 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Induce Causal Structure
Apr 11, 2022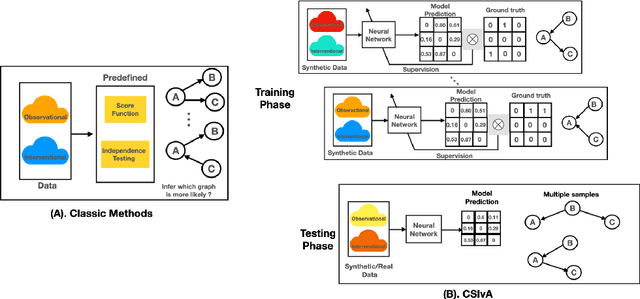
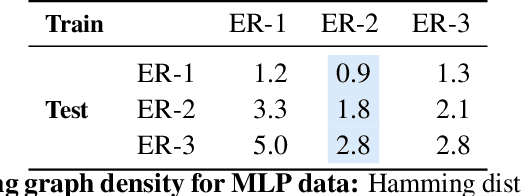
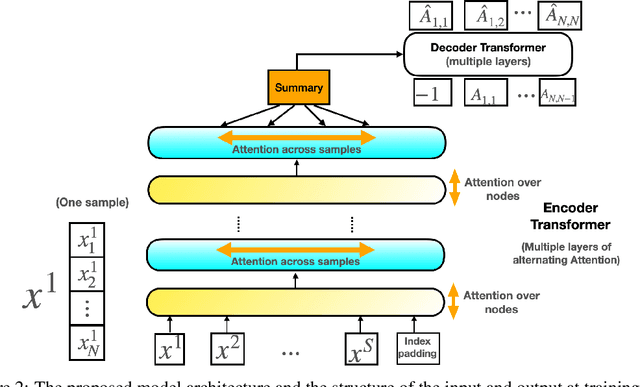
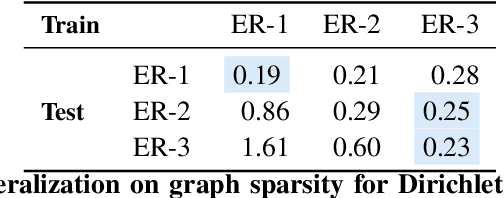
The fundamental challenge in causal induction is to infer the underlying graph structure given observational and/or interventional data. Most existing causal induction algorithms operate by generating candidate graphs and then evaluating them using either score-based methods (including continuous optimization) or independence tests. In this work, instead of proposing scoring function or independence tests, we treat the inference process as a black box and design a neural network architecture that learns the mapping from both observational and interventional data to graph structures via supervised training on synthetic graphs. We show that the proposed model generalizes not only to new synthetic graphs but also to naturalistic graphs.
Systematic Evaluation of Causal Discovery in Visual Model Based Reinforcement Learning
Jul 02, 2021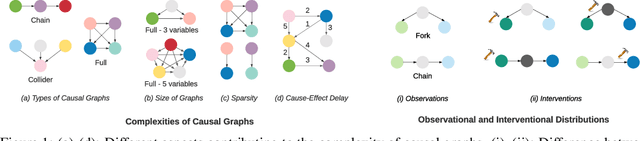
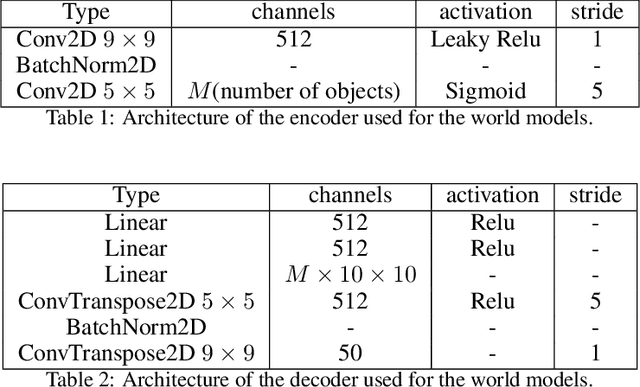
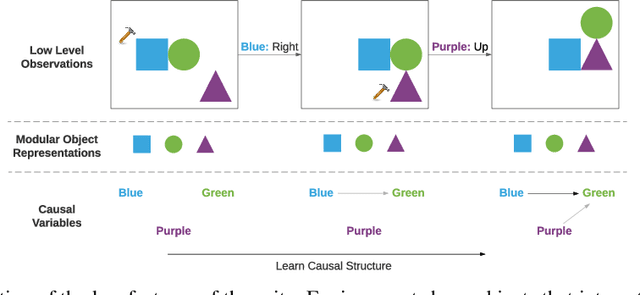
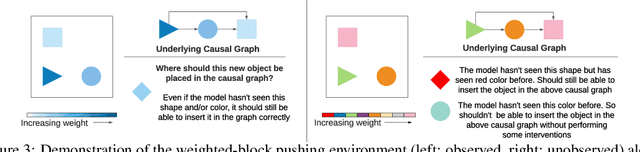
Inducing causal relationships from observations is a classic problem in machine learning. Most work in causality starts from the premise that the causal variables themselves are observed. However, for AI agents such as robots trying to make sense of their environment, the only observables are low-level variables like pixels in images. To generalize well, an agent must induce high-level variables, particularly those which are causal or are affected by causal variables. A central goal for AI and causality is thus the joint discovery of abstract representations and causal structure. However, we note that existing environments for studying causal induction are poorly suited for this objective because they have complicated task-specific causal graphs which are impossible to manipulate parametrically (e.g., number of nodes, sparsity, causal chain length, etc.). In this work, our