 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Pretraining with Classification Labels for Temporal Activity Detection
Nov 26, 2021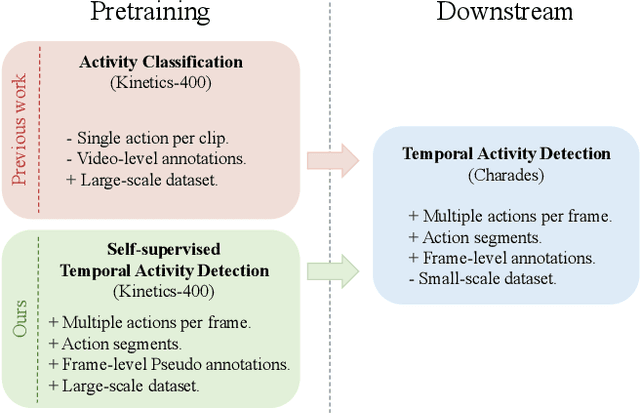
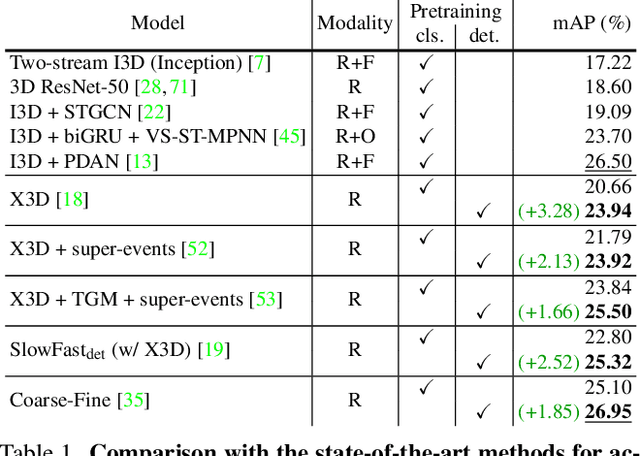
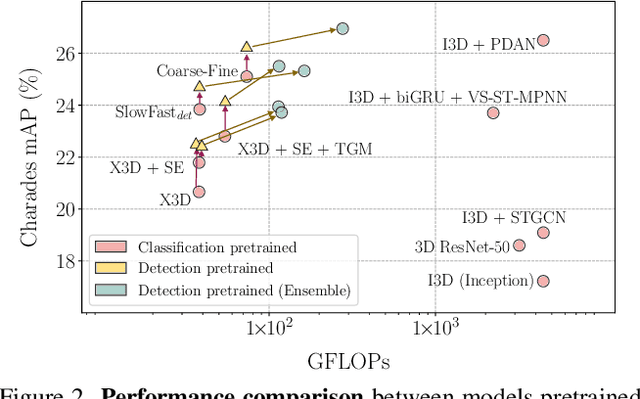
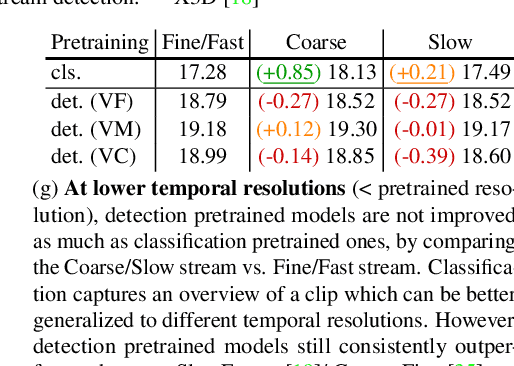
Temporal Activity Detection aims to predict activity classes per frame, in contrast to video-level predictions as done in Activity Classification (i.e., Activity Recognition). Due to the expensive frame-level annotations required for detection, the scale of detection datasets is limited. Thus, commonly, previous work on temporal activity detection resorts to fine-tuning a classification model pretrained on large-scale classification datasets (e.g., Kinetics-400). However, such pretrained models are not ideal for downstream detection performance due to the disparity between the pretraining and the downstream fine-tuning tasks. This work proposes a novel self-supervised pretraining method for detection leveraging classification labels to mitigate such disparity by introducing frame-level pseudo labels, multi-action frames, and action segments. We show that the models pretrained with the proposed self-supervised detection task outperform prior work on multiple challenging activity detection benchmarks, including Charades and MultiTHUMOS. Our extensive ablations further provide insights on when and how to use the proposed models for activity detection. Code and models will be released online.
