 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Weak Supervision Approach for Few-Shot Aspect Based Sentiment
May 19, 2023



We explore how weak supervision on abundant unlabeled data can be leveraged to improve few-shot performance in aspect-based sentiment analysis (ABSA) tasks. We propose a pipeline approach to construct a noisy ABSA dataset, and we use it to adapt a pre-trained sequence-to-sequence model to the ABSA tasks. We test the resulting model on three widely used ABSA datasets, before and after fine-tuning. Our proposed method preserves the full fine-tuning performance while showing significant improvements (15.84% absolute F1) in the few-shot learning scenario for the harder tasks. In zero-shot (i.e., without fine-tuning), our method outperforms the previous state of the art on the aspect extraction sentiment classification (AESC) task and is, additionally, capable of performing the harder aspect sentiment triplet extraction (ASTE) task.
Comparing Biases and the Impact of Multilingual Training across Multiple Languages
May 18, 2023



Studies in bias and fairness in natural language processing have primarily examined social biases within a single language and/or across few attributes (e.g. gender, race). However, biases can manifest differently across various languages for individual attributes. As a result, it is critical to examine biases within each language and attribute. Of equal importance is to study how these biases compare across languages and how the biases are affected when training a model on multilingual data versus monolingual data. We present a bias analysis across Italian, Chinese, English, Hebrew, and Spanish on the downstream sentiment analysis task to observe whether specific demographics are viewed more positively. We study bias similarities and differences across these languages and investigate the impact of multilingual vs. monolingual training data. We adapt existing sentiment bias templates in English to Italian, Chinese, Hebrew, and Spanish for four attributes: race, religion, nationality, and gender. Our results reveal similarities in bias expression such as favoritism of groups that are dominant in each language's culture (e.g. majority religions and nationalities). Additionally, we find an increased variation in predictions across protected groups, indicating bias amplification, after multilingual finetuning in comparison to multilingual pretraining.
Simple Yet Effective Synthetic Dataset Construction for Unsupervised Opinion Summarization
Mar 21, 2023



Opinion summarization provides an important solution for summarizing opinions expressed among a large number of reviews. However, generating aspect-specific and general summaries is challenging due to the lack of annotated data. In this work, we propose two simple yet effective unsupervised approaches to generate both aspect-specific and general opinion summaries by training on synthetic datasets constructed with aspect-related review contents. Our first approach, Seed Words Based Leave-One-Out (SW-LOO), identifies aspect-related portions of reviews simply by exact-matching aspect seed words and outperforms existing methods by 3.4 ROUGE-L points on SPACE and 0.5 ROUGE-1 point on OPOSUM+ for aspect-specific opinion summarization. Our second approach, Natural Language Inference Based Leave-One-Out (NLI-LOO) identifies aspect-related sentences utilizing an NLI model in a more general setting without using seed words and outperforms existing approaches by 1.2 ROUGE-L points on SPACE for aspect-specific opinion summarization and remains competitive on other metrics.
Dynamic Benchmarking of Masked Language Models on Temporal Concept Drift with Multiple Views
Feb 23, 2023



Temporal concept drift refers to the problem of data changing over time. In NLP, that would entail that language (e.g. new expressions, meaning shifts) and factual knowledge (e.g. new concepts, updated facts) evolve over time. Focusing on the latter, we benchmark $11$ pretrained masked language models (MLMs) on a series of tests designed to evaluate the effect of temporal concept drift, as it is crucial that widely used language models remain up-to-date with the ever-evolving factual updates of the real world. Specifically, we provide a holistic framework that (1) dynamically creates temporal test sets of any time granularity (e.g. month, quarter, year) of factual data from Wikidata, (2) constructs fine-grained splits of tests (e.g. updated, new, unchanged facts) to ensure comprehensive analysis, and (3) evaluates MLMs in three distinct ways (single-token probing, multi-token generation, MLM scoring). In contrast to prior work, our framework aims to unveil how robust an MLM is over time and thus to provide a signal in case it has become outdated, by leveraging multiple views of evaluation.
