 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Aware Auto White Balance in Mobile Photography
Apr 08, 2025



Cameras rely on auto white balance (AWB) to correct undesirable color casts caused by scene illumination and the camera's spectral sensitivity. This is typically achieved using an illuminant estimator that determines the global color cast solely from the color information in the camera's raw sensor image. Mobile devices provide valuable additional metadata-such as capture timestamp and geolocation-that offers strong contextual clues to help narrow down the possible illumination solutions. This paper proposes a lightweight illuminant estimation method that incorporates such contextual metadata, along with additional capture information and image colors, into a compact model (~5K parameters), achieving promising results, matching or surpassing larger models. To validate our method, we introduce a dataset of 3,224 smartphone images with contextual metadata collected at various times of day and under diverse lighting conditions. The dataset includes ground-truth illuminant colors, determined using a color chart, and user-preferred illuminants validated through a user study, providing a comprehensive benchmark for AWB evaluation.
Revisiting Image Fusion for Multi-Illuminant White-Balance Correction
Mar 18, 2025



White balance (WB) correction in scenes with multiple illuminants remains a persistent challenge in computer vision. Recent methods explored fusion-based approaches, where a neural network linearly blends multiple sRGB versions of an input image, each processed with predefined WB presets. However, we demonstrate that these methods are suboptimal for common multi-illuminant scenarios. Additionally, existing fusion-based methods rely on sRGB WB datasets lacking dedicated multi-illuminant images, limiting both training and evaluation. To address these challenges, we introduce two key contributions. First, we propose an efficient transformer-based model that effectively captures spatial dependencies across sRGB WB presets, substantially improving upon linear fusion techniques. Second, we introduce a large-scale multi-illuminant dataset comprising over 16,000 sRGB images rendered with five different WB settings, along with WB-corrected images. Our method achieves up to 100\% improvement over existing techniques on our new multi-illuminant image fusion dataset.
Gain-MLP: Improving HDR Gain Map Encoding via a Lightweight MLP
Mar 14, 2025



While most images shared on the web and social media platforms are encoded in standard dynamic range (SDR), many displays now can accommodate high dynamic range (HDR) content. Additionally, modern cameras can capture images in an HDR format but convert them to SDR to ensure maximum compatibility with existing workflows and legacy displays. To support both SDR and HDR, new encoding formats are emerging that store additional metadata in SDR images in the form of a gain map. When applied to the SDR image, the gain map recovers the HDR version of the image as needed. These gain maps, however, are typically down-sampled and encoded using standard image compression, such as JPEG and HEIC, which can result in unwanted artifacts. In this paper, we propose to use a lightweight multi-layer perceptron (MLP) network to encode the gain map. The MLP is optimized using the SDR image information as input and provides superior performance in terms of HDR reconstruction. Moreover, the MLP-based approach uses a fixed memory footprint (10 KB) and requires no additional adjustments to accommodate different image sizes or encoding parameters. We conduct extensive experiments on various MLP based HDR embedding strategies and demonstrate that our approach outperforms the current state-of-the-art.
Efficient Neural Network Encoding for 3D Color Lookup Tables
Dec 19, 2024



3D color lookup tables (LUTs) enable precise color manipulation by mapping input RGB values to specific output RGB values. 3D LUTs are instrumental in various applications, including video editing, in-camera processing, photographic filters, computer graphics, and color processing for displays. While an individual LUT does not incur a high memory overhead, software and devices may need to store dozens to hundreds of LUTs that can take over 100 MB. This work aims to develop a neural network architecture that can encode hundreds of LUTs in a single compact representation. To this end, we propose a model with a memory footprint of less than 0.25 MB that can reconstruct 512 LUTs with only minor color distortion ($\bar{\Delta}E_M$ $\leq$ 2.0) over the entire color gamut. We also show that our network can weight colors to provide further quality gains on natural image colors ($\bar{\Delta}{E}_M$ $\leq$ 1.0). Finally, we show that minor modifications to the network architecture enable a bijective encoding that produces LUTs that are invertible, allowing for reverse color processing. Our code is available at https://github.com/vahidzee/ennelut.
NamedCurves: Learned Image Enhancement via Color Naming
Jul 13, 2024



