 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCCULT: Evaluating Large Language Models for Offensive Cyber Operation Capabilities
Feb 18, 2025



The prospect of artificial intelligence (AI) competing in the adversarial landscape of cyber security has long been considered one of the most impactful, challenging, and potentially dangerous applications of AI. Here, we demonstrate a new approach to assessing AI's progress towards enabling and scaling real-world offensive cyber operations (OCO) tactics in use by modern threat actors. We detail OCCULT, a lightweight operational evaluation framework that allows cyber security experts to contribute to rigorous and repeatable measurement of the plausible cyber security risks associated with any given large language model (LLM) or AI employed for OCO. We also prototype and evaluate three very different OCO benchmarks for LLMs that demonstrate our approach and serve as examples for building benchmarks under the OCCULT framework. Finally, we provide preliminary evaluation results to demonstrate how this framework allows us to move beyond traditional all-or-nothing tests, such as those crafted from educational exercises like capture-the-flag environments, to contextualize our indicators and warnings in true cyber threat scenarios that present risks to modern infrastructure. We find that there has been significant recent advancement in the risks of AI being used to scale realistic cyber threats. For the first time, we find a model (DeepSeek-R1) is capable of correctly answering over 90% of challenging offensive cyber knowledge tests in our Threat Actor Competency Test for LLMs (TACTL) multiple-choice benchmarks. We also show how Meta's Llama and Mistral's Mixtral model families show marked performance improvements over earlier models against our benchmarks where LLMs act as offensive agents in MITRE's high-fidelity offensive and defensive cyber operations simulation environment, CyberLayer.
Reinforcement Learning for Wildfire Mitigation in Simulated Disaster Environments
Nov 27, 2023



Climate change has resulted in a year over year increase in adverse weather and weather conditions which contribute to increasingly severe fire seasons. Without effective mitigation, these fires pose a threat to life, property, ecology, cultural heritage, and critical infrastructure. To better prepare for and react to the increasing threat of wildfires, more accurate fire modelers and mitigation responses are necessary. In this paper, we introduce SimFire, a versatile wildland fire projection simulator designed to generate realistic wildfire scenarios, and SimHarness, a modular agent-based machine learning wrapper capable of automatically generating land management strategies within SimFire to reduce the overall damage to the area. Together, this publicly available system allows researchers and practitioners the ability to emulate and assess the effectiveness of firefighter interventions and formulate strategic plans that prioritize value preservation and resource allocation optimization. The repositories are available for download at https://github.com/mitrefireline.
Adversarial Attack Attribution: Discovering Attributable Signals in Adversarial ML Attacks
Jan 08, 2021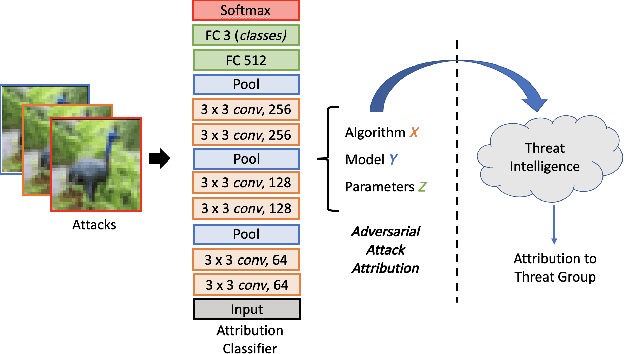

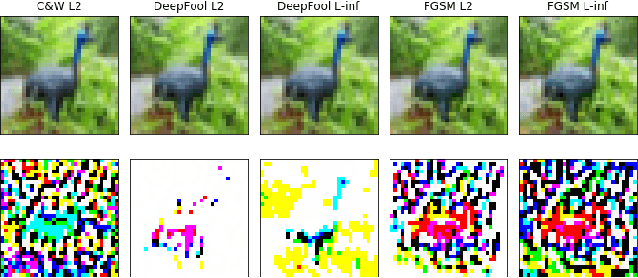
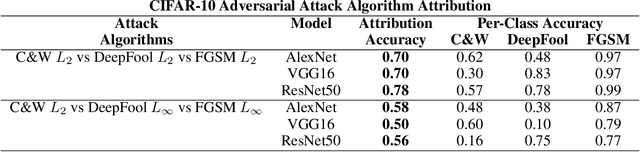
Machine Learning (ML) models are known to be vulnerable to adversarial inputs and researchers have demonstrated that even production systems, such as self-driving cars and ML-as-a-service offerings, are susceptible. These systems represent a target for bad actors. Their disruption can cause real physical and economic harm. When attacks on production ML systems occur, the ability to attribute the attack to the responsible threat group is a critical step in formulating a response and holding the attackers accountable. We pose the following question: can adversarially perturbed inputs be attributed to the particular methods used to generate the attack? In other words, is there a way to find a signal in these attacks that exposes the attack algorithm, model architecture, or hyperparameters used in the attack? We introduce the concept of adversarial attack attribution and create a simple supervised learning experimental framework to examine the feasibility of discovering attributable signals in adversarial attacks. We find that it is possible to differentiate attacks generated with different attack algorithms, models, and hyperparameters on both the CIFAR-10 and MNIST datasets.