 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow much pretraining data do language models need to learn syntax?
Sep 09, 2021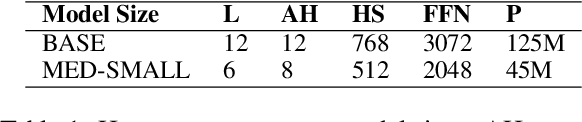
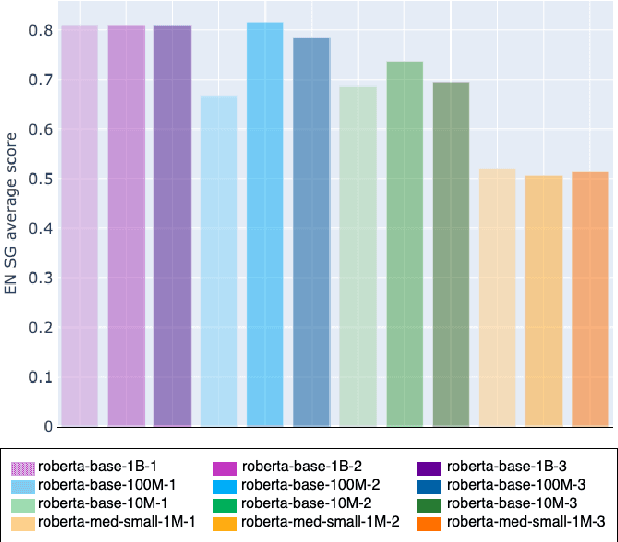
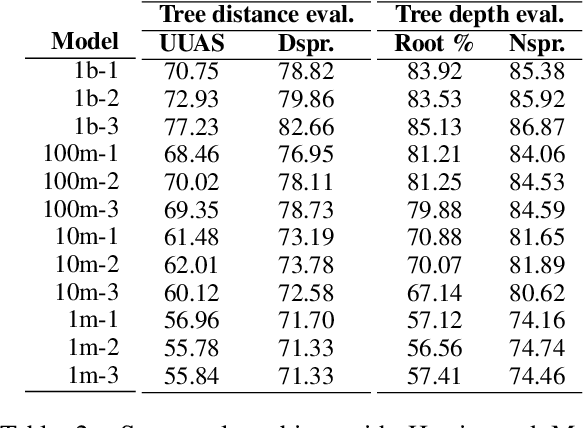
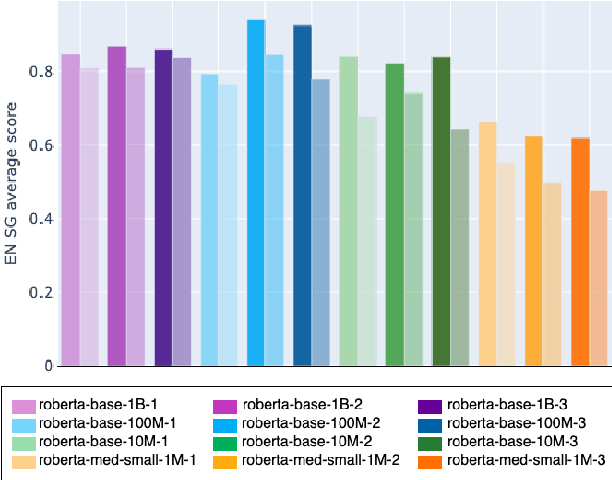
Transformers-based pretrained language models achieve outstanding results in many well-known NLU benchmarks. However, while pretraining methods are very convenient, they are expensive in terms of time and resources. This calls for a study of the impact of pretraining data size on the knowledge of the models. We explore this impact on the syntactic capabilities of RoBERTa, using models trained on incremental sizes of raw text data. First, we use syntactic structural probes to determine whether models pretrained on more data encode a higher amount of syntactic information. Second, we perform a targeted syntactic evaluation to analyze the impact of pretraining data size on the syntactic generalization performance of the models. Third, we compare the performance of the different models on three downstream applications: part-of-speech tagging, dependency parsing and paraphrase identification. We complement our study with an analysis of the cost-benefit trade-off of training such models. Our experiments show that while models pretrained on more data encode more syntactic knowledge and perform better on downstream applications, they do not always offer a better performance across the different syntactic phenomena and come at a higher financial and environmental cost.