StARformer: Transformer with State-Action-Reward Representations
Oct 12, 2021
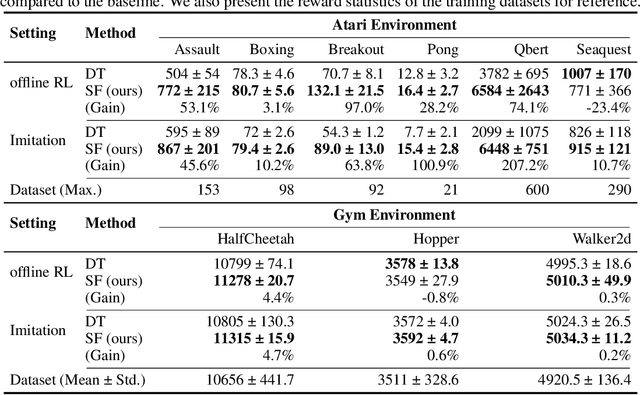
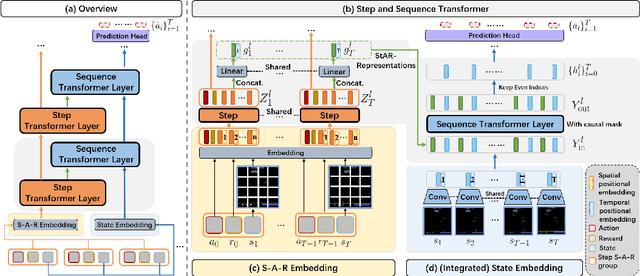
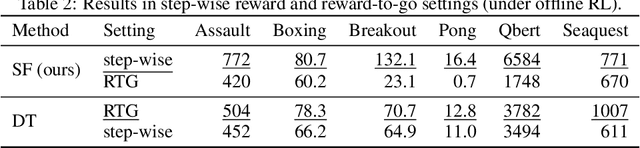
Reinforcement Learning (RL) can be considered as a sequence modeling task, i.e., given a sequence of past state-action-reward experiences, a model autoregressively predicts a sequence of future actions. Recently, Transformers have been successfully adopted to model this problem. In this work, we propose State-Action-Reward Transformer (StARformer), which explicitly models local causal relations to help improve action prediction in long sequences. StARformer first extracts local representations (i.e., StAR-representations) from each group of state-action-reward tokens within a very short time span. A sequence of such local representations combined with state representations, is then used to make action predictions over a long time span. Our experiments show that StARformer outperforms the state-of-the-art Transformer-based method on Atari (image) and Gym (state vector) benchmarks, in both offline-RL and imitation learning settings. StARformer is also more compliant with longer sequences of inputs compared to the baseline. Our code is available at https://github.com/elicassion/StARformer.
4D-Net for Learned Multi-Modal Alignment
Sep 02, 2021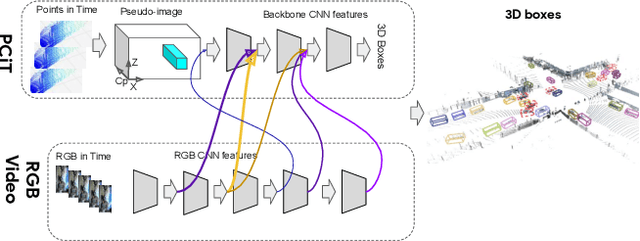
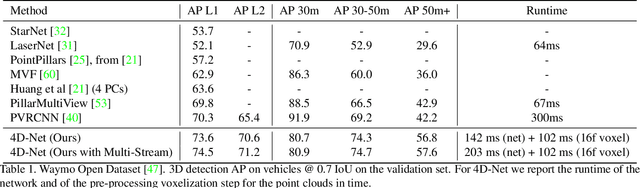
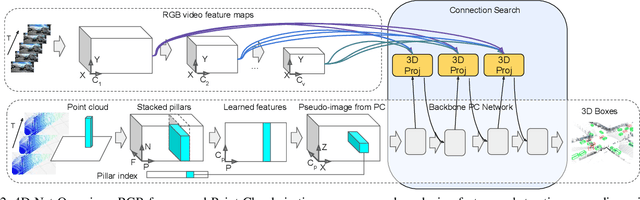
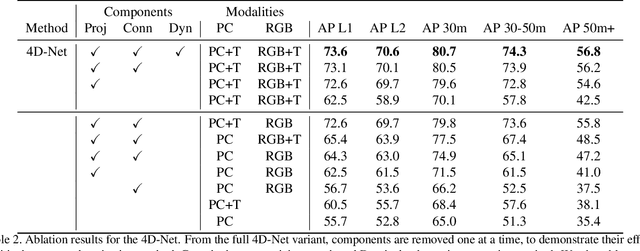
We present 4D-Net, a 3D object detection approach, which utilizes 3D Point Cloud and RGB sensing information, both in time. We are able to incorporate the 4D information by performing a novel dynamic connection learning across various feature representations and levels of abstraction, as well as by observing geometric constraints. Our approach outperforms the state-of-the-art and strong baselines on the Waymo Open Dataset. 4D-Net is better able to use motion cues and dense image information to detect distant objects more successfully.