goal is to facilitate research in learning representations of high-level variables as well as causal structures among them. In order to systematically probe the ability of methods to identify these variables and structures, we design a suite of benchmarking RL environments. We evaluate various representation learning algorithms from the literature and find that explicitly incorporating structure and modularity in models can help causal induction in model-based reinforcement learning.
Neural Production Systems
Mar 02, 2021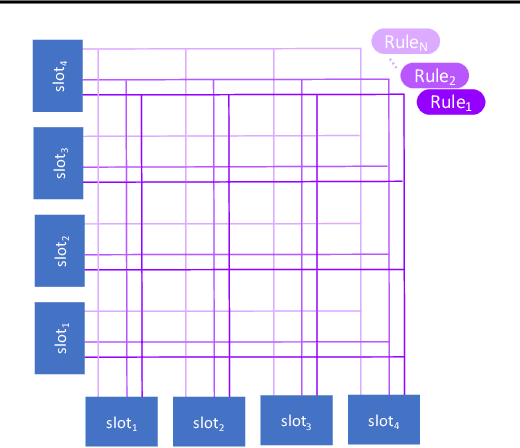

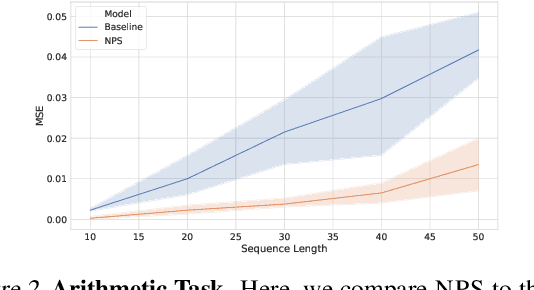
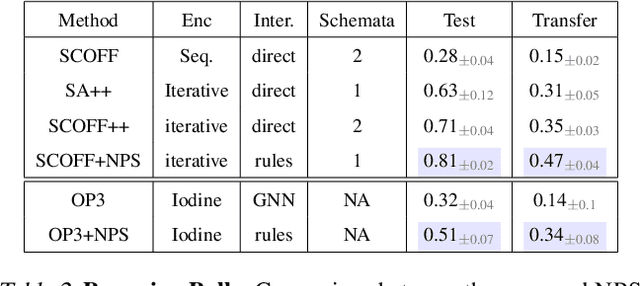
Visual environments are structured, consisting of distinct objects or entities. These entities have properties -- both visible and latent -- that determine the manner in which they interact with one another. To partition images into entities, deep-learning researchers have proposed structural inductive biases such as slot-based architectures. To model interactions among entities, equivariant graph neural nets (GNNs) are used, but these are not particularly well suited to the task for two reasons. First, GNNs do not predispose interactions to be sparse, as relationships among independent entities are likely to be. Second, GNNs do not factorize knowledge about interactions in an entity-conditional manner. As an alternative, we take inspiration from cognitive science and resurrect a classic approach, production systems, which consist of a set of rule templates that are applied by binding placeholder variables in the rules to specific entities. Rules are scored on their match to entities, and the best fitting rules are applied to update entity properties. In a series of experiments, we demonstrate that this architecture achieves a flexible, dynamic flow of control and serves to factorize entity-specific and rule-based information. This disentangling of knowledge achieves robust future-state prediction in rich visual environments, outperforming state-of-the-art methods using GNNs, and allows for the extrapolation from simple (few object) environments to more complex environments.