Sequential Cross-Document Coreference Resolution
Apr 17, 2021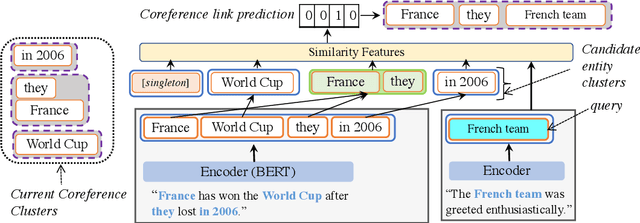
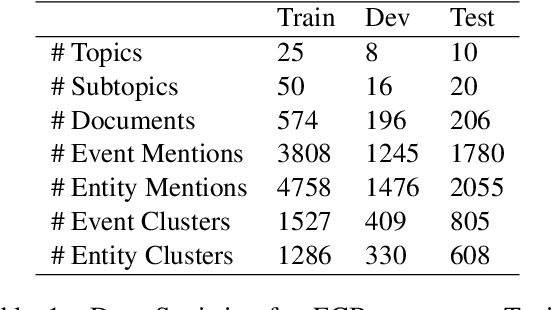

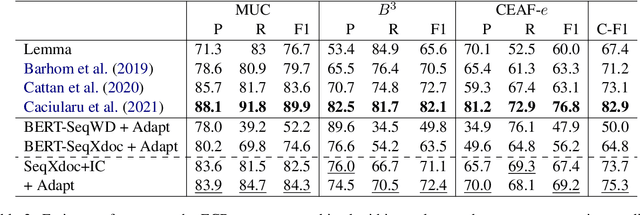
Relating entities and events in text is a key component of natural language understanding. Cross-document coreference resolution, in particular, is important for the growing interest in multi-document analysis tasks. In this work we propose a new model that extends the efficient sequential prediction paradigm for coreference resolution to cross-document settings and achieves competitive results for both entity and event coreference while provides strong evidence of the efficacy of both sequential models and higher-order inference in cross-document settings. Our model incrementally composes mentions into cluster representations and predicts links between a mention and the already constructed clusters, approximating a higher-order model. In addition, we conduct extensive ablation studies that provide new insights into the importance of various inputs and representation types in coreference.
On the Evolution of Syntactic Information Encoded by BERT's Contextualized Representations
