaneous Missing Value Imputation and Causal Discovery with Groups
Oct 15, 2021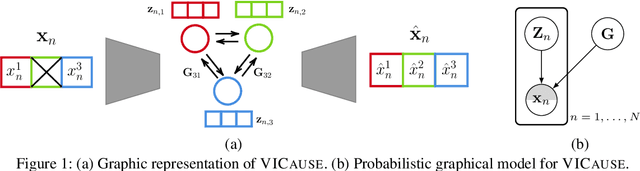
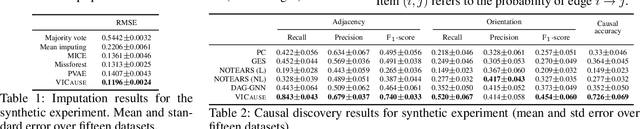
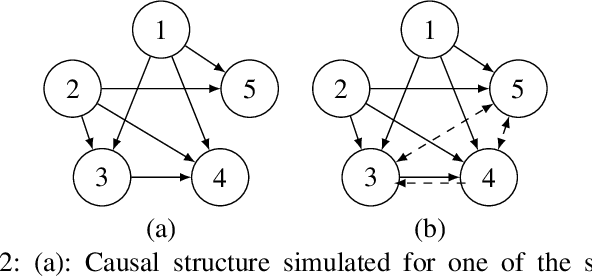
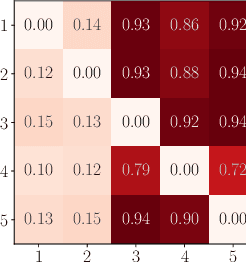
Missing values constitute an important challenge in real-world machine learning for both prediction and causal discovery tasks. However, existing imputation methods are agnostic to causality, while only few methods in traditional causal discovery can handle missing data in an efficient way. In this work we propose VICause, a novel approach to simultaneously tackle missing value imputation and causal discovery efficiently with deep learning. Particularly, we propose a generative model with a structured latent space and a graph neural network-based architecture, scaling to large number of variables. Moreover, our method can discover relationships between groups of variables which is useful in many real-world applications. VICause shows improved performance compared to popular and recent approaches in both missing value imputation and causal discovery.
CoRGi: Content-Rich Graph Neural Networks with Attention
Oct 10, 2021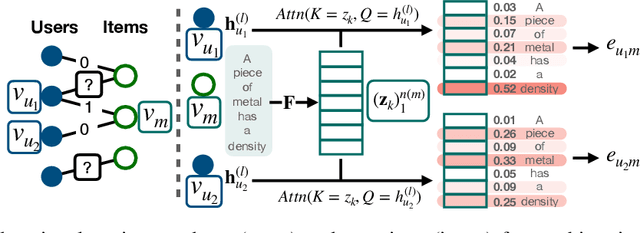

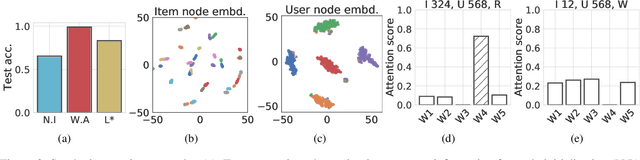
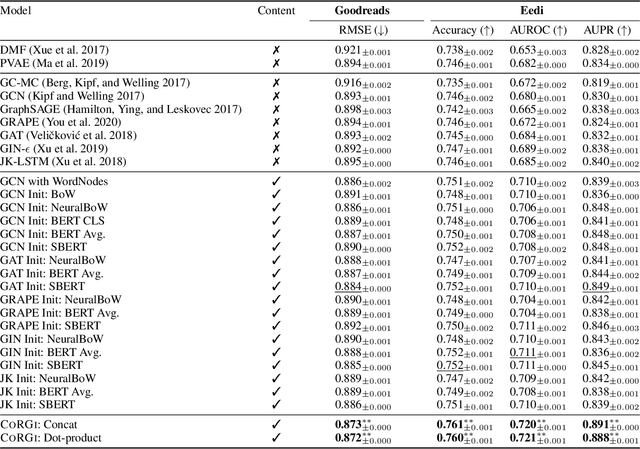
Graph representations of a target domain often project it to a set of entities (nodes) and their relations (edges). However, such projections often miss important and rich information. For example, in graph representations used in missing value imputation, items - represented as nodes - may contain rich textual information. However, when processing graphs with graph neural networks (GNN), such information is either ignored or summarized into a single vector representation used to initialize the GNN. Towards addressing this, we present CoRGi, a GNN that considers the rich data within nodes in the context of their neighbors. This is achieved by endowing CoRGi's message passing with a personalized attention mechanism over the content of each node. This way, CoRGi assigns user-item-specific attention scores with respect to the words that appear in an item's content. We evaluate CoRGi on two edge-value prediction tasks and show that CoRGi is better at making edge-value predictions over existing methods, especially on sparse regions of the graph.