Coordination Among Neural Modules Through a Shared Global Workspace
Mar 01, 2021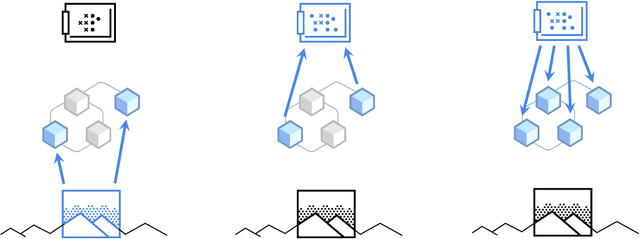
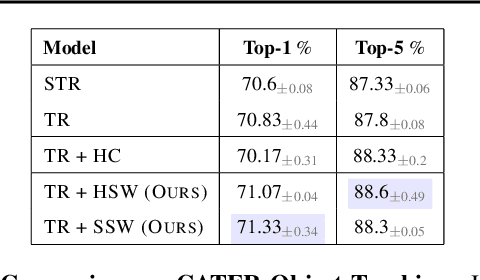
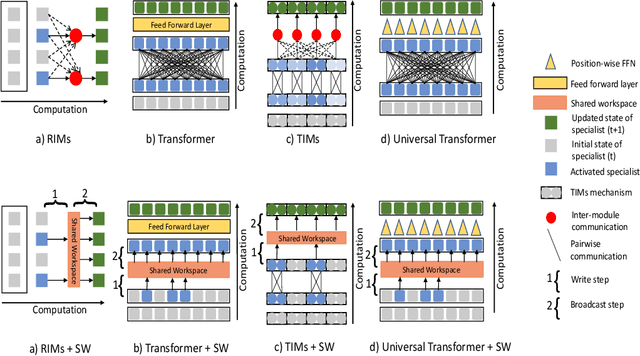
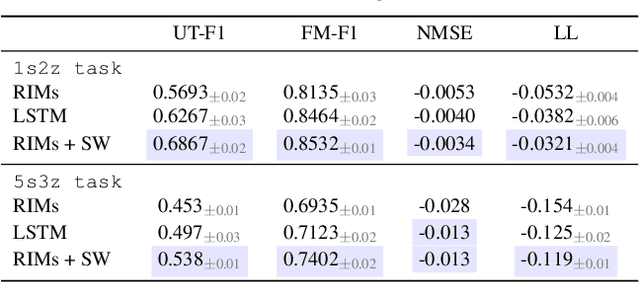
Deep learning has seen a movement away from representing examples with a monolithic hidden state towards a richly structured state. For example, Transformers segment by position, and object-centric architectures decompose images into entities. In all these architectures, interactions between different elements are modeled via pairwise interactions: Transformers make use of self-attention to incorporate information from other positions; object-centric architectures make use of graph neural networks to model interactions among entities. However, pairwise interactions may not achieve global coordination or a coherent, integrated representation that can be used for downstream tasks. In cognitive science, a global workspace architecture has been proposed in which functionally specialized components share information through a common, bandwidth-limited communication channel. We explore the use of such a communication channel in the context of deep learning for modeling the structure of complex environments. The proposed method includes a shared workspace through which communication among different specialist modules takes place but due to limits on the communication bandwidth, specialist modules must compete for access. We show that capacity limitations have a rational basis in that (1) they encourage specialization and compositionality and (2) they facilitate the synchronization of otherwise independent specialists.