Feb 10, 2021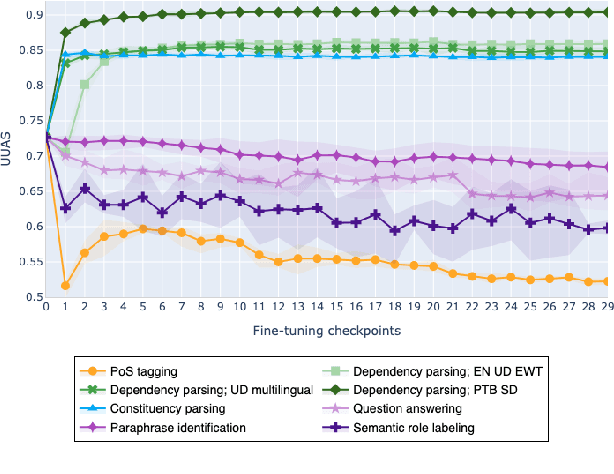
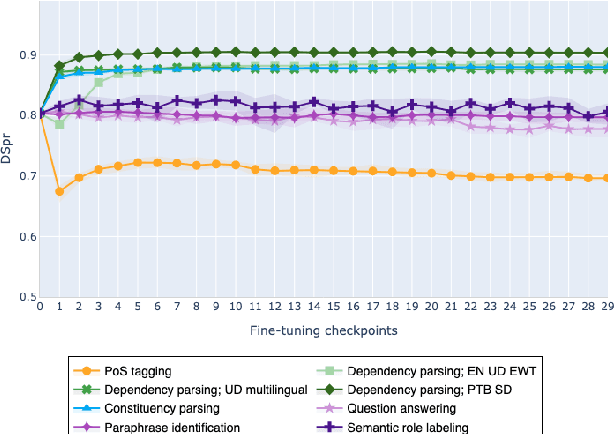
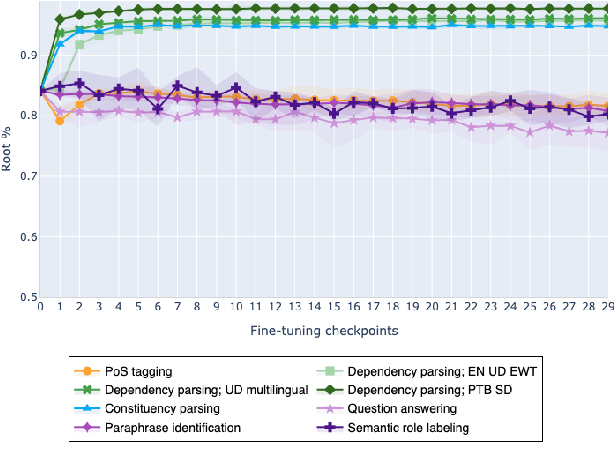
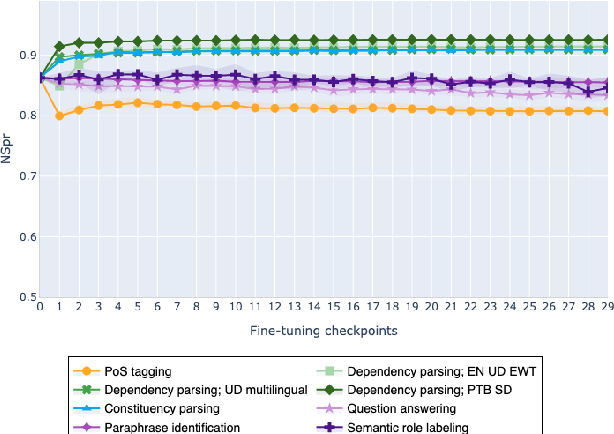
The adaptation of pretrained language models to solve supervised tasks has become a baseline in NLP, and many recent works have focused on studying how linguistic information is encoded in the pretrained sentence representations. Among other information, it has been shown that entire syntax trees are implicitly embedded in the geometry of such models. As these models are often fine-tuned, it becomes increasingly important to understand how the encoded knowledge evolves along the fine-tuning. In this paper, we analyze the evolution of the embedded syntax trees along the fine-tuning process of BERT for six different tasks, covering all levels of the linguistic structure. Experimental results show that the encoded syntactic information is forgotten (PoS tagging), reinforced (dependency and constituency parsing) or preserved (semantics-related tasks) in different ways along the fine-tuning process depending on the task.