Novel Chapter Abstractive Summarization using Spinal Tree Aware Sub-Sentential Content Selection
Nov 09, 2022



Summarizing novel chapters is a difficult task due to the input length and the fact that sentences that appear in the desired summaries draw content from multiple places throughout the chapter. We present a pipelined extractive-abstractive approach where the extractive step filters the content that is passed to the abstractive component. Extremely lengthy input also results in a highly skewed dataset towards negative instances for extractive summarization; we thus adopt a margin ranking loss for extraction to encourage separation between positive and negative examples. Our extraction component operates at the constituent level; our approach to this problem enriches the text with spinal tree information which provides syntactic context (in the form of constituents) to the extraction model. We show an improvement of 3.71 Rouge-1 points over best results reported in prior work on an existing novel chapter dataset.
Instruction Tuning for Few-Shot Aspect-Based Sentiment Analysis
Oct 12, 2022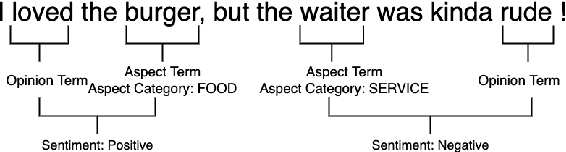
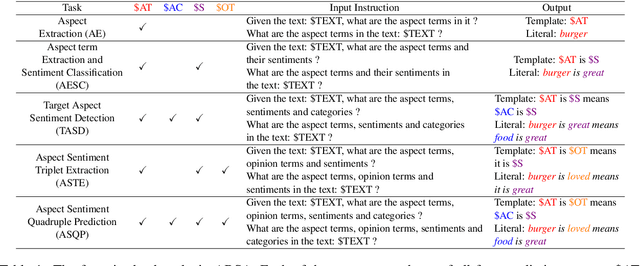
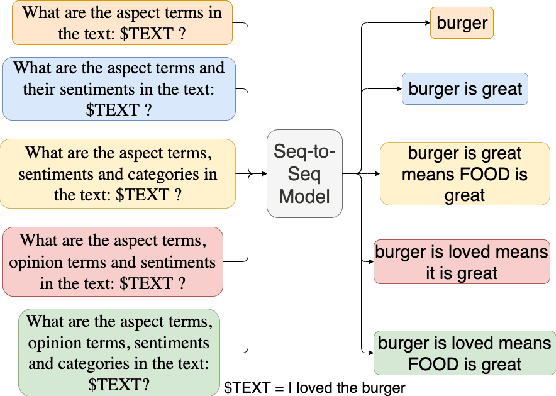
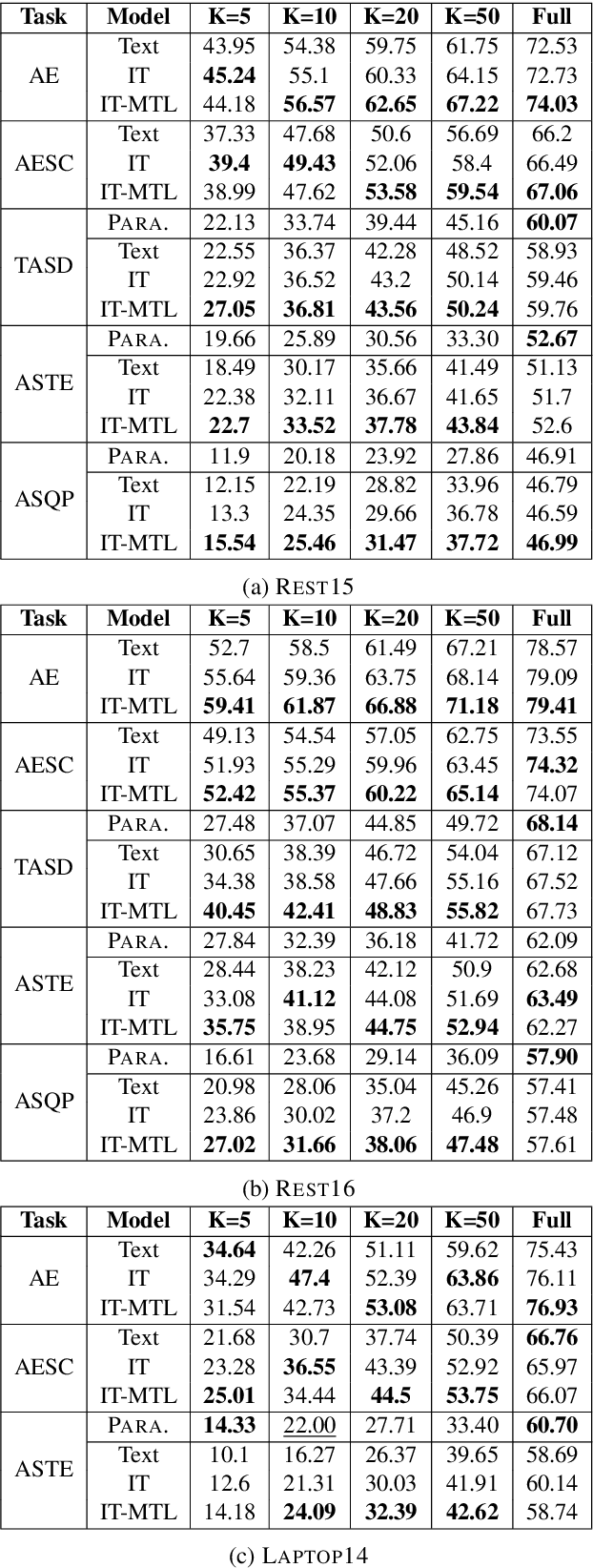
Aspect-based Sentiment Analysis (ABSA) is a fine-grained sentiment analysis task which involves four elements from user-generated texts: aspect term, aspect category, opinion term, and sentiment polarity. Most computational approaches focus on some of the ABSA sub-tasks such as tuple (aspect term, sentiment polarity) or triplet (aspect term, opinion term, sentiment polarity) extraction using either pipeline or joint modeling