Self-Supervised Disentangled Representation Learning for Third-Person Imitation Learning
Aug 02, 2021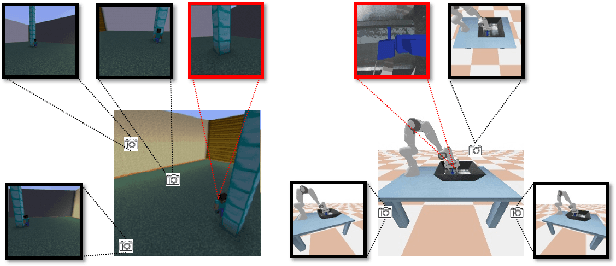
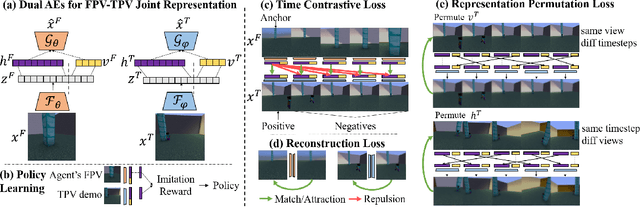
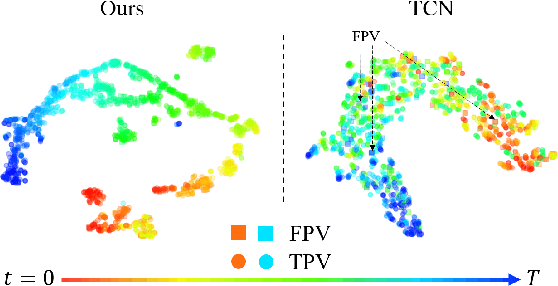
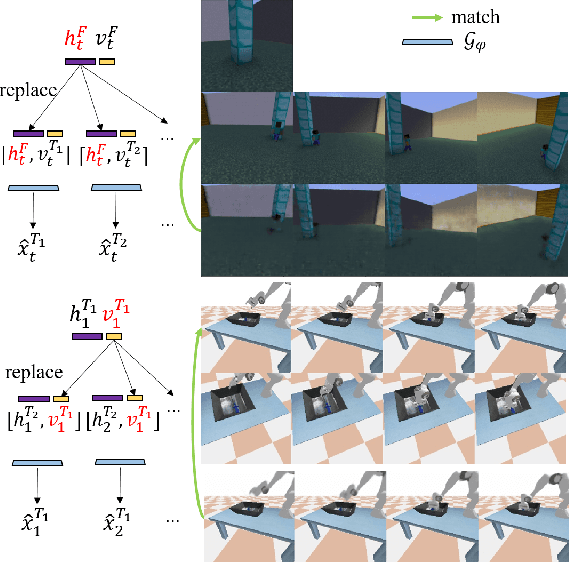
Humans learn to imitate by observing others. However, robot imitation learning generally requires expert demonstrations in the first-person view (FPV). Collecting such FPV videos for every robot could be very expensive. Third-person imitation learning (TPIL) is the concept of learning action policies by observing other agents in a third-person view (TPV), similar to what humans do. This ultimately allows utilizing human and robot demonstration videos in TPV from many different data sources, for the policy learning. In this paper, we present a TPIL approach for robot tasks with egomotion. Although many robot tasks with ground/aerial mobility often involve actions with camera egomotion, study on TPIL for such tasks has been limited. Here, FPV and TPV observations are visually very different; FPV shows egomotion while the agent appearance is only observable in TPV. To enable better state learning for TPIL, we propose our disentangled representation learning method. We use a dual auto-encoder structure plus representation permutation loss and time-contrastive loss to ensure the state and viewpoint representations are well disentangled. Our experiments show the effectiveness of our approach.