Learning to Generate Code Sketches
Jun 18, 2021

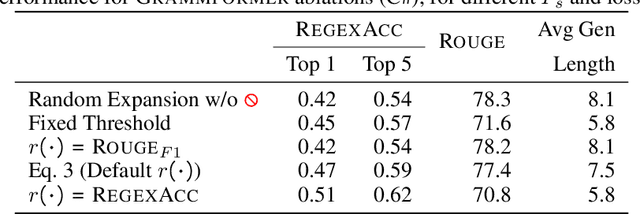
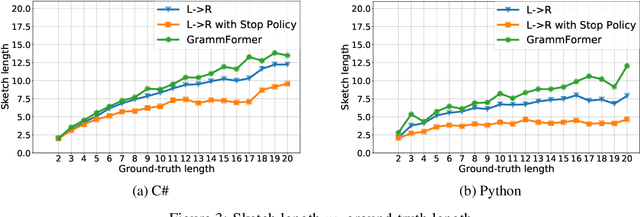
Traditional generative models are limited to predicting sequences of terminal tokens. However, ambiguities in the generation task may lead to incorrect outputs. Towards addressing this, we introduce Grammformers, transformer-based grammar-guided models that learn (without explicit supervision) to generate sketches -- sequences of tokens with holes. Through reinforcement learning, Grammformers learn to introduce holes avoiding the generation of incorrect tokens where there is ambiguity in the target task. We train Grammformers for statement-level source code completion, i.e., the generation of code snippets given an ambiguous user intent, such as a partial code context. We evaluate Grammformers on code completion for C# and Python and show that it generates 10-50% more accurate sketches compared to traditional generative models and 37-50% longer sketches compared to sketch-generating baselines trained with similar techniques.
Self-Supervised Bug Detection and Repair
May 26, 2021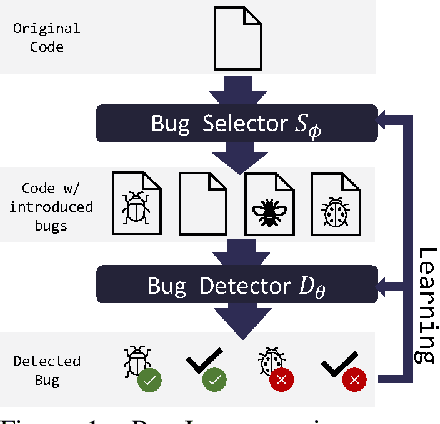


Machine learning-based program analyses have recently shown the promise of integrating formal and probabilistic reasoning towards aiding software development. However, in the absence of large annotated corpora, training these analyses is challenging. Towards addressing this, we present BugLab, an approach for self-supervised learning of bug detection and repair. BugLab co-trains two models: (1) a detector model that learns to detect and repair bugs in code, (2) a selector model that learns to create buggy code for the detector to use as training data. A Python implementation of BugLab improves by up to 30% upon baseline methods on a test dataset of 2374 real-life bugs and finds 19 previously unknown bugs in open-source software.
Copy that! Editing Sequences by Copying Spans
Jun 08, 2020

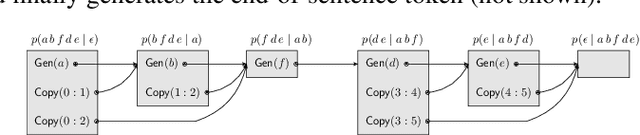
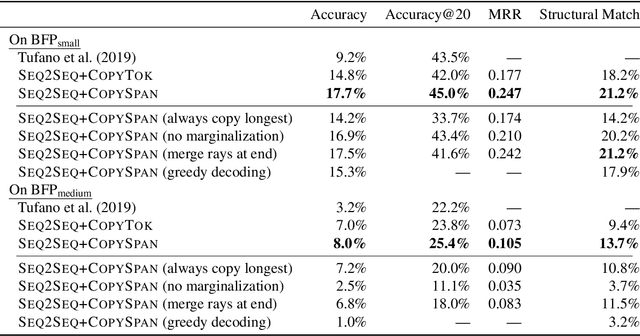
Neural sequence-to-sequence models are finding increasing use in editing of documents, for example in correcting a text document or repairing source code. In this paper, we argue that common seq2seq models (with a facility to copy single tokens) are not a natural fit for such tasks, as they have to explicitly copy each unchanged token. We present an extension of seq2seq models capable of copying entire spans of the input to the output in one step, greatly reducing the number of decisions required during inference. This extension means that there are now many ways of generating the same output, which we handle by deriving a new objective for training and a variation of beam search for inference that explicitly handle this problem. In our experiments on a range of editing tasks of natural language and source code, we show that our new model consistently outperforms simpler baselines.