approaches. Recently, generative approaches have been proposed to extract all four elements as (one or more) quadruplets from text as a single task. In this work, we take a step further and propose a unified framework for solving ABSA, and the associated sub-tasks to improve the performance in few-shot scenarios. To this end, we fine-tune a T5 model with instructional prompts in a multi-task learning fashion covering all the sub-tasks, as well as the entire quadruple prediction task. In experiments with multiple benchmark data sets, we show that the proposed multi-task prompting approach brings performance boost (by absolute $6.75$ F1) in the few-shot learning setting.
Contrastive Training Improves Zero-Shot Classification of Semi-structured Documents
Oct 11, 2022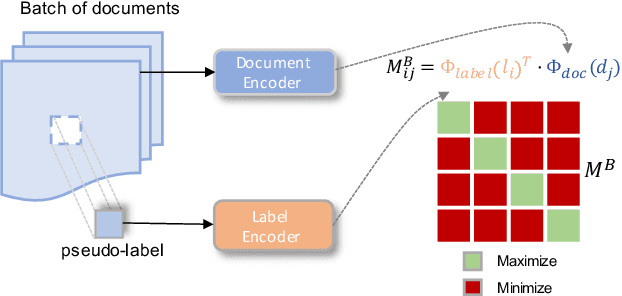


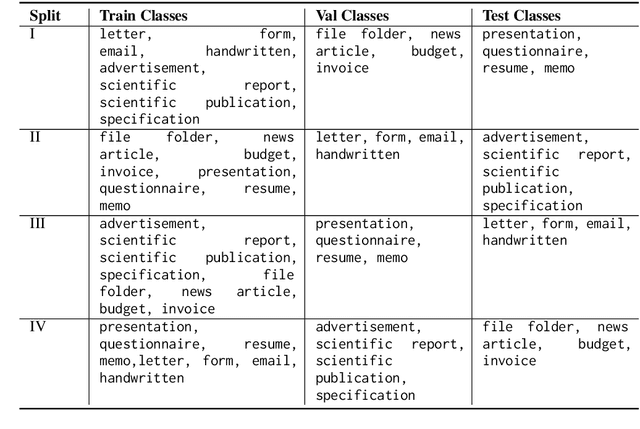
We investigate semi-structured document classification in a zero-shot setting. Classification of semi-structured documents is more challenging than that of standard unstructured documents, as positional, layout, and style information play a vital role in interpreting such documents. The standard classification setting where categories are fixed during both training and testing falls short in dynamic environments where new document categories could potentially emerge. We focus exclusively on the zero-shot setting where inference is done on new unseen classes. To address this task, we propose a matching-based approach that relies on a pairwise contrastive objective for both pretraining and fine-tuning. Our results show a significant boost in Macro F$_1$ from the proposed pretraining step in both supervised and unsupervised zero-shot settings.
