 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotic behavior of $\ell_p$-based Laplacian regularization in semi-supervised learning
Mar 02, 2016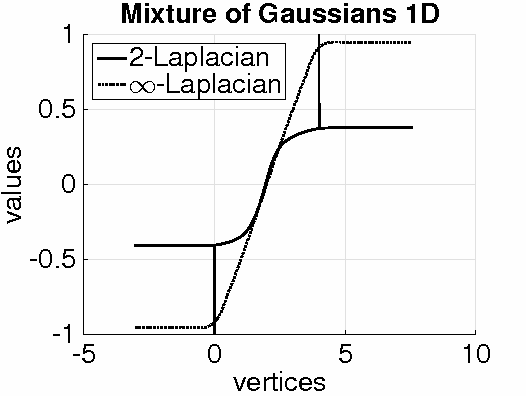
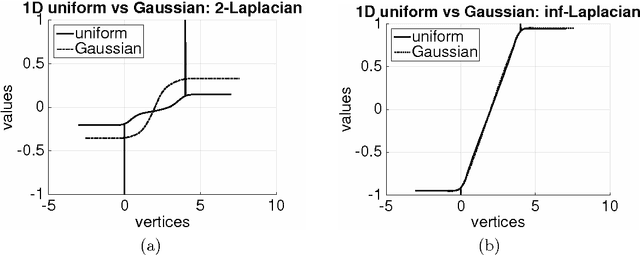
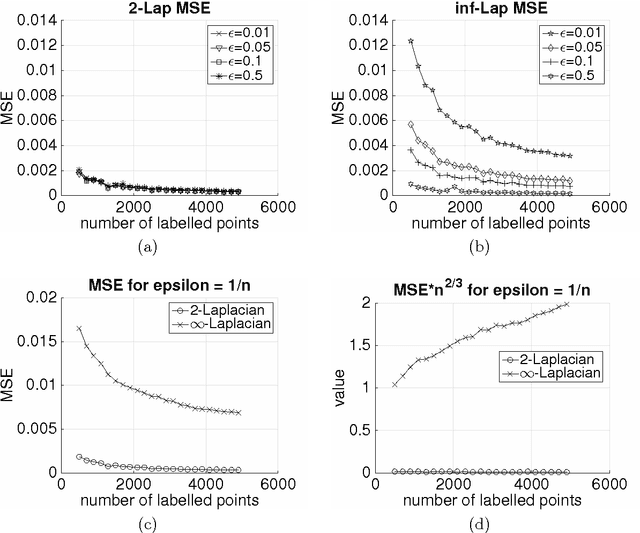
Given a weighted graph with $N$ vertices, consider a real-valued regression problem in a semi-supervised setting, where one observes $n$ labeled vertices, and the task is to label the remaining ones. We present a theoretical study of $\ell_p$-based Laplacian regularization under a $d$-dimensional geometric random graph model. We provide a variational characterization of the performance of this regularized learner as $N$ grows to infinity while $n$ stays constant, the associated optimality conditions lead to a partial differential equation that must be satisfied by the associated function estimate $\hat{f}$. From this formulation we derive several predictions on the limiting behavior the $d$-dimensional function $\hat{f}$, including (a) a phase transition in its smoothness at the threshold $p = d + 1$, and (b) a tradeoff between smoothness and sensitivity to the underlying unlabeled data distribution $P$. Thus, over the range $p \leq d$, the function estimate $\hat{f}$ is degenerate and "spiky," whereas for $p\geq d+1$, the function estimate $\hat{f}$ is smooth. We show that the effect of the underlying density vanishes monotonically with $p$, such that in the limit $p = \infty$, corresponding to the so-called Absolutely Minimal Lipschitz Extension, the estimate $\hat{f}$ is independent of the distribution $P$. Under the assumption of semi-supervised smoothness, ignoring $P$ can lead to poor statistical performance, in particular, we construct a specific example for $d=1$ to demonstrate that $p=2$ has lower risk than $p=\infty$ due to the former penalty adapting to $P$ and the latter ignoring it. We also provide simulations that verify the accuracy of our predictions for finite sample sizes. Together, these properties show that $p = d+1$ is an optimal choice, yielding a function estimate $\hat{f}$ that is both smooth and non-degenerate, while remaining maximally sensitive to $P$.
