 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimited Resource Allocation in a Non-Markovian World: The Case of Maternal and Child Healthcare
May 22, 2023The success of many healthcare programs depends on participants' adherence. We consider the problem of scheduling interventions in low resource settings (e.g., placing timely support calls from health workers) to increase adherence and/or engagement. Past works have successfully developed several classes of Restless Multi-armed Bandit (RMAB) based solutions for this problem. Nevertheless, all past RMAB approaches assume that the participants' behaviour follows the Markov property. We demonstrate significant deviations from the Markov assumption on real-world data on a maternal health awareness program from our partner NGO, ARMMAN. Moreover, we extend RMABs to continuous state spaces, a previously understudied area. To tackle the generalised non-Markovian RMAB setting we (i) model each participant's trajectory as a time-series, (ii) leverage the power of time-series forecasting models to learn complex patterns and dynamics to predict future states, and (iii) propose the Time-series Arm Ranking Index (TARI) policy, a novel algorithm that selects the RMAB arms that will benefit the most from an intervention, given our future state predictions. We evaluate our approach on both synthetic data, and a secondary analysis on real data from ARMMAN, and demonstrate significant increase in engagement compared to the SOTA, deployed Whittle index solution. This translates to 16.3 hours of additional content listened, 90.8% more engagement drops prevented, and reaching more than twice as many high dropout-risk beneficiaries.
Fairness for Workers Who Pull the Arms: An Index Based Policy for Allocation of Restless Bandit Tasks
Mar 01, 2023



Motivated by applications such as machine repair, project monitoring, and anti-poaching patrol scheduling, we study intervention planning of stochastic processes under resource constraints. This planning problem has previously been modeled as restless multi-armed bandits (RMAB), where each arm is an intervention-dependent Markov Decision Process. However, the existing literature assumes all intervention resources belong to a single uniform pool, limiting their applicability to real-world settings where interventions are carried out by a set of workers, each with their own costs, budgets, and intervention effects. In this work, we consider a novel RMAB setting, called multi-worker restless bandits (MWRMAB) with heterogeneous workers. The goal is to plan an intervention schedule that maximizes the expected reward while satisfying budget constraints on each worker as well as fairness in terms of the load assigned to each worker. Our contributions are two-fold: (1) we provide a multi-worker extension of the Whittle index to tackle heterogeneous costs and per-worker budget and (2) we develop an index-based scheduling policy to achieve fairness. Further, we evaluate our method on various cost structures and show that our method significantly outperforms other baselines in terms of fairness without sacrificing much in reward accumulated.
Improved Policy Evaluation for Randomized Trials of Algorithmic Resource Allocation
Feb 06, 2023We consider the task of evaluating policies of algorithmic resource allocation through randomized controlled trials (RCTs). Such policies are tasked with optimizing the utilization of limited intervention resources, with the goal of maximizing the benefits derived. Evaluation of such allocation policies through RCTs proves difficult, notwithstanding the scale of the trial, because the individuals' outcomes are inextricably interlinked through resource constraints controlling the policy decisions. Our key contribution is to present a new estimator leveraging our proposed novel concept, that involves retrospective reshuffling of participants across experimental arms at the end of an RCT. We identify conditions under which such reassignments are permissible and can be leveraged to construct counterfactual trials, whose outcomes can be accurately ascertained, for free. We prove theoretically that such an estimator is more accurate than common estimators based on sample means -- we show that it returns an unbiased estimate and simultaneously reduces variance. We demonstrate the value of our approach through empirical experiments on synthetic, semi-synthetic as well as real case study data and show improved estimation accuracy across the board.
Decision-Focused Evaluation: Analyzing Performance of Deployed Restless Multi-Arm Bandits
Jan 19, 2023Restless multi-arm bandits (RMABs) is a popular decision-theoretic framework that has been used to model real-world sequential decision making problems in public health, wildlife conservation, communication systems, and beyond. Deployed RMAB systems typically operate in two stages: the first predicts the unknown parameters defining the RMAB instance, and the second employs an optimization algorithm to solve the constructed RMAB instance. In this work we provide and analyze the results from a first-of-its-kind deployment of an RMAB system in public health domain, aimed at improving maternal and child health. Our analysis is focused towards understanding the relationship between prediction accuracy and overall performance of deployed RMAB systems. This is crucial for determining the value of investing in improving predictive accuracy towards improving the final system performance, and is useful for diagnosing, monitoring deployed RMAB systems. Using real-world data from our deployed RMAB system, we demonstrate that an improvement in overall prediction accuracy may even be accompanied by a degradation in the performance of RMAB system -- a broad investment of resources to improve overall prediction accuracy may not yield expected results. Following this, we develop decision-focused evaluation metrics to evaluate the predictive component and show that it is better at explaining (both empirically and theoretically) the overall performance of a deployed RMAB system.
