 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffensive Security for AI Systems: Concepts, Practices, and Applications
May 09, 2025As artificial intelligence (AI) systems become increasingly adopted across sectors, the need for robust, proactive security strategies is paramount. Traditional defensive measures often fall short against the unique and evolving threats facing AI-driven technologies, making offensive security an essential approach for identifying and mitigating risks. This paper presents a comprehensive framework for offensive security in AI systems, emphasizing proactive threat simulation and adversarial testing to uncover vulnerabilities throughout the AI lifecycle. We examine key offensive security techniques, including weakness and vulnerability assessment, penetration testing, and red teaming, tailored specifically to address AI's unique susceptibilities. By simulating real-world attack scenarios, these methodologies reveal critical insights, informing stronger defensive strategies and advancing resilience against emerging threats. This framework advances offensive AI security from theoretical concepts to practical, actionable methodologies that organizations can implement to strengthen their AI systems against emerging threats.
The AI Security Pyramid of Pain
Feb 16, 2024We introduce the AI Security Pyramid of Pain, a framework that adapts the cybersecurity Pyramid of Pain to categorize and prioritize AI-specific threats. This framework provides a structured approach to understanding and addressing various levels of AI threats. Starting at the base, the pyramid emphasizes Data Integrity, which is essential for the accuracy and reliability of datasets and AI models, including their weights and parameters. Ensuring data integrity is crucial, as it underpins the effectiveness of all AI-driven decisions and operations. The next level, AI System Performance, focuses on MLOps-driven metrics such as model drift, accuracy, and false positive rates. These metrics are crucial for detecting potential security breaches, allowing for early intervention and maintenance of AI system integrity. Advancing further, the pyramid addresses the threat posed by Adversarial Tools, identifying and neutralizing tools used by adversaries to target AI systems. This layer is key to staying ahead of evolving attack methodologies. At the Adversarial Input layer, the framework addresses the detection and mitigation of inputs designed to deceive or exploit AI models. This includes techniques like adversarial patterns and prompt injection attacks, which are increasingly used in sophisticated attacks on AI systems. Data Provenance is the next critical layer, ensuring the authenticity and lineage of data and models. This layer is pivotal in preventing the use of compromised or biased data in AI systems. At the apex is the tactics, techniques, and procedures (TTPs) layer, dealing with the most complex and challenging aspects of AI security. This involves a deep understanding and strategic approach to counter advanced AI-targeted attacks, requiring comprehensive knowledge and planning.
Adversarial Attack Attribution: Discovering Attributable Signals in Adversarial ML Attacks
Jan 08, 2021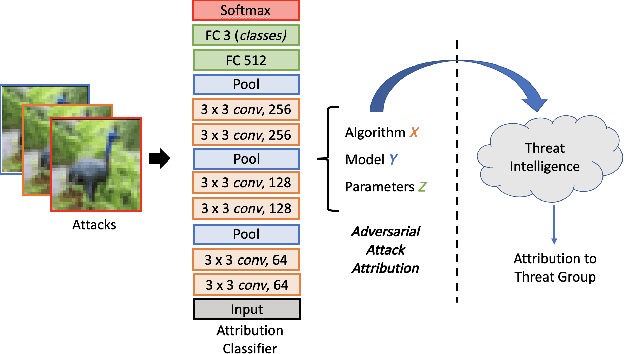

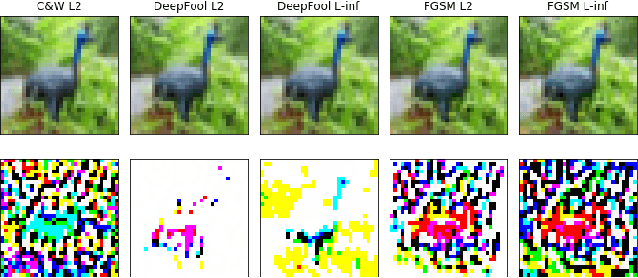
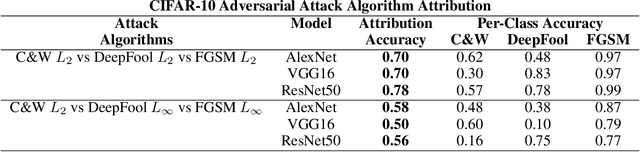
Machine Learning (ML) models are known to be vulnerable to adversarial inputs and researchers have demonstrated that even production systems, such as self-driving cars and ML-as-a-service offerings, are susceptible. These systems represent a target for bad actors. Their disruption can cause real physical and economic harm. When attacks on production ML systems occur, the ability to attribute the attack to the responsible threat group is a critical step in formulating a response and holding the attackers accountable. We pose the following question: can adversarially perturbed inputs be attributed to the particular methods used to generate the attack? In other words, is there a way to find a signal in these attacks that exposes the attack algorithm, model architecture, or hyperparameters used in the attack? We introduce the concept of adversarial attack attribution and create a simple supervised learning experimental framework to examine the feasibility of discovering attributable signals in adversarial attacks. We find that it is possible to differentiate attacks generated with different attack algorithms, models, and hyperparameters on both the CIFAR-10 and MNIST datasets.