Unsupervised Discovery of Actions in Instructional Videos
Jun 28, 2021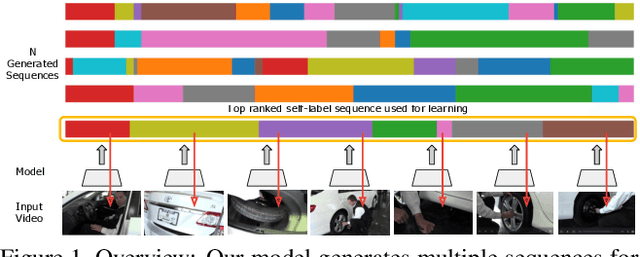
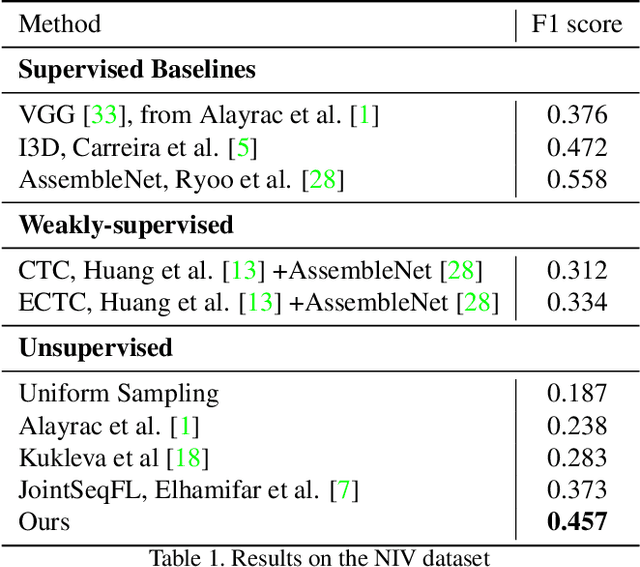
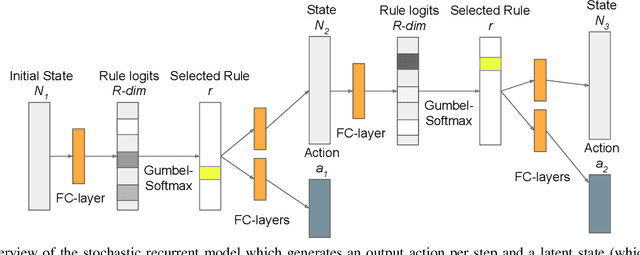
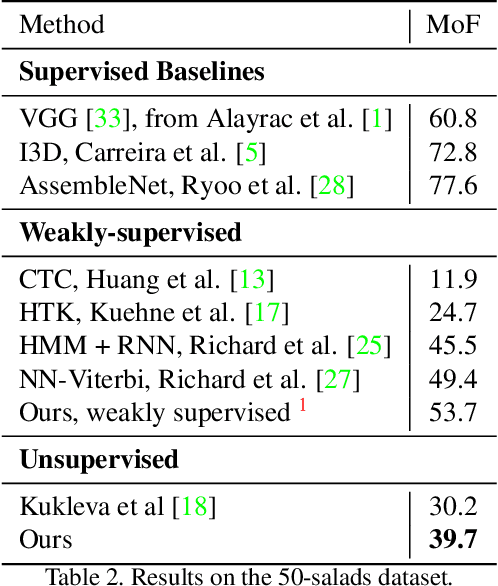
In this paper we address the problem of automatically discovering atomic actions in unsupervised manner from instructional videos. Instructional videos contain complex activities and are a rich source of information for intelligent agents, such as, autonomous robots or virtual assistants, which can, for example, automatically `read' the steps from an instructional video and execute them. However, videos are rarely annotated with atomic activities, their boundaries or duration. We present an unsupervised approach to learn atomic actions of structured human tasks from a variety of instructional videos. We propose a sequential stochastic autoregressive model for temporal segmentation of videos, which learns to represent and discover the sequential relationship between different atomic actions of the task, and which provides automatic and unsupervised self-labeling for videos. Our approach outperforms the state-of-the-art unsupervised methods with large margins. We will open source the code.
TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?
Jun 21, 2021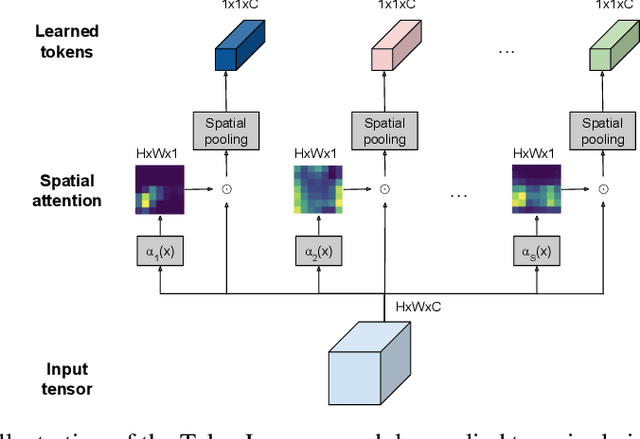
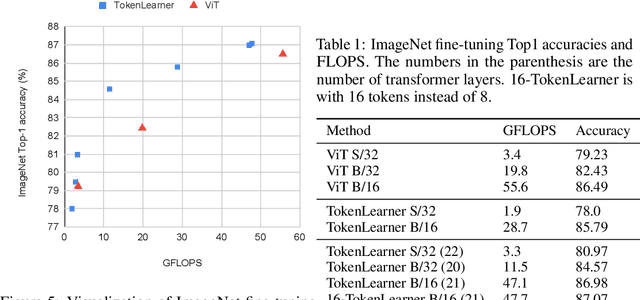
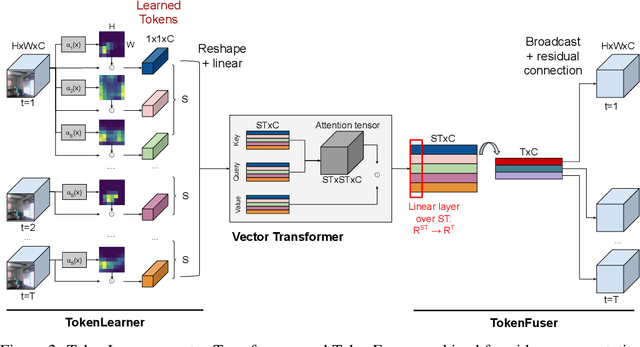

In this paper, we introduce a novel visual representation learning which relies on a handful of adaptively learned tokens, and which is applicable to both image and video understanding tasks. Instead of relying on hand-designed splitting strategies to obtain visual tokens and processing a large number of densely sampled patches for attention, our approach learns to mine important tokens in visual data. This results in efficiently and effectively finding a few important visual tokens and enables modeling of pairwise attention between such tokens, over a longer temporal horizon for videos, or the spatial content in images. Our experiments demonstrate strong performance on several challenging benchmarks for both image and video recognition tasks. Importantly, due to our tokens being adaptive, we accomplish competitive results at significantly reduced compute amount.
