 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Model Attribution Challenge
Feb 17, 2023



We present the findings of the Machine Learning Model Attribution Challenge. Fine-tuned machine learning models may derive from other trained models without obvious attribution characteristics. In this challenge, participants identify the publicly-available base models that underlie a set of anonymous, fine-tuned large language models (LLMs) using only textual output of the models. Contestants aim to correctly attribute the most fine-tuned models, with ties broken in the favor of contestants whose solutions use fewer calls to the fine-tuned models' API. The most successful approaches were manual, as participants observed similarities between model outputs and developed attribution heuristics based on public documentation of the base models, though several teams also submitted automated, statistical solutions.
Adversarial Attack Attribution: Discovering Attributable Signals in Adversarial ML Attacks
Jan 08, 2021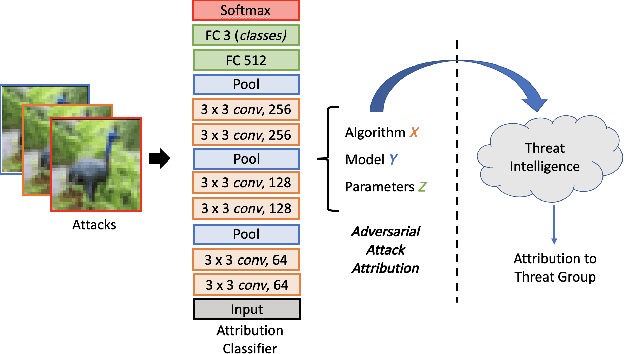

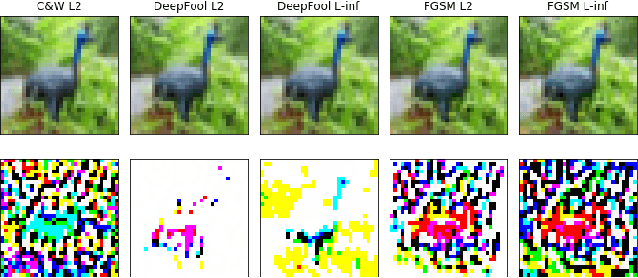
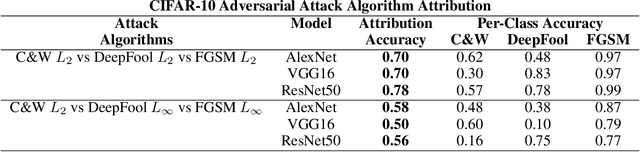
Machine Learning (ML) models are known to be vulnerable to adversarial inputs and researchers have demonstrated that even production systems, such as self-driving cars and ML-as-a-service offerings, are susceptible. These systems represent a target for bad actors. Their disruption can cause real physical and economic harm. When attacks on production ML systems occur, the ability to attribute the attack to the responsible threat group is a critical step in formulating a response and holding the attackers accountable. We pose the following question: can adversarially perturbed inputs be attributed to the particular methods used to generate the attack? In other words, is there a way to find a signal in these attacks that exposes the attack algorithm, model architecture, or hyperparameters used in the attack? We introduce the concept of adversarial attack attribution and create a simple supervised learning experimental framework to examine the feasibility of discovering attributable signals in adversarial attacks. We find that it is possible to differentiate attacks generated with different attack algorithms, models, and hyperparameters on both the CIFAR-10 and MNIST datasets.
APRICOT: A Dataset of Physical Adversarial Attacks on Object Detection
Dec 17, 2019
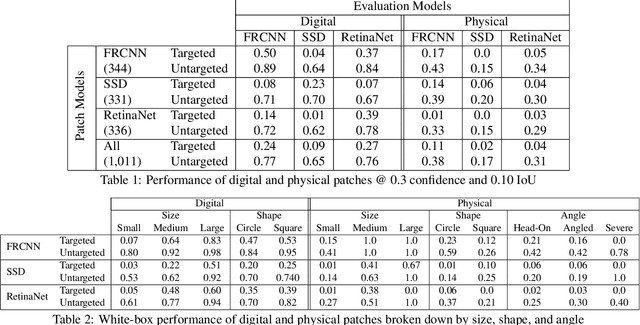