Event-Driven News Stream Clustering using Entity-Aware Contextual Embeddings
Jan 26, 2021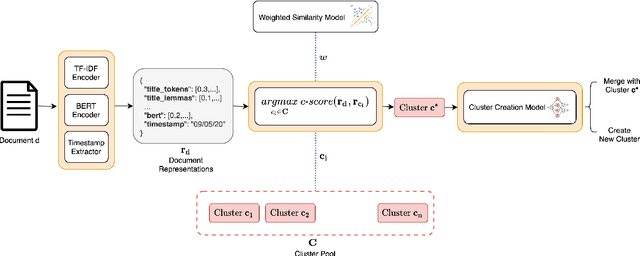
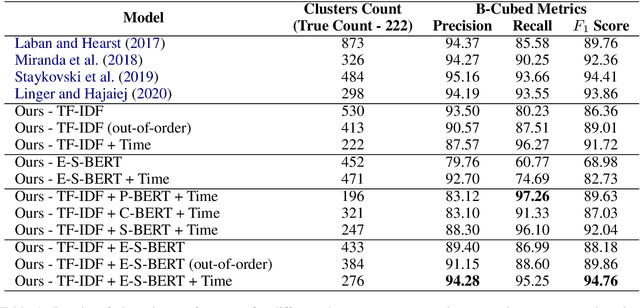
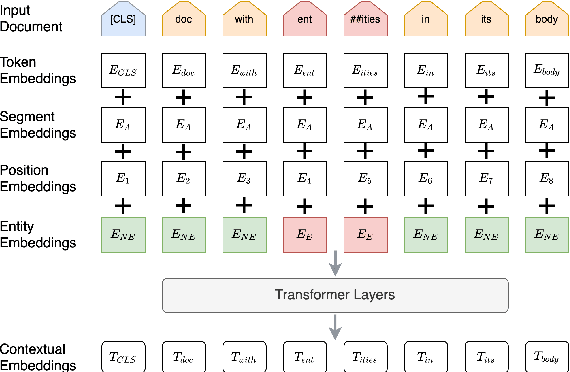
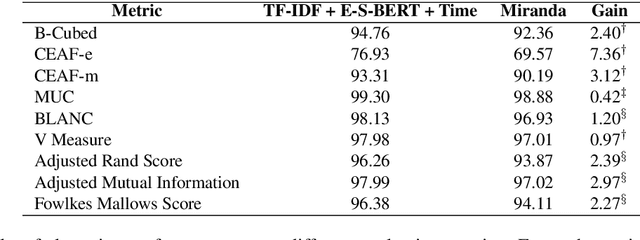
We propose a method for online news stream clustering that is a variant of the non-parametric streaming K-means algorithm. Our model uses a combination of sparse and dense document representations, aggregates document-cluster similarity along these multiple representations and makes the clustering decision using a neural classifier. The weighted document-cluster similarity model is learned using a novel adaptation of the triplet loss into a linear classification objective. We show that the use of a suitable fine-tuning objective and external knowledge in pre-trained transformer models yields significant improvements in the effectiveness of contextual embeddings for clustering. Our model achieves a new state-of-the-art on a standard stream clustering dataset of English documents.
To BERT or Not to BERT: Comparing Task-specific and Task-agnostic Semi-Supervised Approaches for Sequence Tagging
Oct 27, 2020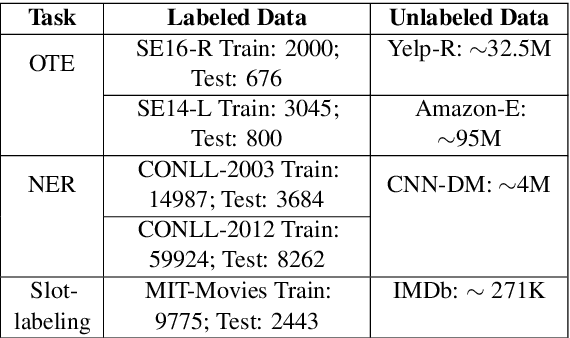
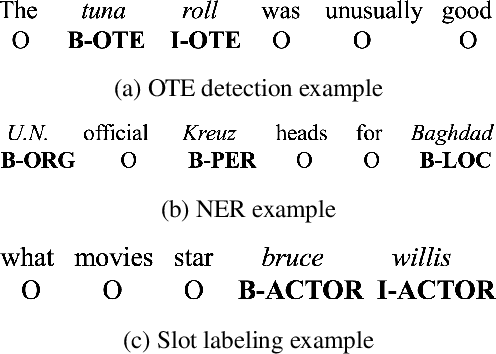
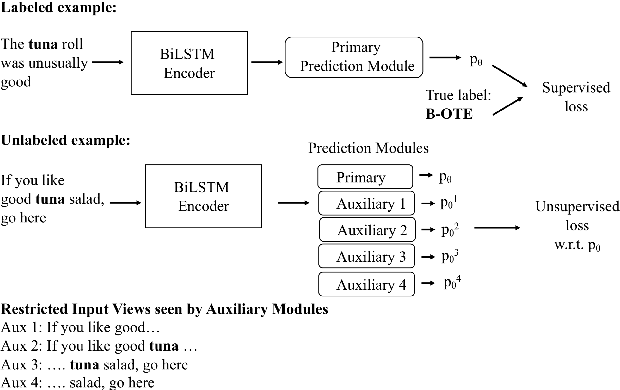
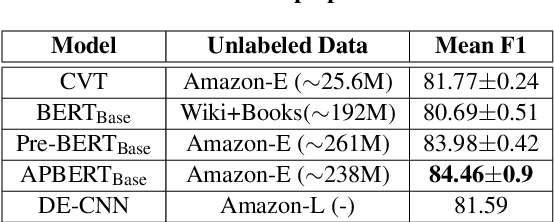
Leveraging large amounts of unlabeled data using Transformer-like architectures, like BERT, has gained popularity in recent times owing to their effectiveness in learning general representations that can then be further fine-tuned for downstream tasks to much success. However, training these models can be costly both from an economic and environmental standpoint. In this work, we