 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Mediator for Human Negotiation: Pre-Mediation via a Structured LLM Pipeline
Jun 09, 2026Pre-mediation, the preparatory phase preceding direct human negotiation, plays a critical role in achieving mutually beneficial agreements, yet is often omitted due to cost, time, and limited access to trained mediators. We introduce an automated mediator for human negotiation, implemented as a structured pipeline of LLM modules, that supports pre-mediation in integrative negotiation settings. The pipeline decomposes preparation into specialized modules for dialogue, preference prediction, response-level critique, and structured summarization, separating inference, generation, and evaluation to address limitations of monolithic single-prompt approaches. We use the term "agent" for each module following common LLM-systems terminology, but the components are not autonomous and do not interact peer-to-peer; outputs are passed forward in a fixed sequence. We evaluate the system in two controlled human-subject experiments comparing AI-based pre-mediation with professional human mediators in a multi-issue negotiation scenario. On short-term self-reported measures, the automated mediator achieves preparation outcomes broadly comparable to human mediators, including trust in the mediator and confidence in reaching mutually beneficial agreements, while achieving substantially lower error on the preference-inference task under our scenario and prompts (36% lower RMSE). A second study shows that targeted prompt refinements reduce excessive affirmation patterns from 36.6% to 16.8%, matching human mediator baselines. Our findings suggest that structured LLM pipelines can provide scalable, low-effort pre-mediation support broadly comparable to human mediators on short-term self-reported preparation outcomes. The pipeline's single-party design mirrors how human mediators run pre-mediation today and enables parallel deployment across all parties to a dispute, supporting scalability.
Ensemble Self-Training for Unsupervised Machine Translation
Mar 17, 2026We present an ensemble-driven self-training framework for unsupervised neural machine translation (UNMT). Starting from a primary language pair, we train multiple UNMT models that share the same translation task but differ in an auxiliary language, inducing structured diversity across models. We then generate pseudo-translations for the primary pair using token-level ensemble decoding, averaging model predictions in both directions. These ensemble outputs are used as synthetic parallel data to further train each model, allowing the models to improve via shared supervision. At deployment time, we select a single model by validation performance, preserving single-model inference cost. Experiments show statistically significant improvements over single-model UNMT baselines, with mean gains of 1.7 chrF when translating from English and 0.67 chrF when translating into English.
Tacit Coordination of Large Language Models
Jan 28, 2026In tacit coordination games with multiple outcomes, purely rational solution concepts, such as Nash equilibria, provide no guidance for which equilibrium to choose. Shelling's theory explains how, in these settings, humans coordinate by relying on focal points: solutions or outcomes that naturally arise because they stand out in some way as salient or prominent to all players. This work studies Large Language Models (LLMs) as players in tacit coordination games, and addresses how, when, and why focal points emerge. We compare and quantify the coordination capabilities of LLMs in cooperative and competitive games for which human experiments are available. We also introduce several learning-free strategies to improve the coordination of LLMs, with themselves and with humans. On a selection of heterogeneous open-source models, including Llama, Qwen, and GPT-oss, we discover that LLMs have a remarkable capability to coordinate and often outperform humans, yet fail on common-sense coordination that involves numbers or nuanced cultural archetypes. This paper constitutes the first large-scale assessment of LLMs' tacit coordination within the theoretical and psychological framework of focal points.
Pro-AI Bias in Large Language Models
Jan 20, 2026Large language models (LLMs) are increasingly employed for decision-support across multiple domains. We investigate whether these models display a systematic preferential bias in favor of artificial intelligence (AI) itself. Across three complementary experiments, we find consistent evidence of pro-AI bias. First, we show that LLMs disproportionately recommend AI-related options in response to diverse advice-seeking queries, with proprietary models doing so almost deterministically. Second, we demonstrate that models systematically overestimate salaries for AI-related jobs relative to closely matched non-AI jobs, with proprietary models overestimating AI salaries more by 10 percentage points. Finally, probing internal representations of open-weight models reveals that ``Artificial Intelligence'' exhibits the highest similarity to generic prompts for academic fields under positive, negative, and neutral framings alike, indicating valence-invariant representational centrality. These patterns suggest that LLM-generated advice and valuation can systematically skew choices and perceptions in high-stakes decisions.