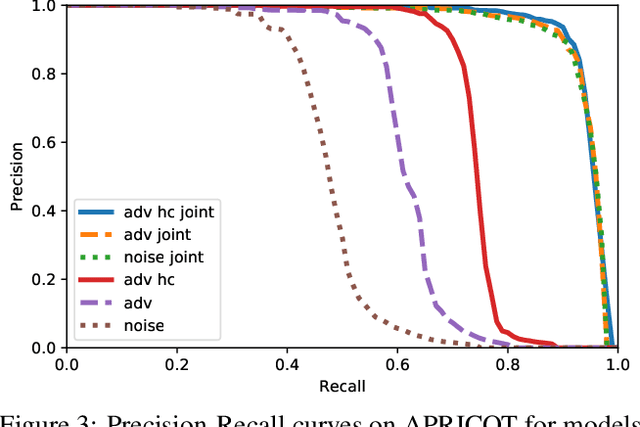
Physical adversarial attacks threaten to fool object detection systems, but reproducible research on the real-world effectiveness of physical patches and how to defend against them requires a publicly available benchmark dataset. We present APRICOT, a collection of over 1,000 annotated photographs of printed adversarial patches in public locations. The patches target several object categories for three COCO-trained detection models, and the photos represent natural variation in position, distance, lighting conditions, and viewing angle. Our analysis suggests that maintaining adversarial robustness in uncontrolled settings is highly challenging, but it is still possible to produce targeted detections under white-box and sometimes black-box settings. We establish baselines for defending against adversarial patches through several methods, including a detector supervised with synthetic data and unsupervised methods such as kernel density estimation, Bayesian uncertainty, and reconstruction error. Our results suggest that adversarial patches can be effectively flagged, both in a high-knowledge, attack-specific scenario, and in an unsupervised setting where patches are detected as anomalies in natural images. This dataset and the described experiments provide a benchmark for future research on the effectiveness of and defenses against physical adversarial objects in the wild.
Overhead Detection: Beyond 8-bits and RGB
Aug 07, 2018
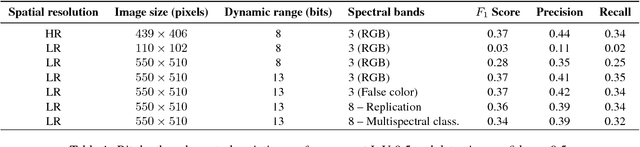
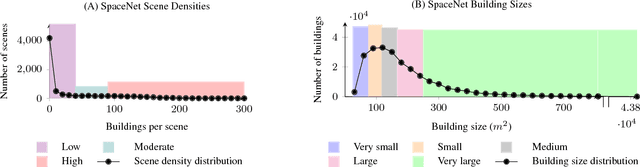
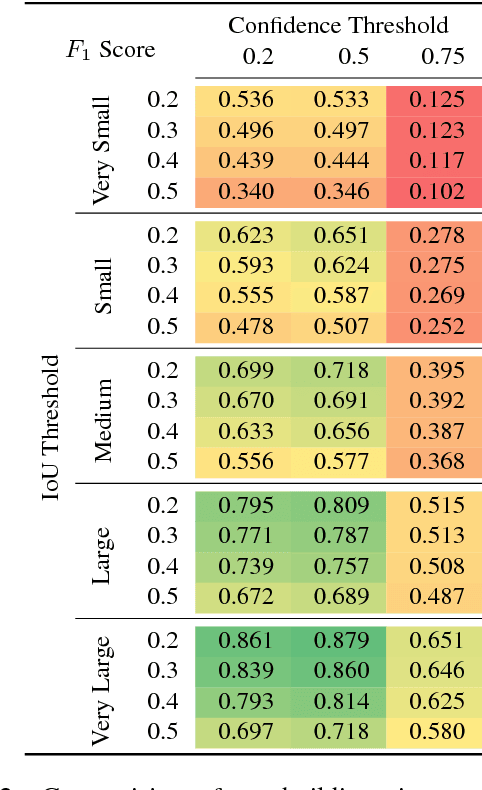
This study uses the challenging and publicly available SpaceNet dataset to establish a performance baseline for a state-of-the-art object detector in satellite imagery. Specifically, we examine how various features of the data affect building detection accuracy with respect to the Intersection over Union metric. We demonstrate that the performance of the R-FCN detection algorithm on imagery with a 1.5 meter ground sample distance and three spectral bands increases by over 32% by using 13-bit data, as opposed to 8-bit data at the same spatial and spectral resolution. We also establish accuracy trends with respect to building size and scene density. Finally, we propose and evaluate multiple methods for integrating additional spectral information into off-the-shelf deep learning architectures. Interestingly, our methods are robust to the choice of spectral bands and we note no significant performance improvement when adding additional bands.
* 10 pages, 8 figures, 2 tables