Fast and Memory-Efficient Neural Code Completion
Apr 29, 2020


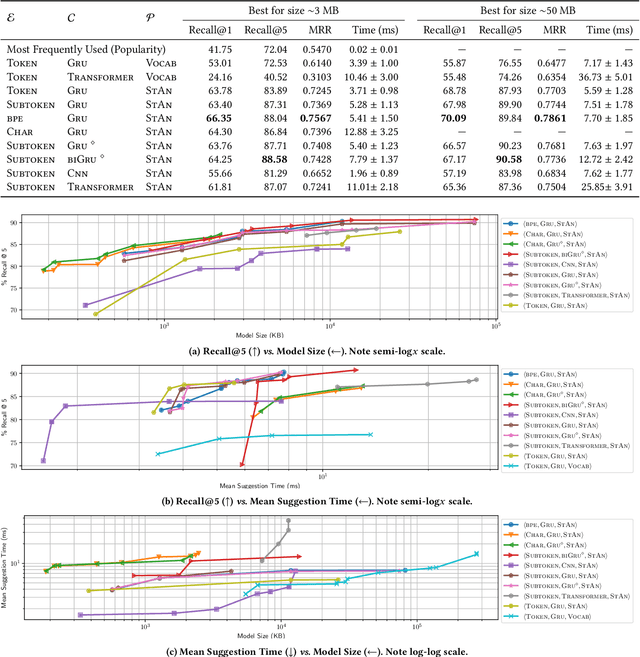
Code completion is one of the most widely used features of modern integrated development environments (IDEs). Deep learning has recently made significant progress in the statistical prediction of source code. However, state-of-the-art neural network models consume prohibitively large amounts of memory, causing computational burden to the development environment, especially when deployed in lightweight client devices. In this work, we reframe neural code completion from a generation task to a task of learning to rank the valid completion suggestions computed from static analyses. By doing so, we are able to design and test a variety of deep neural network model configurations. One of our best models consumes 6 MB of RAM, computes a single suggestion in 8 ms, and achieves 90% recall in its top five suggestions. Our models outperform standard language modeling code completion techniques in terms of predictive performance, computational speed, and memory efficiency. Furthermore, they learn about code semantics from the natural language aspects of the code (e.g. identifier names) and can generalize better to previously unseen code.
Typilus: Neural Type Hints
Apr 06, 2020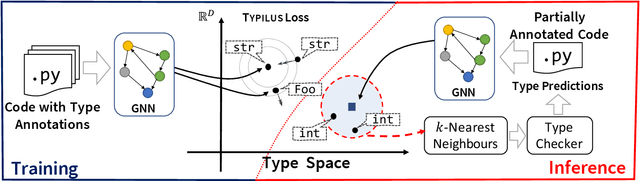

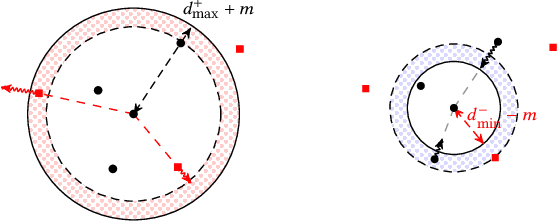
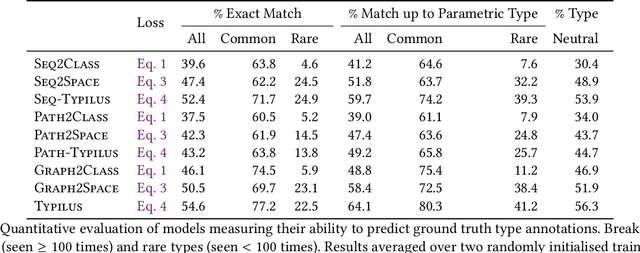
Type inference over partial contexts in dynamically typed languages is challenging. In this work, we present a graph neural network model that predicts types by probabilistically reasoning over a program's structure, names, and patterns. The network uses deep similarity learning to learn a TypeSpace -- a continuous relaxation of the discrete space of types -- and how to embed the type properties of a symbol (i.e. identifier) into it. Importantly, our model can employ one-shot learning to predict an open vocabulary of types, including rare and user-defined ones. We realise our approach in Typilus for Python that combines the TypeSpace with an optional type checker. We show that Typilus accurately predicts types. Typilus confidently predicts types for 70% of all annotatable symbols; when it predicts a type, that type optionally type checks 95% of the time. Typilus can also find incorrect type annotations; two important and popular open source libraries, fairseq and allennlp, accepted our pull requests that fixed the annotation errors Typilus discovered.