Unsupervised Action Segmentation for Instructional Videos
Jun 07, 2021
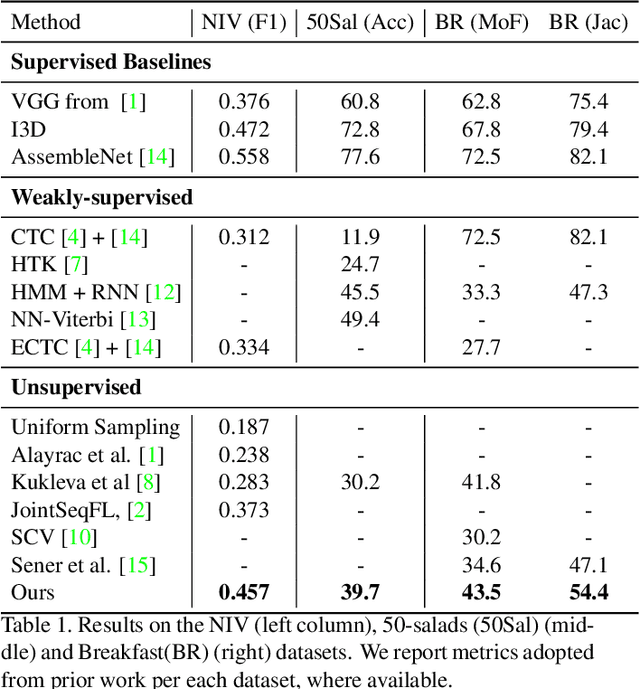
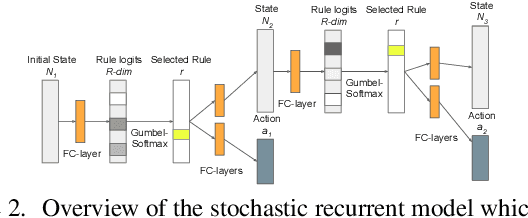
In this paper we address the problem of automatically discovering atomic actions in unsupervised manner from instructional videos, which are rarely annotated with atomic actions. We present an unsupervised approach to learn atomic actions of structured human tasks from a variety of instructional videos based on a sequential stochastic autoregressive model for temporal segmentation of videos. This learns to represent and discover the sequential relationship between different atomic actions of the task, and which provides automatic and unsupervised self-labeling.
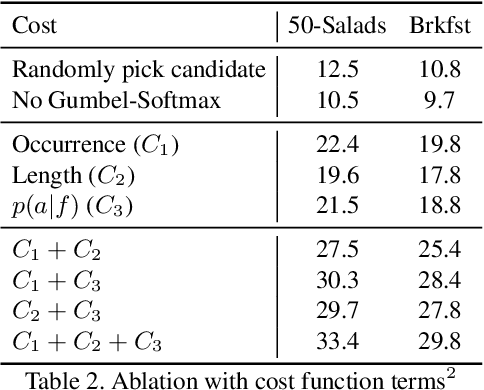
Coarse-Fine Networks for Temporal Activity Detection in Videos
Apr 01, 2021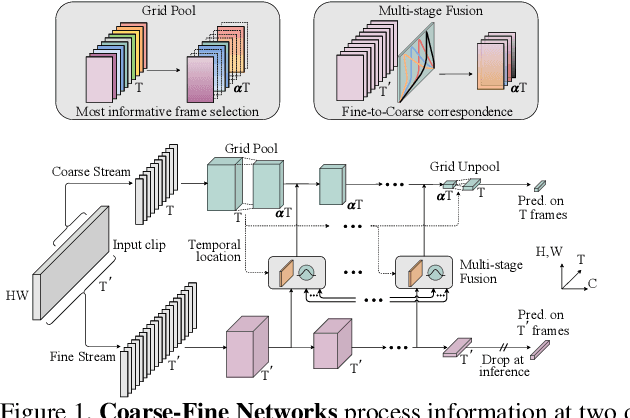
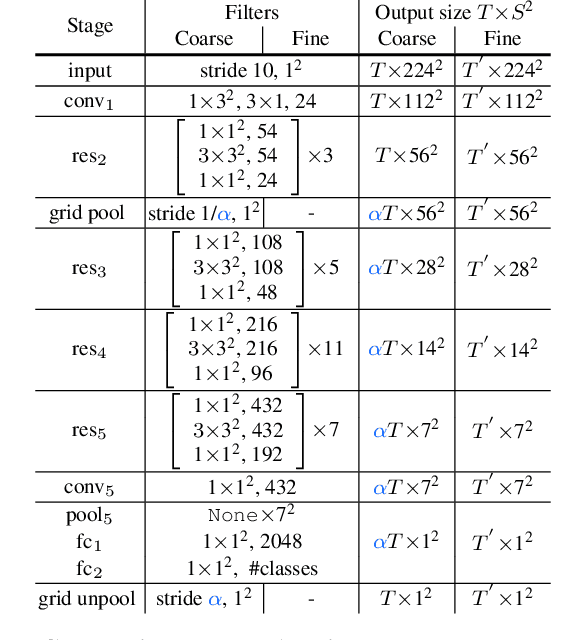
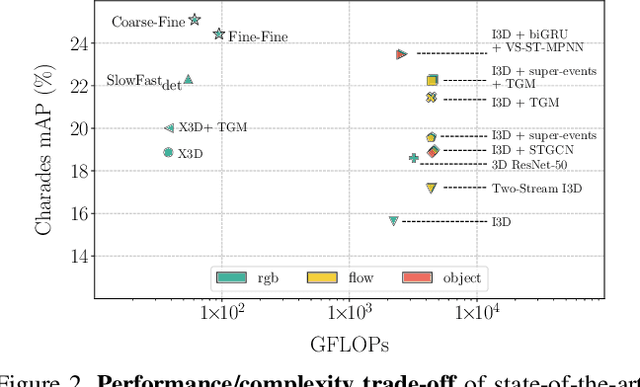
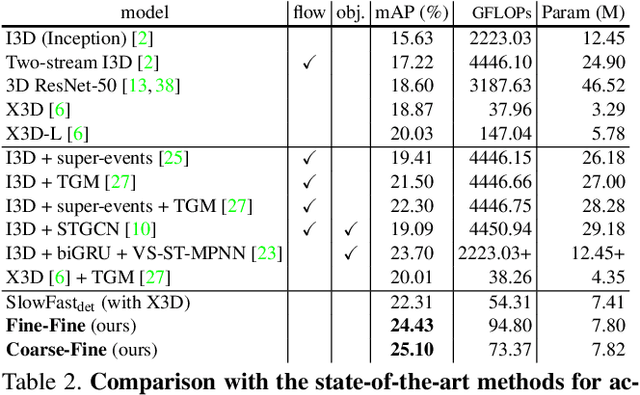
In this paper, we introduce Coarse-Fine Networks, a two-stream architecture which benefits from different abstractions of temporal resolution to learn better video representations for long-term motion. Traditional Video models process inputs at one (or few) fixed temporal resolution without any dynamic frame selection. However, we argue that, processing multiple temporal resolutions of the input and doing so dynamically by learning to estimate the importance of each frame can largely improve video