Image quality assessment for determining efficacy and limitations of Super-Resolution Convolutional Neural Network (SRCNN)
May 14, 2019Traditional metrics for evaluating the efficacy of image processing techniques do not lend themselves to understanding the capabilities and limitations of modern image processing methods - particularly those enabled by deep learning. When applying image processing in engineering solutions, a scientist or engineer has a need to justify their design decisions with clear metrics. By applying blind/referenceless image spatial quality (BRISQUE), Structural SIMilarity (SSIM) index scores, and Peak signal-to-noise ratio (PSNR) to images before and after image processing, we can quantify quality improvements in a meaningful way and determine the lowest recoverable image quality for a given method.
Leveraging synthetic imagery for collision-at-sea avoidance
May 13, 2019Maritime collisions involving multiple ships are considered rare, but in 2017 several United States Navy vessels were involved in fatal at-sea collisions that resulted in the death of seventeen American Servicemembers. The experimentation introduced in this paper is a direct response to these incidents. We propose a shipboard Collision-At-Sea avoidance system, based on video image processing, that will help ensure the safe stationing and navigation of maritime vessels. Our system leverages a convolutional neural network trained on synthetic maritime imagery in order to detect nearby vessels within a scene, perform heading analysis of detected vessels, and provide an alert in the presence of an inbound vessel. Additionally, we present the Navigational Hazards - Synthetic (NAVHAZ-Synthetic) dataset. This dataset, is comprised of one million annotated images of ten vessel classes observed from virtual vessel-mounted cameras, as well as a human "Topside Lookout" perspective. NAVHAZ-Synthetic includes imagery displaying varying sea-states, lighting conditions, and optical degradations such as fog, sea-spray, and salt-accumulation. We present our results on the use of synthetic imagery in a computer vision based collision-at-sea warning system with promising performance.
Ship classification from overhead imagery using synthetic data and domain adaptation
May 10, 2019
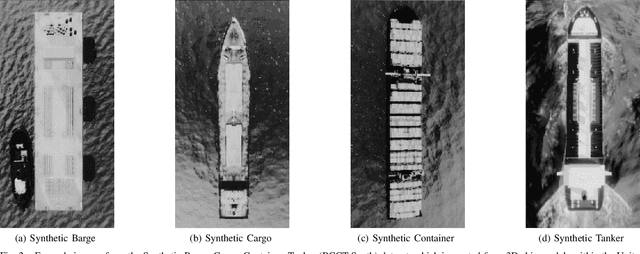
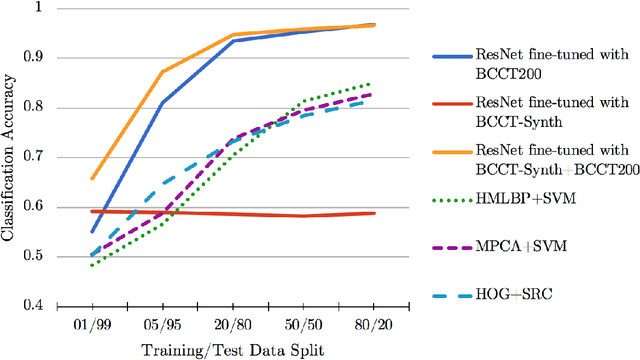
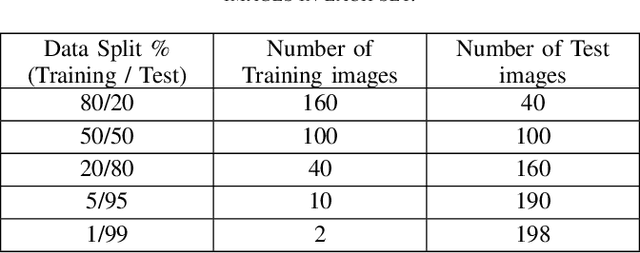
In this paper, we revisit the problem of classifying ships (maritime vessels) detected from overhead imagery. Despite the last decade of research on this very important and pertinent problem, it remains largely unsolved. One of the major issues with the detection and classification of ships and other objects in the maritime domain is the lack of substantial ground truth data needed to train state-of-the-art machine learning algorithms. We address this issue by building a large (200k) synthetic image dataset using the Unity gaming engine and 3D ship models. We demonstrate that with the use of synthetic data, classification performance increases dramatically, particularly when there are very few annotated images used in training.