investigate how to effectively use unlabeled data: by exploring the task-specific semi-supervised approach, Cross-View Training (CVT) and comparing it with task-agnostic BERT in multiple settings that include domain and task relevant English data. CVT uses a much lighter model architecture and we show that it achieves similar performance to BERT on a set of sequence tagging tasks, with lesser financial and environmental impact.
Linking Entities to Unseen Knowledge Bases with Arbitrary Schemas
Oct 21, 2020
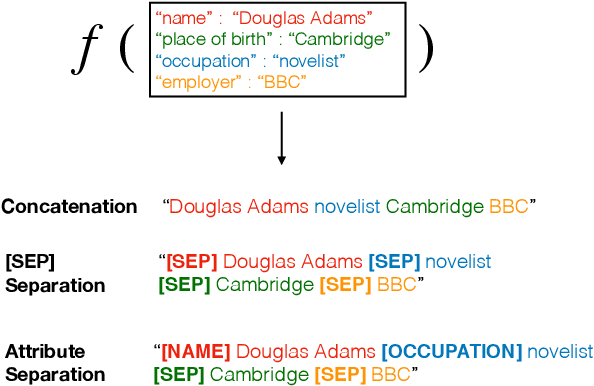
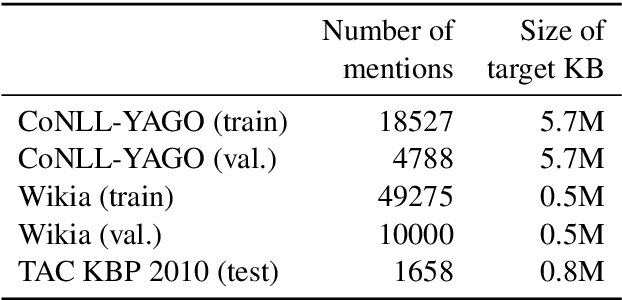
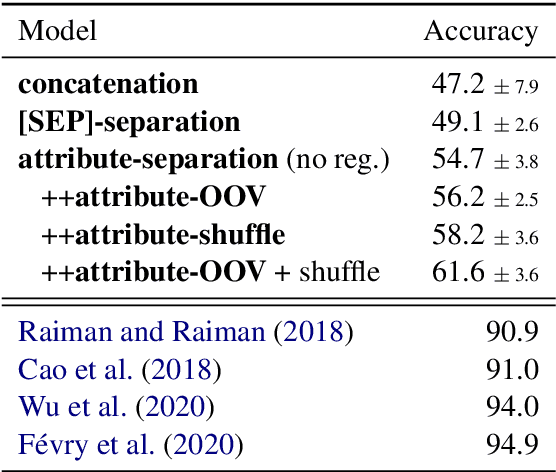
In entity linking, mentions of named entities in raw text are disambiguated against a knowledge base (KB). This work focuses on linking to unseen KBs that do not have training data and whose schema is unknown during training. Our approach relies on methods to flexibly convert entities from arbitrary KBs with several attribute-value pairs into flat strings, which we use in conjunction with state-of-the-art models for zero-shot linking. To improve the generalization of our model, we use two regularization schemes based on shuffling of entity attributes and handling of unseen attributes. Experiments on English datasets where models are trained on the CoNLL dataset, and tested on the TAC-KBP 2010 dataset show that our models outperform baseline models by over 12 points of accuracy. Unlike prior work, our approach also allows for seamlessly combining multiple training datasets. We test this ability by adding both a completely different dataset (Wikia), as well as increasing amount of training data from the TAC-KBP 2010 training set. Our models perform favorably across the board.