Learning to Encode and Classify Test Executions
Jan 08, 2020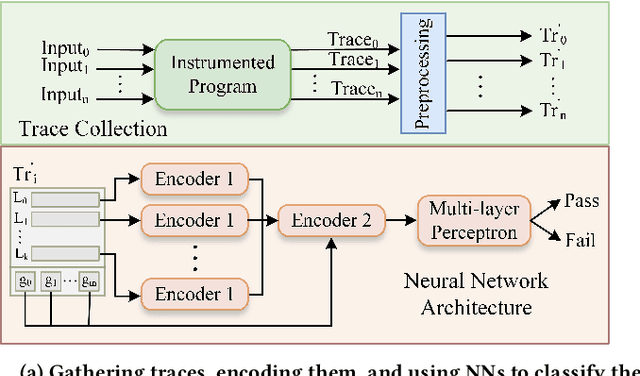
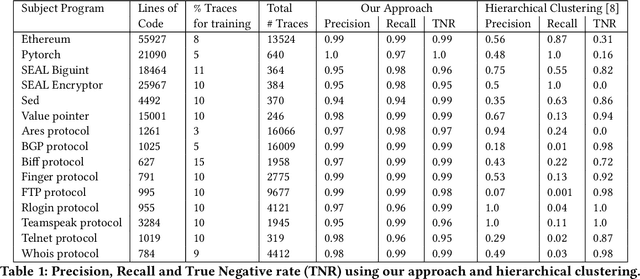
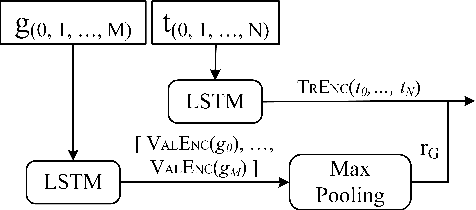
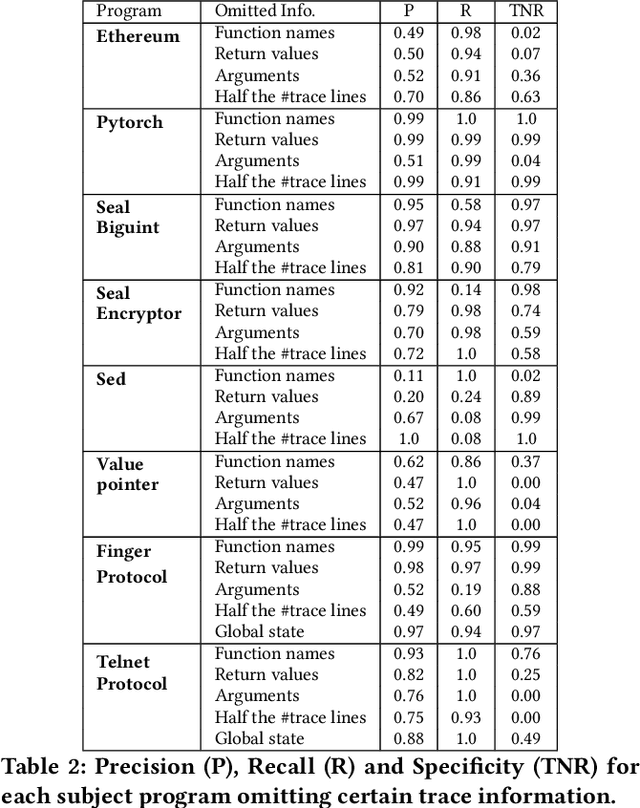
The challenge of automatically determining the correctness of test executions is referred to as the test oracle problem and is one of the key remaining issues for automated testing. The goal in this paper is to solve the test oracle problem in a way that is general, scalable and accurate. To achieve this, we use supervised learning over test execution traces. We label a small fraction of the execution traces with their verdict of pass or fail. We use the labelled traces to train a neural network (NN) model to learn to distinguish runtime patterns for passing versus failing executions for a given program. Our approach for building this NN model involves the following steps, 1. Instrument the program to record execution traces as sequences of method invocations and global state, 2. Label a small fraction of the execution traces with their verdicts, 3. Designing a NN component that embeds information in execution traces to fixed length vectors, 4. Design a NN model that uses the trace information for classification, 5. Evaluate the inferred classification model on unseen execution traces from the program. We evaluate our approach using case studies from different application domains: 1. Module from Ethereum Blockchain, 2. Module from PyTorch deep learning framework, 3. Microsoft SEAL encryption library components, 4. Sed stream editor, 5. Value pointer library and 6. Nine network protocols from Linux packet identifier, L7-Filter. We found the classification models for all subject programs resulted in high precision, recall and specificity, over 95%, while only training with an average 9% of the total traces. Our experiments show that the proposed neural network model is highly effective as a test oracle and is able to learn runtime patterns to distinguish passing and failing test executions for systems and tests from different application domains.