Indexability is Not Enough for Whittle: Improved, Near-Optimal Algorithms for Restless Bandits
Oct 31, 2022



We study the problem of planning restless multi-armed bandits (RMABs) with multiple actions. This is a popular model for multi-agent systems with applications like multi-channel communication, monitoring and machine maintenance tasks, and healthcare. Whittle index policies, which are based on Lagrangian relaxations, are widely used in these settings due to their simplicity and near-optimality under certain conditions. In this work, we first show that Whittle index policies can fail in simple and practically relevant RMAB settings, \textit{even when} the RMABs are indexable. We discuss why the optimality guarantees fail and why asymptotic optimality may not translate well to practically relevant planning horizons. We then propose an alternate planning algorithm based on the mean-field method, which can provably and efficiently obtain near-optimal policies with a large number of arms, without the stringent structural assumptions required by the Whittle index policies. This borrows ideas from existing research with some improvements: our approach is hyper-parameter free, and we provide an improved non-asymptotic analysis which has: (a) no requirement for exogenous hyper-parameters and tighter polynomial dependence on known problem parameters; (b) high probability bounds which show that the reward of the policy is reliable; and (c) matching sub-optimality lower bounds for this algorithm with respect to the number of arms, thus demonstrating the tightness of our bounds. Our extensive experimental analysis shows that the mean-field approach matches or outperforms other baselines.
Artificial Intelligence and Life in 2030: The One Hundred Year Study on Artificial Intelligence
Oct 31, 2022In September 2016, Stanford's "One Hundred Year Study on Artificial Intelligence" project (AI100) issued the first report of its planned long-term periodic assessment of artificial intelligence (AI) and its impact on society. It was written by a panel of 17 study authors, each of whom is deeply rooted in AI research, chaired by Peter Stone of the University of Texas at Austin. The report, entitled "Artificial Intelligence and Life in 2030," examines eight domains of typical urban settings on which AI is likely to have impact over the coming years: transportation, home and service robots, healthcare, education, public safety and security, low-resource communities, employment and workplace, and entertainment. It aims to provide the general public with a scientifically and technologically accurate portrayal of the current state of AI and its potential and to help guide decisions in industry and governments, as well as to inform research and development in the field. The charge for this report was given to the panel by the AI100 Standing Committee, chaired by Barbara Grosz of Harvard University.
Artificial Replay: A Meta-Algorithm for Harnessing Historical Data in Bandits
Sep 30, 2022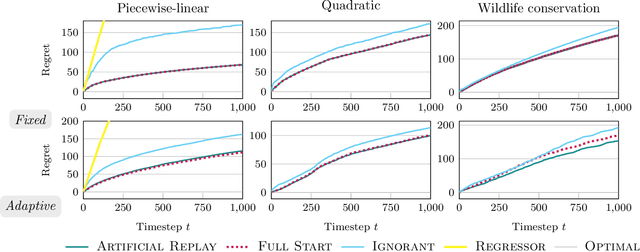

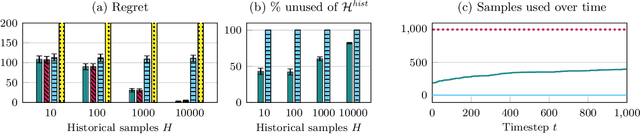
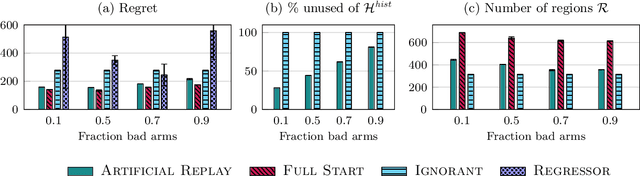
While standard bandit algorithms sometimes incur high regret, their performance can be greatly improved by "warm starting" with historical data. Unfortunately, how best to incorporate historical data is unclear: naively initializing reward estimates using all historical samples can suffer from spurious data and imbalanced data coverage, leading to computational and storage issues - particularly in continuous action spaces. We address these two challenges by proposing Artificial Replay, a meta-algorithm for incorporating historical data into any arbitrary base bandit algorithm. Artificial Replay uses only a subset of the historical data as needed to reduce computation and storage. We show that for a broad class of base algorithms that satisfy independence of irrelevant data (IIData), a novel property that we introduce, our method achieves equal regret as a full warm-start approach while potentially using only a fraction of the historical data. We complement these theoretical results with a case study of $K$-armed and continuous combinatorial bandit algorithms, including on a green security domain using real poaching data, to show the practical benefits of Artificial Replay in achieving optimal regret alongside low computational and storage costs.