Transition-based Parsing with Stack-Transformers
Oct 20, 2020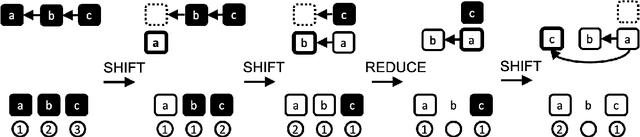

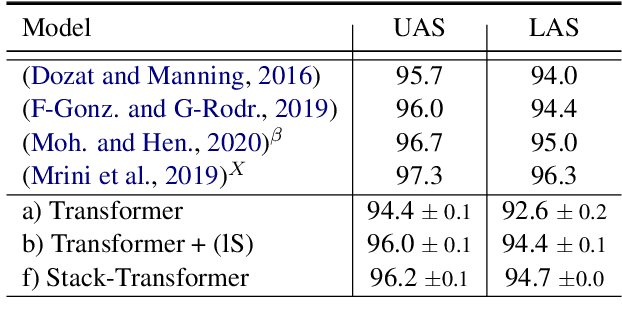
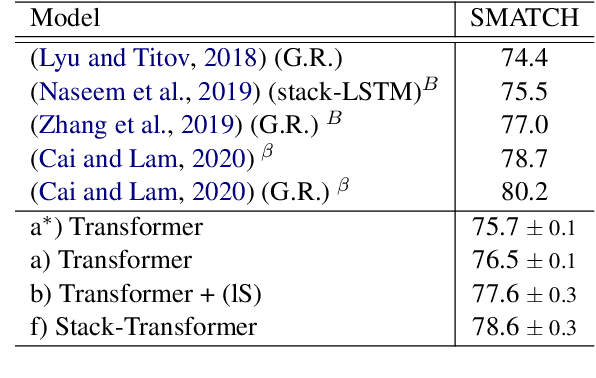
Modeling the parser state is key to good performance in transition-based parsing. Recurrent Neural Networks considerably improved the performance of transition-based systems by modelling the global state, e.g. stack-LSTM parsers, or local state modeling of contextualized features, e.g. Bi-LSTM parsers. Given the success of Transformer architectures in recent parsing systems, this work explores modifications of the sequence-to-sequence Transformer architecture to model either global or local parser states in transition-based parsing. We show that modifications of the cross attention mechanism of the Transformer considerably strengthen performance both on dependency and Abstract Meaning Representation (AMR) parsing tasks, particularly for smaller models or limited training data.