Generative NeuroEvolution for Deep Learning
Dec 18, 2013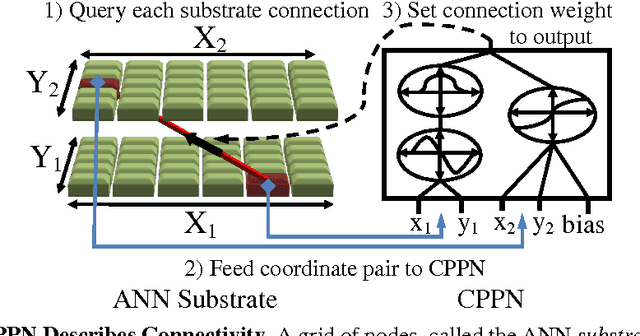
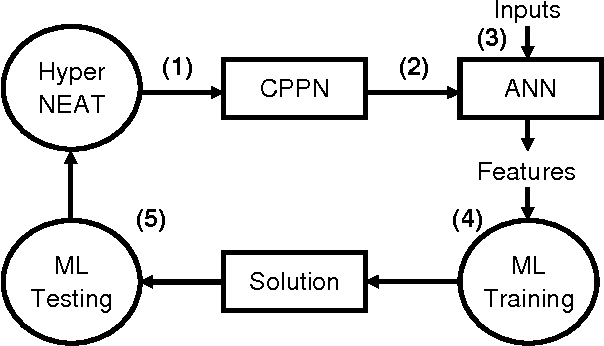
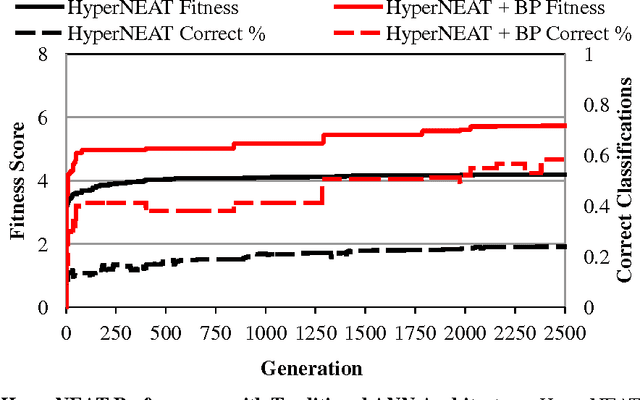
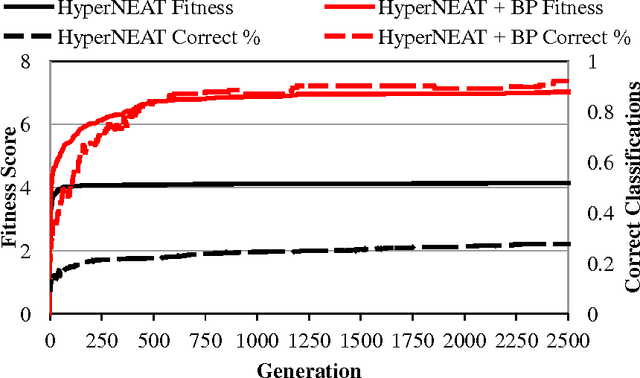
An important goal for the machine learning (ML) community is to create approaches that can learn solutions with human-level capability. One domain where humans have held a significant advantage is visual processing. A significant approach to addressing this gap has been machine learning approaches that are inspired from the natural systems, such as artificial neural networks (ANNs), evolutionary computation (EC), and generative and developmental systems (GDS). Research into deep learning has demonstrated that such architectures can achieve performance competitive with humans on some visual tasks; however, these systems have been primarily trained through supervised and unsupervised learning algorithms. Alternatively, research is showing that evolution may have a significant role in the development of visual systems. Thus this paper investigates the role neuro-evolution (NE) can take in deep learning. In particular, the Hypercube-based NeuroEvolution of Augmenting Topologies is a NE approach that can effectively learn large neural structures by training an indirect encoding that compresses the ANN weight pattern as a function of geometry. The results show that HyperNEAT struggles with performing image classification by itself, but can be effective in training a feature extractor that other ML approaches can learn from. Thus NeuroEvolution combined with other ML methods provides an intriguing area of research that can replicate the processes in nature.