SparkNet: Training Deep Networks in Spark
Feb 28, 2016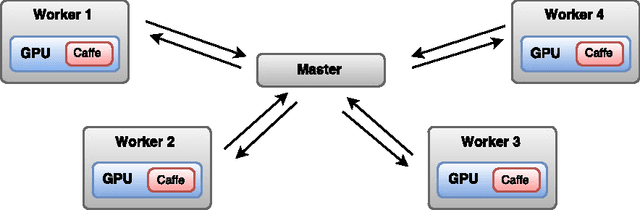
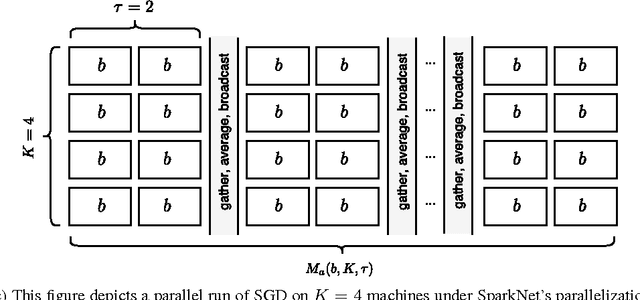
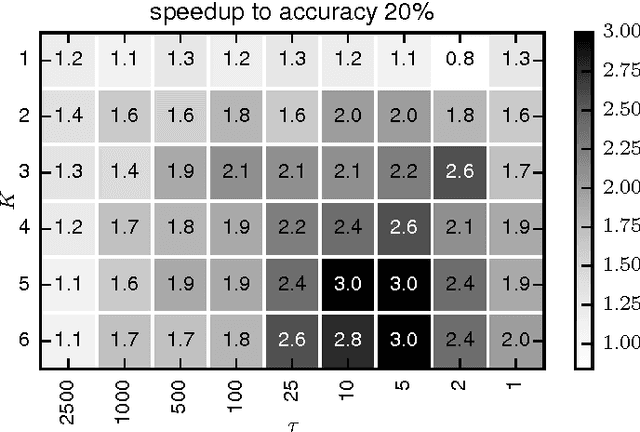
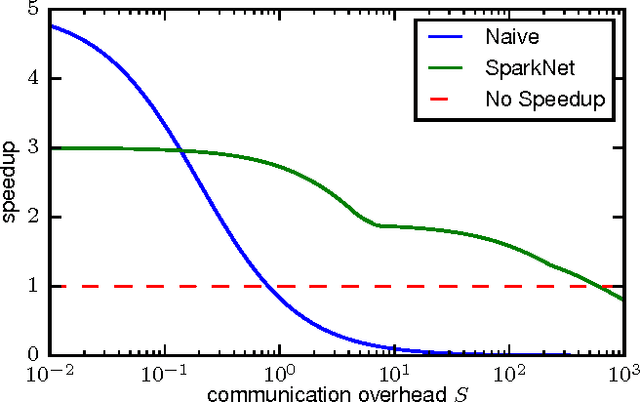
Training deep networks is a time-consuming process, with networks for object recognition often requiring multiple days to train. For this reason, leveraging the resources of a cluster to speed up training is an important area of work. However, widely-popular batch-processing computational frameworks like MapReduce and Spark were not designed to support the asynchronous and communication-intensive workloads of existing distributed deep learning systems. We introduce SparkNet, a framework for training deep networks in Spark. Our implementation includes a convenient interface for reading data from Spark RDDs, a Scala interface to the Caffe deep learning framework, and a lightweight multi-dimensional tensor library. Using a simple parallelization scheme for stochastic gradient descent, SparkNet scales well with the cluster size and tolerates very high-latency communication. Furthermore, it is easy to deploy and use with no parameter tuning, and it is compatible with existing Caffe models. We quantify the dependence of the speedup obtained by SparkNet on the number of machines, the communication frequency, and the cluster's communication overhead, and we benchmark our system's performance on the ImageNet dataset.