Context and Transcripts Improve Detection of Deepfake Audios of Public Figures
Jan 19, 2026Humans use context to assess the veracity of information. However, current audio deepfake detectors only analyze the audio file without considering either context or transcripts. We create and analyze a Journalist-provided Deepfake Dataset (JDD) of 255 public deepfakes which were primarily contributed by over 70 journalists since early 2024. We also generate a synthetic audio dataset (SYN) of dead public figures and propose a novel Context-based Audio Deepfake Detector (CADD) architecture. In addition, we evaluate performance on two large-scale datasets: ITW and P$^2$V. We show that sufficient context and/or the transcript can significantly improve the efficacy of audio deepfake detectors. Performance (measured via F1 score, AUC, and EER) of multiple baseline audio deepfake detectors and traditional classifiers can be improved by 5%-37.58% in F1-score, 3.77%-42.79% in AUC, and 6.17%-47.83% in EER. We additionally show that CADD, via its use of context and/or transcripts, is more robust to 5 adversarial evasion strategies, limiting performance degradation to an average of just -0.71% across all experiments. Code, models, and datasets are available at our project page: https://sites.northwestern.edu/nsail/cadd-context-based-audio-deepfake-detection (access restricted during review).
Explaining Decentralized Multi-Agent Reinforcement Learning Policies
Nov 13, 2025Multi-Agent Reinforcement Learning (MARL) has gained significant interest in recent years, enabling sequential decision-making across multiple agents in various domains. However, most existing explanation methods focus on centralized MARL, failing to address the uncertainty and nondeterminism inherent in decentralized settings. We propose methods to generate policy summarizations that capture task ordering and agent cooperation in decentralized MARL policies, along with query-based explanations for When, Why Not, and What types of user queries about specific agent behaviors. We evaluate our approach across four MARL domains and two decentralized MARL algorithms, demonstrating its generalizability and computational efficiency. User studies show that our summarizations and explanations significantly improve user question-answering performance and enhance subjective ratings on metrics such as understanding and satisfaction.
Strategic Communication under Threat: Learning Information Trade-offs in Pursuit-Evasion Games
Oct 09, 2025


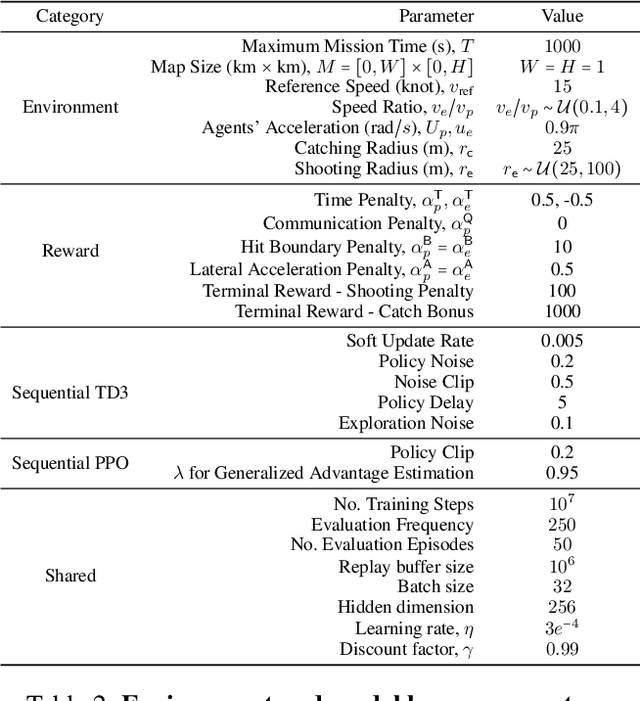
Adversarial environments require agents to navigate a key strategic trade-off: acquiring information enhances situational awareness, but may simultaneously expose them to threats. To investigate this tension, we formulate a PursuitEvasion-Exposure-Concealment Game (PEEC) in which a pursuer agent must decide when to communicate in order to obtain the evader's position. Each communication reveals the pursuer's location, increasing the risk of being targeted. Both agents learn their movement policies via reinforcement learning, while the pursuer additionally learns a communication policy that balances observability and risk. We propose SHADOW (Strategic-communication Hybrid Action Decision-making under partial Observation for Warfare), a multi-headed sequential reinforcement learning framework that integrates continuous navigation control, discrete communication actions, and opponent modeling for behavior prediction. Empirical evaluations show that SHADOW pursuers achieve higher success rates than six competitive baselines. Our ablation study confirms that temporal sequence modeling and opponent modeling are critical for effective decision-making. Finally, our sensitivity analysis reveals that the learned policies generalize well across varying communication risks and physical asymmetries between agents.