Optimistic Whittle Index Policy: Online Learning for Restless Bandits
May 30, 2022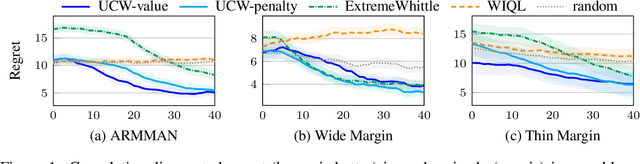

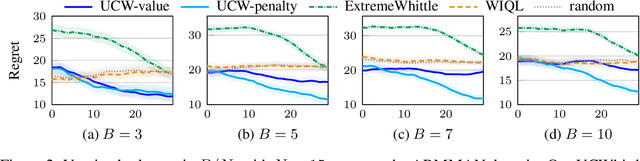
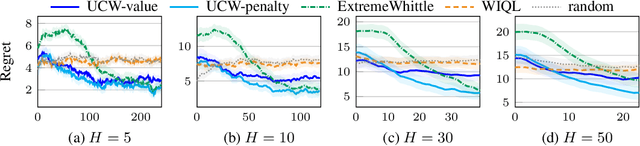
Restless multi-armed bandits (RMABs) extend multi-armed bandits to allow for stateful arms, where the state of each arm evolves restlessly with different transitions depending on whether that arm is pulled. However, solving RMABs requires information on transition dynamics, which is often not available upfront. To plan in RMAB settings with unknown transitions, we propose the first online learning algorithm based on the Whittle index policy, using an upper confidence bound (UCB) approach to learn transition dynamics. Specifically, we formulate a bilinear program to compute the optimistic Whittle index from the confidence bounds in transition dynamics. Our algorithm, UCWhittle, achieves sublinear $O(\sqrt{T \log T})$ frequentist regret to solve RMABs with unknown transitions. Empirically, we demonstrate that UCWhittle leverages the structure of RMABs and the Whittle index policy solution to achieve better performance than existing online learning baselines across three domains, including on real-world maternal and childcare data aimed at reducing maternal mortality.
Ranked Prioritization of Groups in Combinatorial Bandit Allocation
May 11, 2022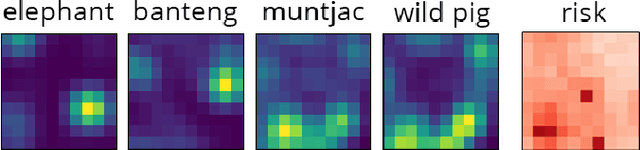
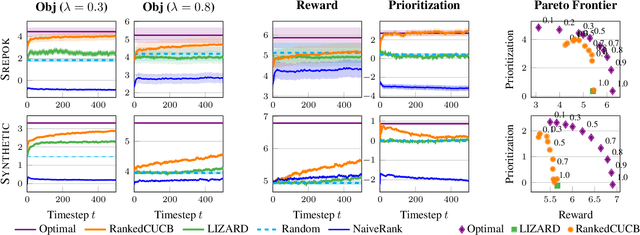
Preventing poaching through ranger patrols protects endangered wildlife, directly contributing to the UN Sustainable Development Goal 15 of life on land. Combinatorial bandits have been used to allocate limited patrol resources, but existing approaches overlook the fact that each location is home to multiple species in varying proportions, so a patrol benefits each species to differing degrees. When some species are more vulnerable, we ought to offer more protection to these animals; unfortunately, existing combinatorial bandit approaches do not offer a way to prioritize important species. To bridge this gap, (1) We propose a novel combinatorial bandit objective that trades off between reward maximization and also accounts for prioritization over species, which we call ranked prioritization. We show this objective can be expressed as a weighted linear sum of Lipschitz-continuous reward functions. (2) We provide RankedCUCB, an algorithm to select combinatorial actions that optimize our prioritization-based objective, and prove that it achieves asymptotic no-regret. (3) We demonstrate empirically that RankedCUCB leads to up to 38% improvement in outcomes for endangered species using real-world wildlife conservation data. Along with adapting to other challenges such as preventing illegal logging and overfishing, our no-regret algorithm addresses the general combinatorial bandit problem with a weighted linear objective.