Structural Supervision Improves Few-Shot Learning and Syntactic Generalization in Neural Language Models
Oct 12, 2020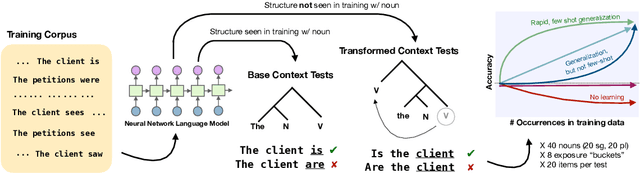
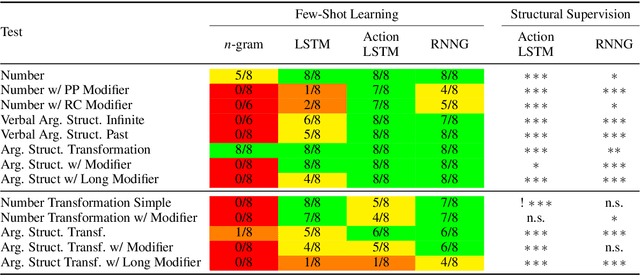
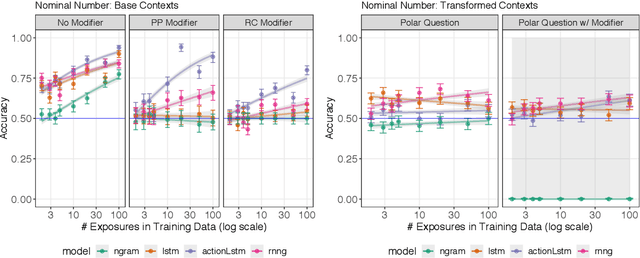
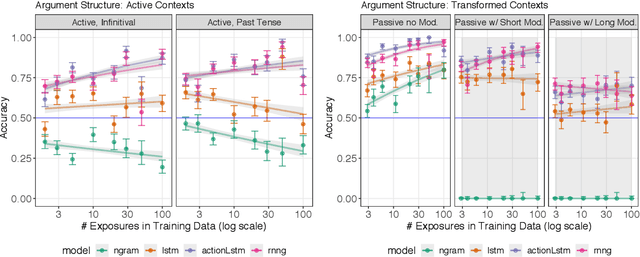
Humans can learn structural properties about a word from minimal experience, and deploy their learned syntactic representations uniformly in different grammatical contexts. We assess the ability of modern neural language models to reproduce this behavior in English and evaluate the effect of structural supervision on learning outcomes. First, we assess few-shot learning capabilities by developing controlled experiments that probe models' syntactic nominal number and verbal argument structure generalizations for tokens seen as few as two times during training. Second, we assess invariance properties of learned representation: the ability of a model to transfer syntactic generalizations from a base context (e.g., a simple declarative active-voice sentence) to a transformed context (e.g., an interrogative sentence). We test four models trained on the same dataset: an n-gram baseline, an LSTM, and two LSTM-variants trained with explicit structural supervision (Dyer et al.,2016; Charniak et al., 2016). We find that in most cases, the neural models are able to induce the proper syntactic generalizations after minimal exposure, often from just two examples during training, and that the two structurally supervised models generalize more accurately than the LSTM model. All neural models are able to leverage information learned in base contexts to drive expectations in transformed contexts, indicating that they have learned some invariance properties of syntax.
Resource-Enhanced Neural Model for Event Argument Extraction
Oct 06, 2020