representations, specially in the domain of temporal activity localization. To this end, we propose (1) Grid Pool, a learned temporal downsampling layer to extract coarse features, and, (2) Multi-stage Fusion, a spatio-temporal attention mechanism to fuse a fine-grained context with the coarse features. We show that our method outperforms the state-of-the-arts for action detection in public datasets including Charades with a significantly reduced compute and memory footprint. The code is available at https://github.com/kkahatapitiya/Coarse-Fine-Networks
Recognizing Actions in Videos from Unseen Viewpoints
Mar 30, 2021
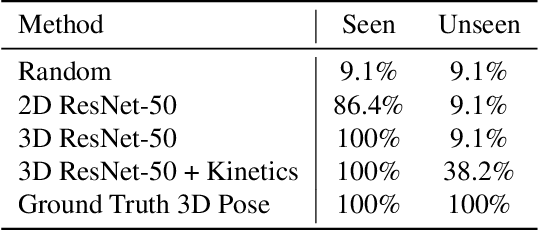
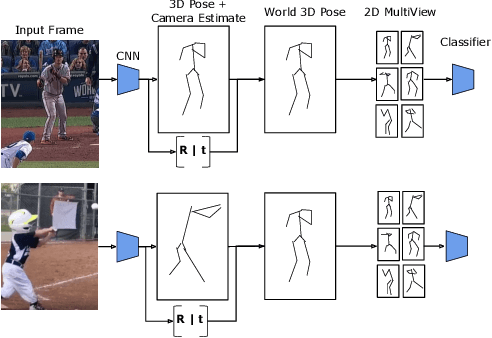
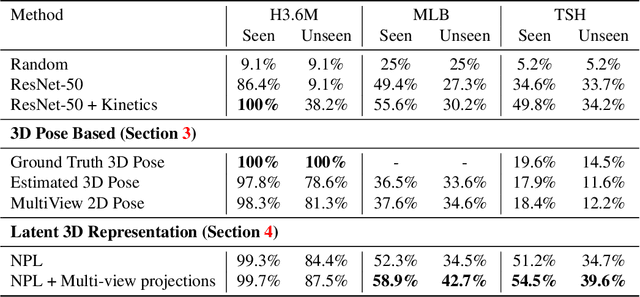
Standard methods for video recognition use large CNNs designed to capture spatio-temporal data. However, training these models requires a large amount of labeled training data, containing a wide variety of actions, scenes, settings and camera viewpoints. In this paper, we show that current convolutional neural network models are unable to recognize actions from camera viewpoints not present in their training data (i.e., unseen view action recognition). To address this, we develop approaches based on 3D representations and introduce a new geometric convolutional layer that can learn viewpoint invariant representations. Further, we introduce a new, challenging dataset for unseen view recognition and show the approaches ability to learn viewpoint invariant representations.