A popular method for enhancing images involves learning the style of a professional photo editor using pairs of training images comprised of the original input with the editor-enhanced version. When manipulating images, many editing tools offer a feature that allows the user to manipulate a limited selection of familiar colors. Editing by color name allows easy adjustment of elements like the "blue" of the sky or the "green" of trees. Inspired by this approach to color manipulation, we propose NamedCurves, a learning-based image enhancement technique that separates the image into a small set of named colors. Our method learns to globally adjust the image for each specific named color via tone curves and then combines the images using an attention-based fusion mechanism to mimic spatial editing. We demonstrate the effectiveness of our method against several competing methods on the well-known Adobe 5K dataset and the PPR10K dataset, showing notable improvements.
Examining Autoexposure for Challenging Scenes
Sep 08, 2023



Autoexposure (AE) is a critical step applied by camera systems to ensure properly exposed images. While current AE algorithms are effective in well-lit environments with constant illumination, these algorithms still struggle in environments with bright light sources or scenes with abrupt changes in lighting. A significant hurdle in developing new AE algorithms for challenging environments, especially those with time-varying lighting, is the lack of suitable image datasets. To address this issue, we have captured a new 4D exposure dataset that provides a large solution space (i.e., shutter speed range from (1/500 to 15 seconds) over a temporal sequence with moving objects, bright lights, and varying lighting. In addition, we have designed a software platform to allow AE algorithms to be used in a plug-and-play manner with the dataset. Our dataset and associate platform enable repeatable evaluation of different AE algorithms and provide a much-needed starting point to develop better AE methods. We examine several existing AE strategies using our dataset and show that most users prefer a simple saliency method for challenging lighting conditions.
NILUT: Conditional Neural Implicit 3D Lookup Tables for Image Enhancement
Jun 20, 20233D lookup tables (3D LUTs) are a key component for image enhancement. Modern image signal processors (ISPs) have dedicated support for these as part of the camera rendering pipeline. Cameras typically provide multiple options for picture styles, where each style is usually obtained by applying a unique handcrafted 3D LUT. Current approaches for learning and applying 3D LUTs are notably fast, yet not so memory-efficient, as storing multiple 3D LUTs is required. For this reason and other implementation limitations, their use on mobile devices is less popular. In this work, we propose a Neural Implicit LUT (NILUT), an implicitly defined continuous 3D color transformation parameterized by a neural network. We show that NILUTs are capable of accurately emulating real 3D LUTs. Moreover, a NILUT can be extended to incorporate multiple styles into a single network with the ability to blend styles implicitly. Our novel approach is memory-efficient, controllable and can complement previous methods, including learned ISPs. Code, models and dataset available at: https://github.com/mv-lab/nilut
GamutMLP: A Lightweight MLP for Color Loss Recovery
Apr 23, 2023Cameras and image-editing software often process images in the wide-gamut ProPhoto color space, encompassing 90% of all visible colors. However, when images are encoded for sharing, this color-rich representation is transformed and clipped to fit within the small-gamut standard RGB (sRGB) color space, representing only 30% of visible colors. Recovering the lost color information is challenging due to the clipping procedure. Inspired by neural implicit representations for 2D images, we propose a method that optimizes a lightweight multi-layer-perceptron (MLP) model during the gamut reduction step to predict the clipped values. GamutMLP takes approximately 2 seconds to optimize and requires only 23 KB of storage. The small memory footprint allows our GamutMLP model to be saved as metadata in the sRGB image -- the model can be extracted when needed to restore wide-gamut color values. We demonstrate the effectiveness of our approach for color recovery and compare it with alternative strategies, including pre-trained DNN-based gamut expansion networks and other implicit neural representation methods. As part of this effort, we introduce a new color gamut dataset of 2200 wide-gamut/small-gamut images for training and testing. Our code and dataset can be found on the project website: https://gamut-mlp.github.io.
TransCC: Transformer-based Multiple Illuminant Color Constancy Using Multitask Learning
Nov 16, 2022
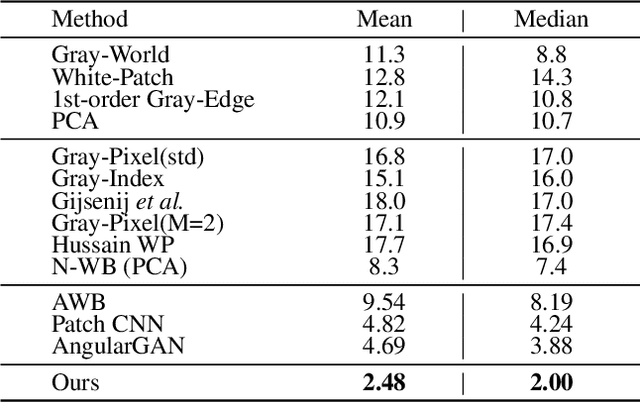
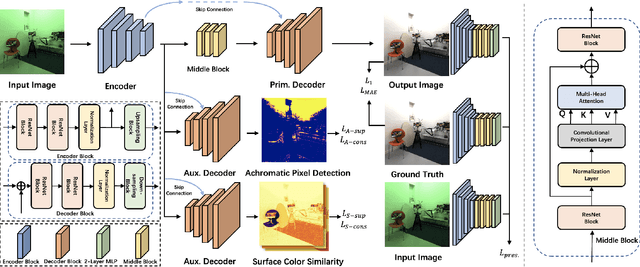