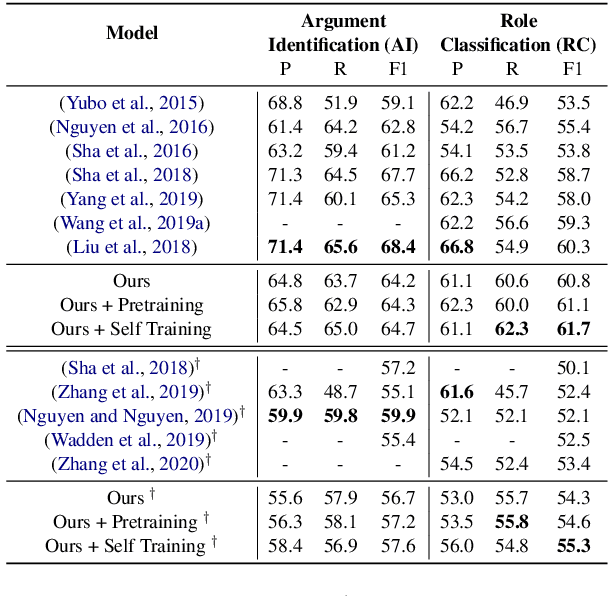
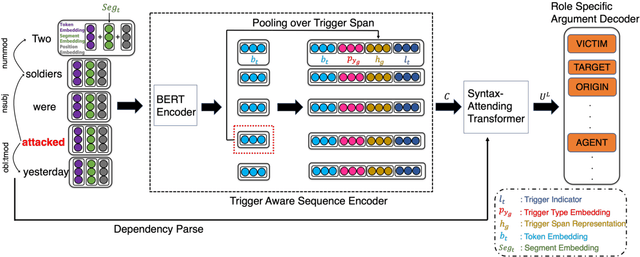
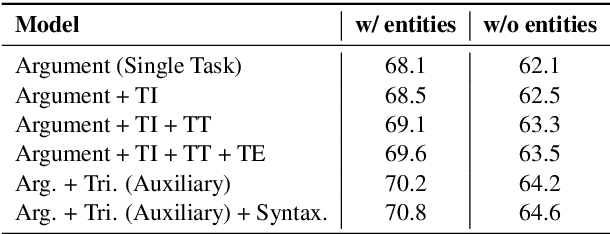
Event argument extraction (EAE) aims to identify the arguments of an event and classify the roles that those arguments play. Despite great efforts made in prior work, there remain many challenges: (1) Data scarcity. (2) Capturing the long-range dependency, specifically, the connection between an event trigger and a distant event argument. (3) Integrating event trigger information into candidate argument representation. For (1), we explore using unlabeled data in different ways. For (2), we propose to use a syntax-attending Transformer that can utilize dependency parses to guide the attention mechanism. For (3), we propose a trigger-aware sequence encoder with several types of trigger-dependent sequence representations. We also support argument extraction either from text annotated with gold entities or from plain text. Experiments on the English ACE2005 benchmark show that our approach achieves a new state-of-the-art.
Severing the Edge Between Before and After: Neural Architectures for Temporal Ordering of Events
Apr 08, 2020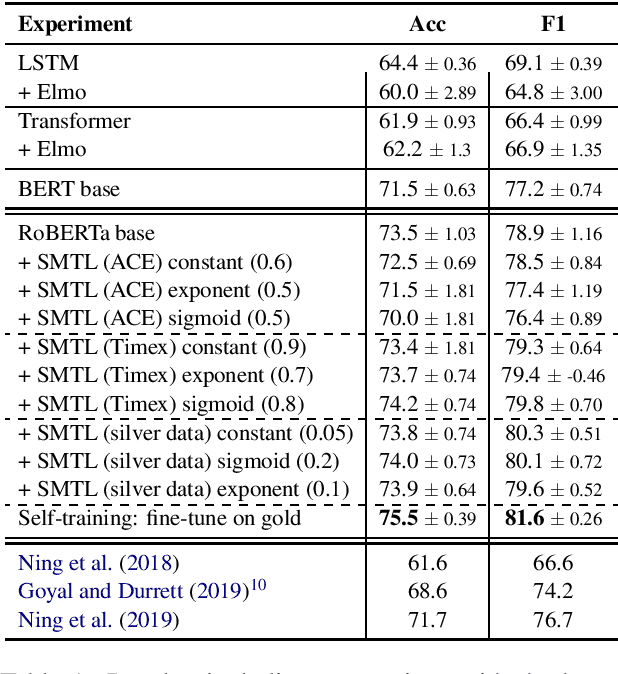
In this paper, we propose a neural architecture and a set of training methods for ordering events by predicting temporal relations. Our proposed models receive a pair of events within a span of text as input and they identify temporal relations (Before, After, Equal, Vague) between them. Given that a key challenge with this task is the scarcity of annotated data, our models rely on either pretrained representations (i.e. RoBERTa, BERT or ELMo), transfer and multi-task learning (by leveraging complementary datasets), and self-training techniques. Experiments on the MATRES dataset of English documents establish a new state-of-the-art on this task.