Neural Function Modules with Sparse Arguments: A Dynamic Approach to Integrating Information across Layers
Oct 15, 2020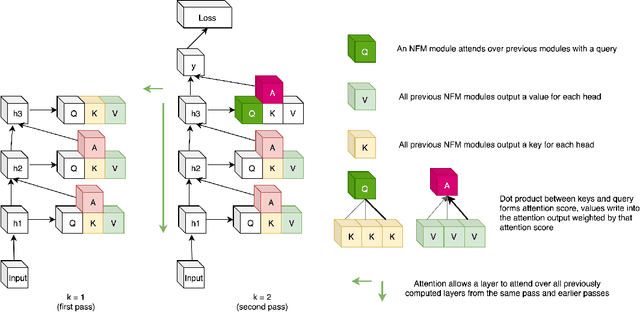


Feed-forward neural networks consist of a sequence of layers, in which each layer performs some processing on the information from the previous layer. A downside to this approach is that each layer (or module, as multiple modules can operate in parallel) is tasked with processing the entire hidden state, rather than a particular part of the state which is most relevant for that module. Methods which only operate on a small number of input variables are an essential part of most programming languages, and they allow for improved modularity and code re-usability. Our proposed method, Neural Function Modules (NFM), aims to introduce the same structural capability into deep learning. Most of the work in the context of feed-forward networks combining top-down and bottom-up feedback is limited to classification problems. The key contribution of our work is to combine attention, sparsity, top-down and bottom-up feedback, in a flexible algorithm which, as we show, improves the results in standard classification, out-of-domain generalization, generative modeling, and learning representations in the context of reinforcement learning.
Object Files and Schemata: Factorizing Declarative and Procedural Knowledge in Dynamical Systems
Jun 30, 2020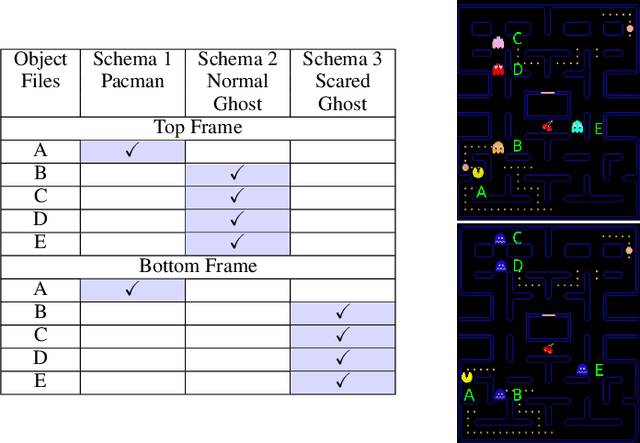
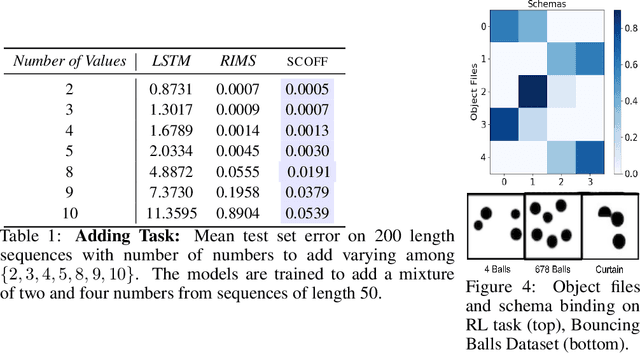
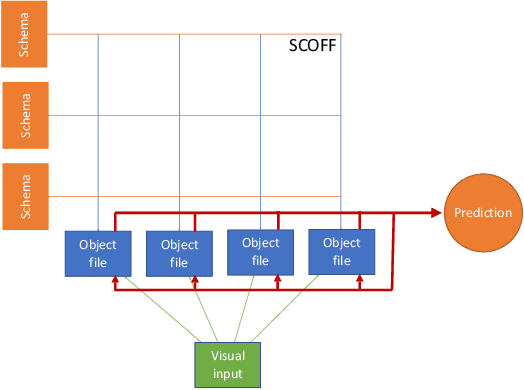

Modeling a structured, dynamic environment like a video game requires keeping track of the objects and their states (\emph{declarative} knowledge) as well as predicting how objects behave (\emph{procedural} knowledge). Black-box models with a monolithic hidden state often lack \emph{systematicity}: they fail to apply procedural knowledge consistently and uniformly. For example, in a video game, correct prediction of one enemy's trajectory does not ensure correct prediction of another's. We address this issue via an architecture that factorizes declarative and procedural knowledge and that imposes modularity within each form of knowledge. The architecture consists of active modules called \emph{object files} that maintain the state of a single object and invoke passive external knowledge sources called \emph{schemata} that prescribe state updates. To use a video game as an illustration, two enemies of the same type will share schemata but will each have their own object file to encode their distinct state (e.g., health, position). We propose to use attention to control the determination of which object files to update, the selection of schemata, and the propagation of information between object files. The resulting architecture is a drop-in replacement conforming to the same input-output interface as normal recurrent networks (e.g., LSTM, GRU) yet achieves substantially better generalization on environments that have factorized declarative and procedural knowledge, including a challenging intuitive physics benchmark.