Exploring the Role of Task Transferability in Large-Scale Multi-Task Learning
Apr 23, 2022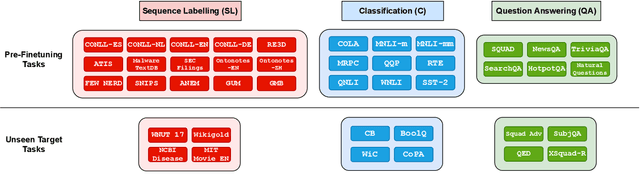
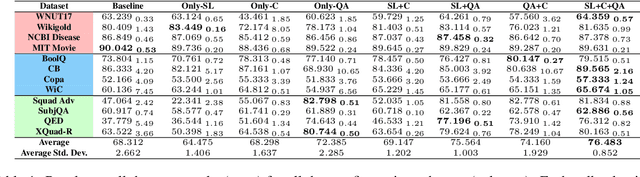
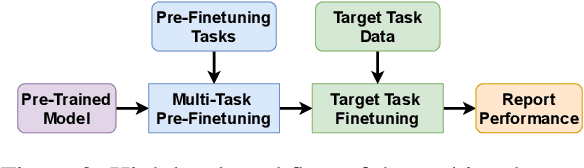

Recent work has found that multi-task training with a large number of diverse tasks can uniformly improve downstream performance on unseen target tasks. In contrast, literature on task transferability has established that the choice of intermediate tasks can heavily affect downstream task performance. In this work, we aim to disentangle the effect of scale and relatedness of tasks in multi-task representation learning. We find that, on average, increasing the scale of multi-task learning, in terms of the number of tasks, indeed results in better learned representations than smaller multi-task setups. However, if the target tasks are known ahead of time, then training on a smaller set of related tasks is competitive to the large-scale multi-task training at a reduced computational cost.
Label Semantics for Few Shot Named Entity Recognition
Mar 16, 2022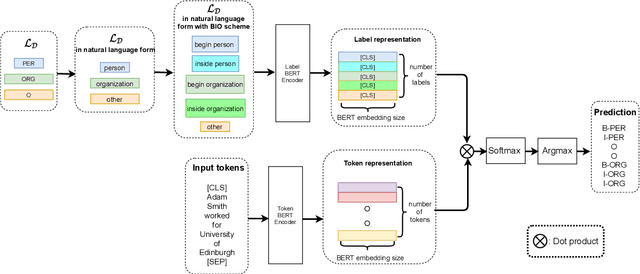
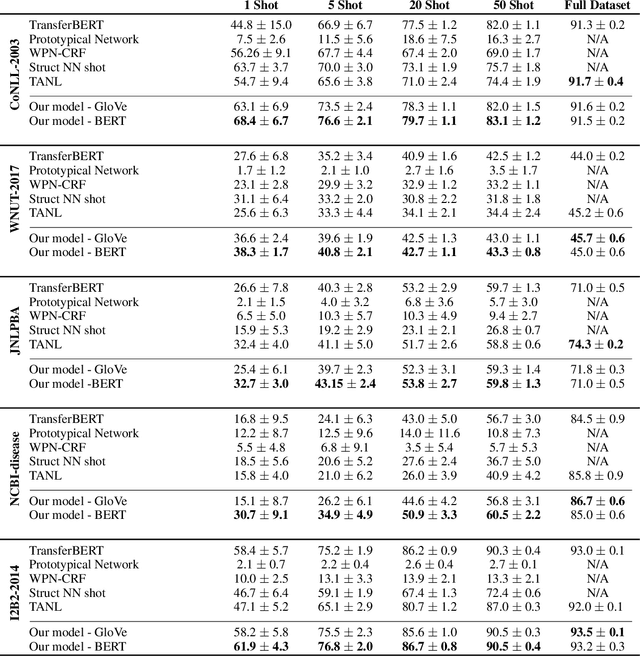
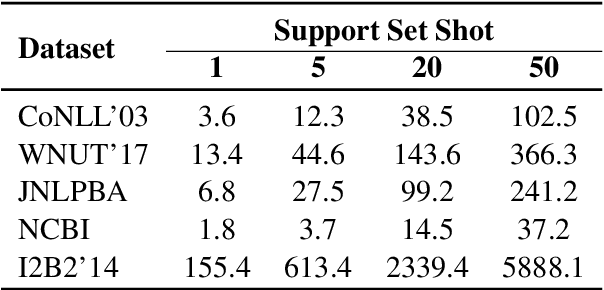
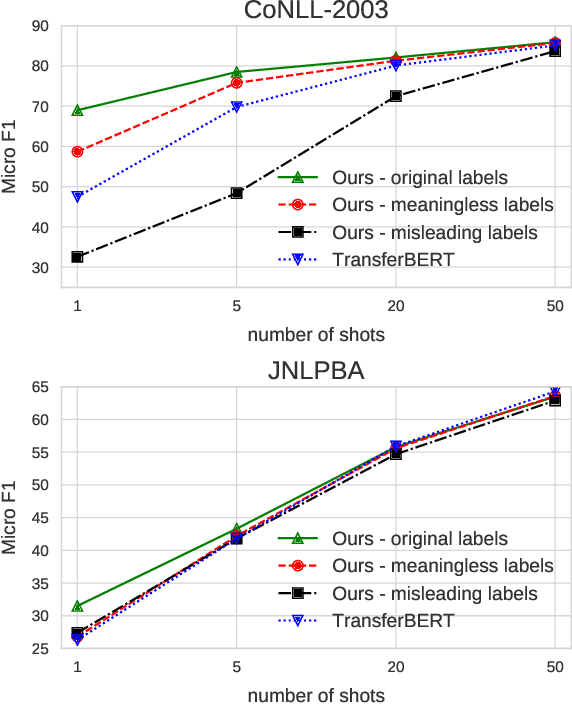