Visionary: Vision architecture discovery for robot learning
Mar 26, 2021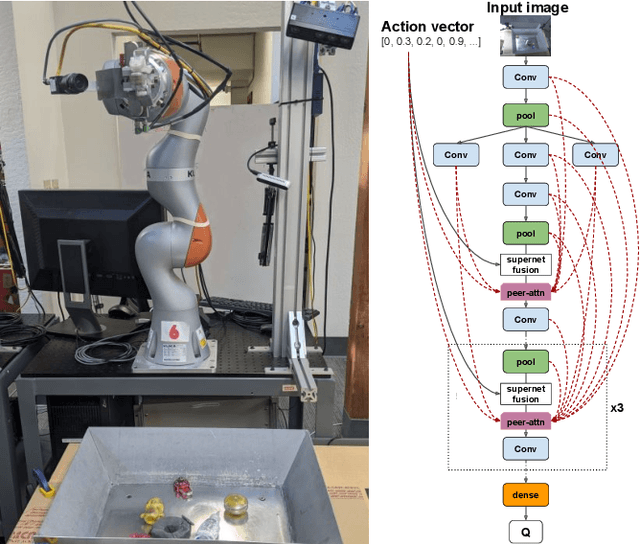
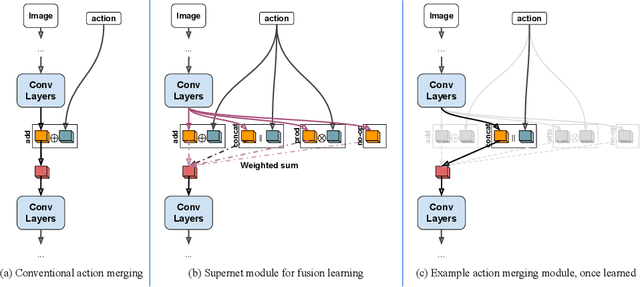
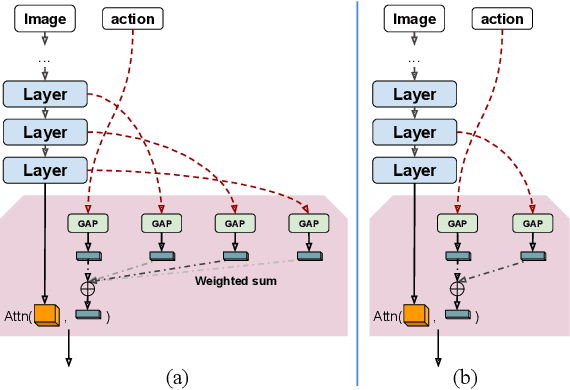
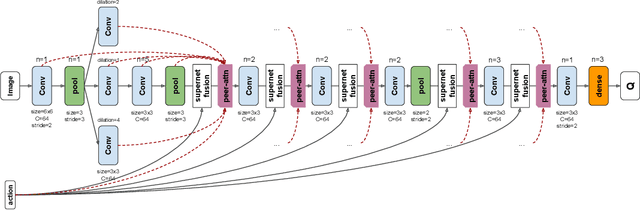
We propose a vision-based architecture search algorithm for robot manipulation learning, which discovers interactions between low dimension action inputs and high dimensional visual inputs. Our approach automatically designs architectures while training on the task - discovering novel ways of combining and attending image feature representations with actions as well as features from previous layers. The obtained new architectures demonstrate better task success rates, in some cases with a large margin, compared to a recent high performing baseline. Our real robot experiments also confirm that it improves grasping performance by 6%. This is the first approach to demonstrate a successful neural architecture search and attention connectivity search for a real-robot task.