Optimal prediction for sparse linear models? Lower bounds for coordinate-separable M-estimators
Nov 30, 2015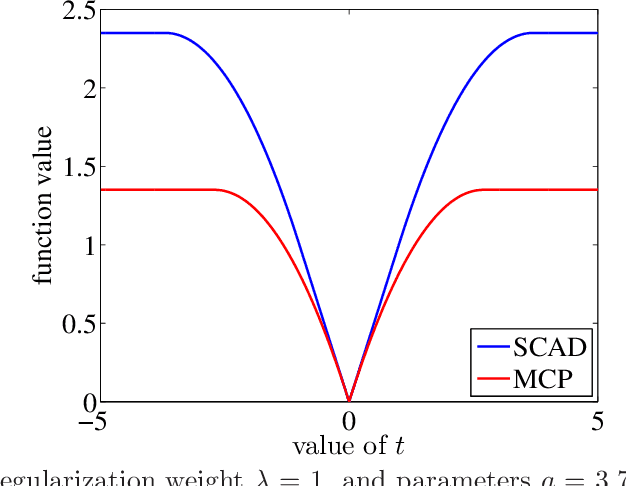
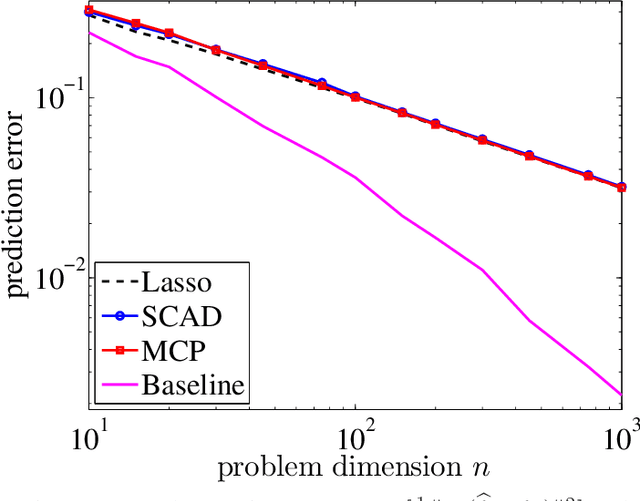
For the problem of high-dimensional sparse linear regression, it is known that an $\ell_0$-based estimator can achieve a $1/n$ "fast" rate on the prediction error without any conditions on the design matrix, whereas in absence of restrictive conditions on the design matrix, popular polynomial-time methods only guarantee the $1/\sqrt{n}$ "slow" rate. In this paper, we show that the slow rate is intrinsic to a broad class of M-estimators. In particular, for estimators based on minimizing a least-squares cost function together with a (possibly non-convex) coordinate-wise separable regularizer, there is always a "bad" local optimum such that the associated prediction error is lower bounded by a constant multiple of $1/\sqrt{n}$. For convex regularizers, this lower bound applies to all global optima. The theory is applicable to many popular estimators, including convex $\ell_1$-based methods as well as M-estimators based on nonconvex regularizers, including the SCAD penalty or the MCP regularizer. In addition, for a broad class of nonconvex regularizers, we show that the bad local optima are very common, in that a broad class of local minimization algorithms with random initialization will typically converge to a bad solution.
Learning Halfspaces and Neural Networks with Random Initialization
Nov 25, 2015
We study non-convex empirical risk minimization for learning halfspaces and neural networks. For loss functions that are $L$-Lipschitz continuous, we present algorithms to learn halfspaces and multi-layer neural networks that achieve arbitrarily small excess risk $\epsilon>0$. The time complexity is polynomial in the input dimension $d$ and the sample size $n$, but exponential in the quantity $(L/\epsilon^2)\log(L/\epsilon)$. These algorithms run multiple rounds of random initialization followed by arbitrary optimization steps. We further show that if the data is separable by some neural network with constant margin $\gamma>0$, then there is a polynomial-time algorithm for learning a neural network that separates the training data with margin $\Omega(\gamma)$. As a consequence, the algorithm achieves arbitrary generalization error $\epsilon>0$ with ${\rm poly}(d,1/\epsilon)$ sample and time complexity. We establish the same learnability result when the labels are randomly flipped with probability $\eta<1/2$.
$\ell_1$-regularized Neural Networks are Improperly Learnable in Polynomial Time
Oct 13, 2015
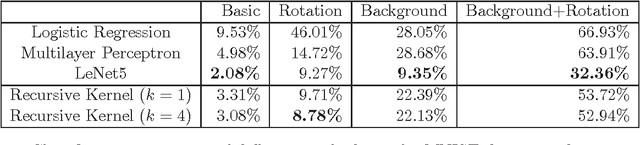

We study the improper learning of multi-layer neural networks. Suppose that the neural network to be learned has $k$ hidden layers and that the $\ell_1$-norm of the incoming weights of any neuron is bounded by $L$. We present a kernel-based method, such that with probability at least $1 - \delta$, it learns a predictor whose generalization error is at most $\epsilon$ worse than that of the neural network. The sample complexity and the time complexity of the presented method are polynomial in the input dimension and in $(1/\epsilon,\log(1/\delta),F(k,L))$, where $F(k,L)$ is a function depending on $(k,L)$ and on the activation function, independent of the number of neurons. The algorithm applies to both sigmoid-like activation functions and ReLU-like activation functions. It implies that any sufficiently sparse neural network is learnable in polynomial time.