We study the problem of few shot learning for named entity recognition. Specifically, we leverage the semantic information in the names of the labels as a way of giving the model additional signal and enriched priors. We propose a neural architecture that consists of two BERT encoders, one to encode the document and its tokens and another one to encode each of the labels in natural language format. Our model learns to match the representations of named entities computed by the first encoder with label representations computed by the second encoder. The label semantics signal is shown to support improved state-of-the-art results in multiple few shot NER benchmarks and on-par performance in standard benchmarks. Our model is especially effective in low resource settings.
A Bag of Tricks for Dialogue Summarization
Sep 16, 2021
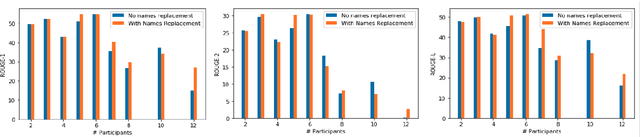


Dialogue summarization comes with its own peculiar challenges as opposed to news or scientific articles summarization. In this work, we explore four different challenges of the task: handling and differentiating parts of the dialogue belonging to multiple speakers, negation understanding, reasoning about the situation, and informal language understanding. Using a pretrained sequence-to-sequence language model, we explore speaker name substitution, negation scope highlighting, multi-task learning with relevant tasks, and pretraining on in-domain data. Our experiments show that our proposed techniques indeed improve summarization performance, outperforming strong baselines.