Evolutionary Approach to Security Games with Signaling
Apr 29, 2022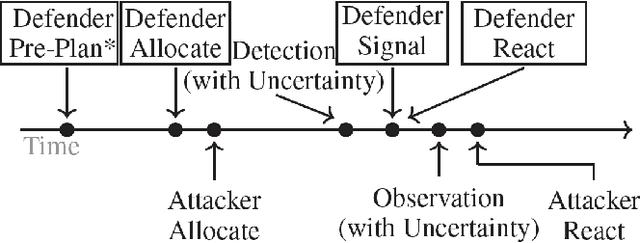
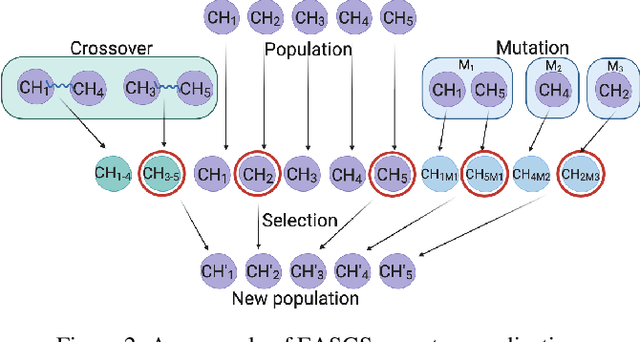
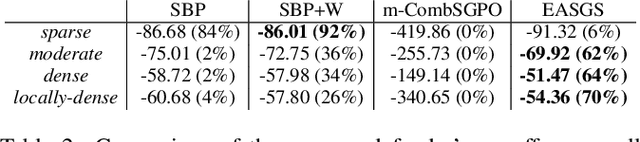
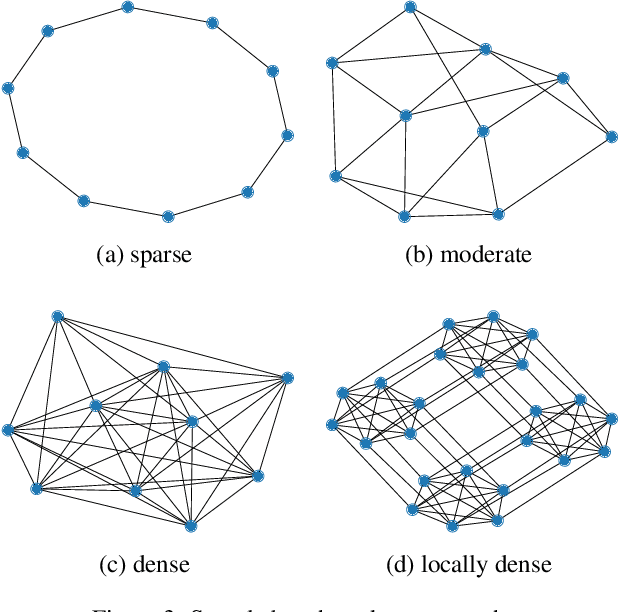
Green Security Games have become a popular way to model scenarios involving the protection of natural resources, such as wildlife. Sensors (e.g. drones equipped with cameras) have also begun to play a role in these scenarios by providing real-time information. Incorporating both human and sensor defender resources strategically is the subject of recent work on Security Games with Signaling (SGS). However, current methods to solve SGS do not scale well in terms of time or memory. We therefore propose a novel approach to SGS, which, for the first time in this domain, employs an Evolutionary Computation paradigm: EASGS. EASGS effectively searches the huge SGS solution space via suitable solution encoding in a chromosome and a specially-designed set of operators. The operators include three types of mutations, each focusing on a particular aspect of the SGS solution, optimized crossover and a local coverage improvement scheme (a memetic aspect of EASGS). We also introduce a new set of benchmark games, based on dense or locally-dense graphs that reflect real-world SGS settings. In the majority of 342 test game instances, EASGS outperforms state-of-the-art methods, including a reinforcement learning method, in terms of time scalability, nearly constant memory utilization, and quality of the returned defender's strategies (expected payoffs).