Learning to Combine Top-Down and Bottom-Up Signals in Recurrent Neural Networks with Attention over Modules
Jun 30, 2020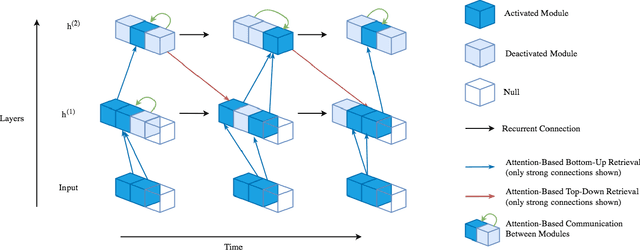
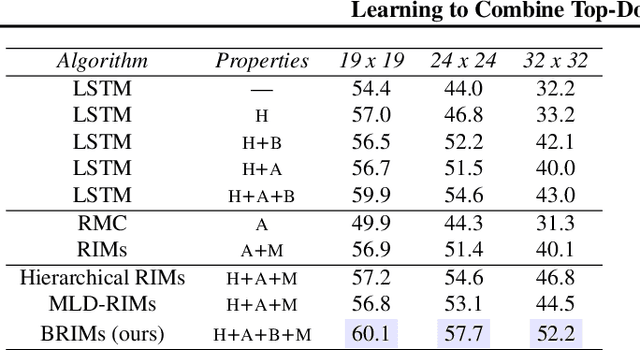
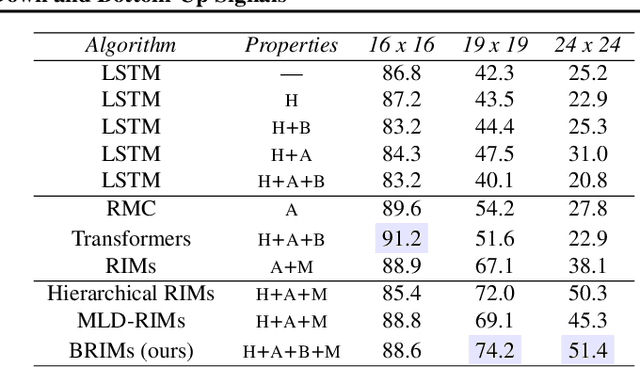
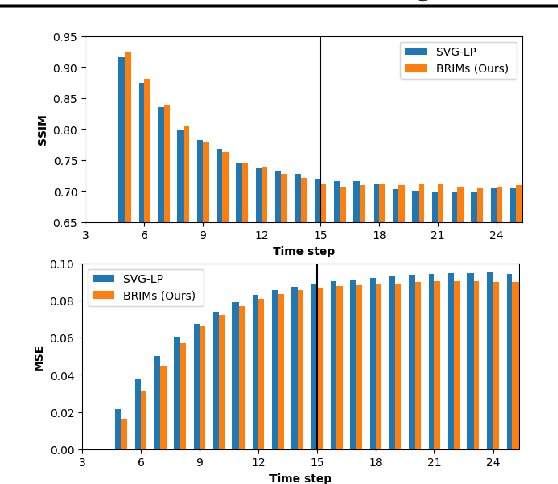
Robust perception relies on both bottom-up and top-down signals. Bottom-up signals consist of what's directly observed through sensation. Top-down signals consist of beliefs and expectations based on past experience and short-term memory, such as how the phrase `peanut butter and~...' will be completed. The optimal combination of bottom-up and top-down information remains an open question, but the manner of combination must be dynamic and both context and task dependent. To effectively utilize the wealth of potential top-down information available, and to prevent the cacophony of intermixed signals in a bidirectional architecture, mechanisms are needed to restrict information flow. We explore deep recurrent neural net architectures in which bottom-up and top-down signals are dynamically combined using attention. Modularity of the architecture further restricts the sharing and communication of information. Together, attention and modularity direct information flow, which leads to reliable performance improvements in perceptual and language tasks, and in particular improves robustness to distractions and noisy data. We demonstrate on a variety of benchmarks in language modeling, sequential image classification, video prediction and reinforcement learning that the \emph{bidirectional} information flow can improve results over strong baselines.