Understanding the Logical Capabilities of Large Language Models via Out-of-Context Representation Learning
Mar 13, 2025



We study the capabilities of Large Language Models (LLM) on binary relations, a ubiquitous concept in math employed in most reasoning, math and logic benchmarks. This work focuses on equality, inequality, and inclusion, along with the properties they satisfy, such as ir/reflexivity, a/symmetry, transitivity, and logical complexity (e.g., number of reasoning ``hops''). We propose an alternative to in-context learning that trains only the representations of newly introduced tokens, namely out-of-context representation learning. This method mitigates linguistic biases already present in a model and, differently from in-context learning, does not rely on external information or illustrations. We argue out-of-context representation learning as a better alternative to in-context learning and fine-tuning to evaluate the capabilities of LLMs on logic tasks that are the building blocks of more complex reasoning benchmarks.
Optimistic Gradient Learning with Hessian Corrections for High-Dimensional Black-Box Optimization
Feb 07, 2025



Black-box algorithms are designed to optimize functions without relying on their underlying analytical structure or gradient information, making them essential when gradients are inaccessible or difficult to compute. Traditional methods for solving black-box optimization (BBO) problems predominantly rely on non-parametric models and struggle to scale to large input spaces. Conversely, parametric methods that model the function with neural estimators and obtain gradient signals via backpropagation may suffer from significant gradient errors. A recent alternative, Explicit Gradient Learning (EGL), which directly learns the gradient using a first-order Taylor approximation, has demonstrated superior performance over both parametric and non-parametric methods. In this work, we propose two novel gradient learning variants to address the robustness challenges posed by high-dimensional, complex, and highly non-linear problems. Optimistic Gradient Learning (OGL) introduces a bias toward lower regions in the function landscape, while Higher-order Gradient Learning (HGL) incorporates second-order Taylor corrections to improve gradient accuracy. We combine these approaches into the unified OHGL algorithm, achieving state-of-the-art (SOTA) performance on the synthetic COCO suite. Additionally, we demonstrate OHGLs applicability to high-dimensional real-world machine learning (ML) tasks such as adversarial training and code generation. Our results highlight OHGLs ability to generate stronger candidates, offering a valuable tool for ML researchers and practitioners tackling high-dimensional, non-linear optimization challenges
Bayesian Persuasion with Externalities: Exploiting Agent Types
Dec 17, 2024We study a Bayesian persuasion problem with externalities. In this model, a principal sends signals to inform multiple agents about the state of the world. Simultaneously, due to the existence of externalities in the agents' utilities, the principal also acts as a correlation device to correlate the agents' actions. We consider the setting where the agents are categorized into a small number of types. Agents of the same type share identical utility functions and are treated equitably in the utility functions of both other agents and the principal. We study the problem of computing optimal signaling strategies for the principal, under three different types of signaling channels: public, private, and semi-private. Our results include revelation-principle-style characterizations of optimal signaling strategies, linear programming formulations, and analysis of in/tractability of the optimization problems. It is demonstrated that when the maximum number of deviating agents is bounded by a constant, our LP-based formulations compute optimal signaling strategies in polynomial time. Otherwise, the problems are NP-hard.