Multi-illuminant color constancy is a challenging problem with only a few existing methods. For example, one prior work used a small set of predefined white balance settings and spatially blended among them, limiting the solution to predefined illuminations. Another method proposed a generative adversarial network and an angular loss, yet the performance is suboptimal due to the lack of regularization for multi-illumination colors. This paper introduces a transformer-based multi-task learning method to estimate single and multiple light colors from a single input image. To help our deep learning model have better cues of the light colors, achromatic-pixel detection, and edge detection are used as auxiliary tasks in our multi-task learning setting. By exploiting extracted content features from the input image as tokens, illuminant color correlations between pixels are learned by leveraging contextual information in our transformer. Our transformer approach is further assisted via a contrastive loss defined between the input, output, and ground truth. We demonstrate that our proposed model achieves 40.7% improvement compared to a state-of-the-art multi-illuminant color constancy method on a multi-illuminant dataset (LSMI). Moreover, our model maintains a robust performance on the single illuminant dataset (NUS-8) and provides 22.3% improvement on the state-of-the-art single color constancy method.
Day-to-Night Image Synthesis for Training Nighttime Neural ISPs
Jun 06, 2022
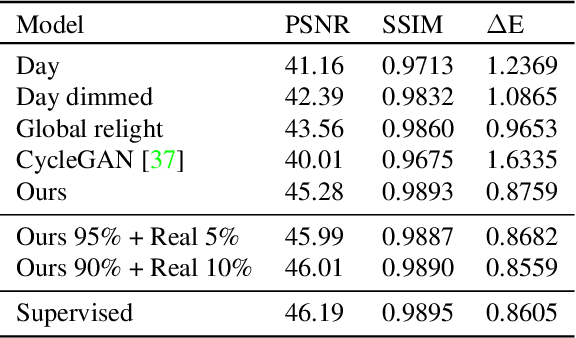

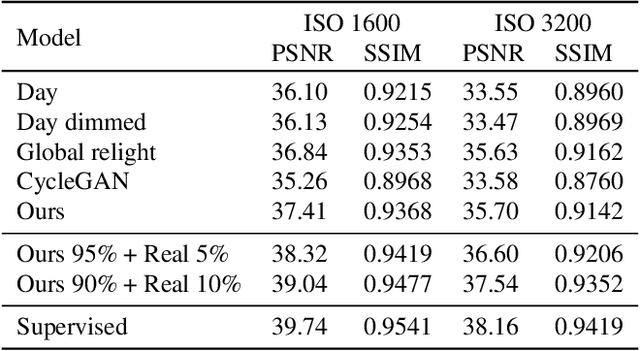
Many flagship smartphone cameras now use a dedicated neural image signal processor (ISP) to render noisy raw sensor images to the final processed output. Training nightmode ISP networks relies on large-scale datasets of image pairs with: (1) a noisy raw image captured with a short exposure and a high ISO gain; and (2) a ground truth low-noise raw image captured with a long exposure and low ISO that has been rendered through the ISP. Capturing such image pairs is tedious and time-consuming, requiring careful setup to ensure alignment between the image pairs. In addition, ground truth images are often prone to motion blur due to the long exposure. To address this problem, we propose a method that synthesizes nighttime images from daytime images. Daytime images are easy to capture, exhibit low-noise (even on smartphone cameras) and rarely suffer from motion blur. We outline a processing framework to convert daytime raw images to have the appearance of realistic nighttime raw images with different levels of noise. Our procedure allows us to easily produce aligned noisy and clean nighttime image pairs. We show the effectiveness of our synthesis framework by training neural ISPs for nightmode rendering. Furthermore, we demonstrate that using our synthetic nighttime images together with small amounts of real data (e.g., 5% to 10%) yields performance almost on par with training exclusively on real nighttime images. Our dataset and code are available at https://github.com/SamsungLabs/day-to-night.