Splash: User-friendly Programming Interface for Parallelizing Stochastic Algorithms
Sep 23, 2015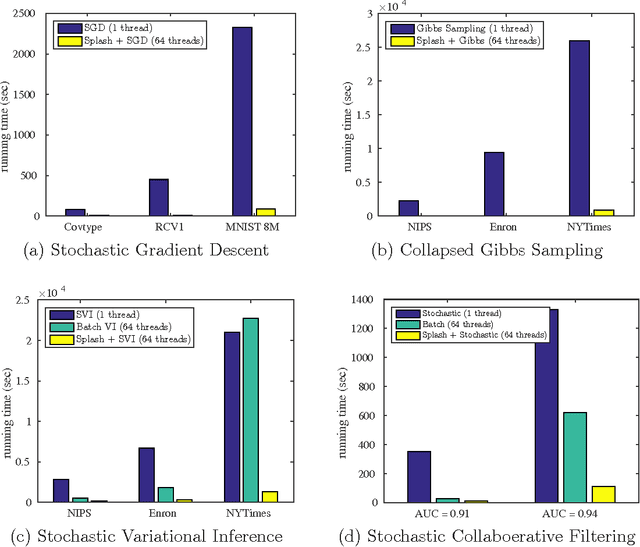
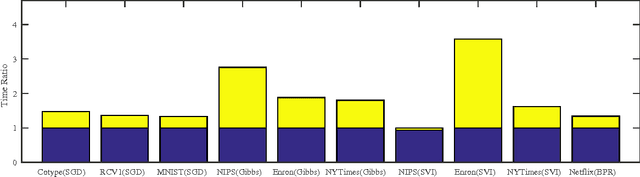
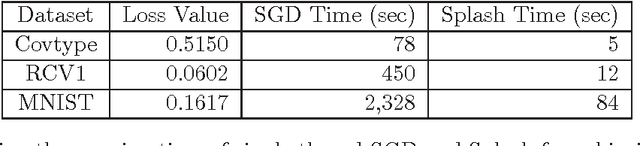
Stochastic algorithms are efficient approaches to solving machine learning and optimization problems. In this paper, we propose a general framework called Splash for parallelizing stochastic algorithms on multi-node distributed systems. Splash consists of a programming interface and an execution engine. Using the programming interface, the user develops sequential stochastic algorithms without concerning any detail about distributed computing. The algorithm is then automatically parallelized by a communication-efficient execution engine. We provide theoretical justifications on the optimal rate of convergence for parallelizing stochastic gradient descent. Splash is built on top of Apache Spark. The real-data experiments on logistic regression, collaborative filtering and topic modeling verify that Splash yields order-of-magnitude speedup over single-thread stochastic algorithms and over state-of-the-art implementations on Spark.
Parallel Correlation Clustering on Big Graphs
Jul 20, 2015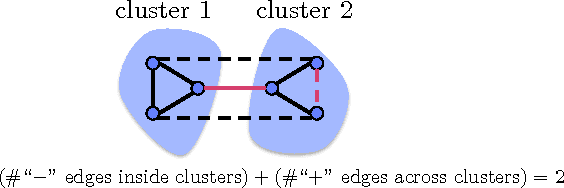

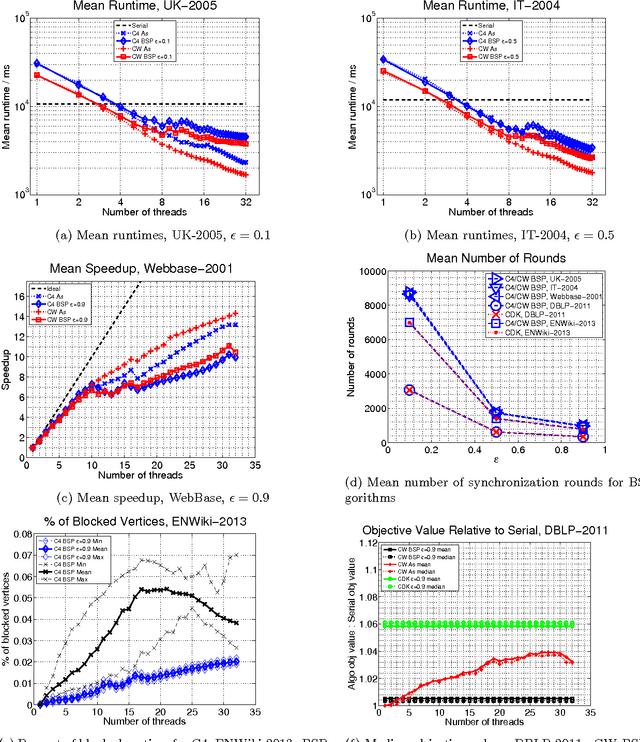
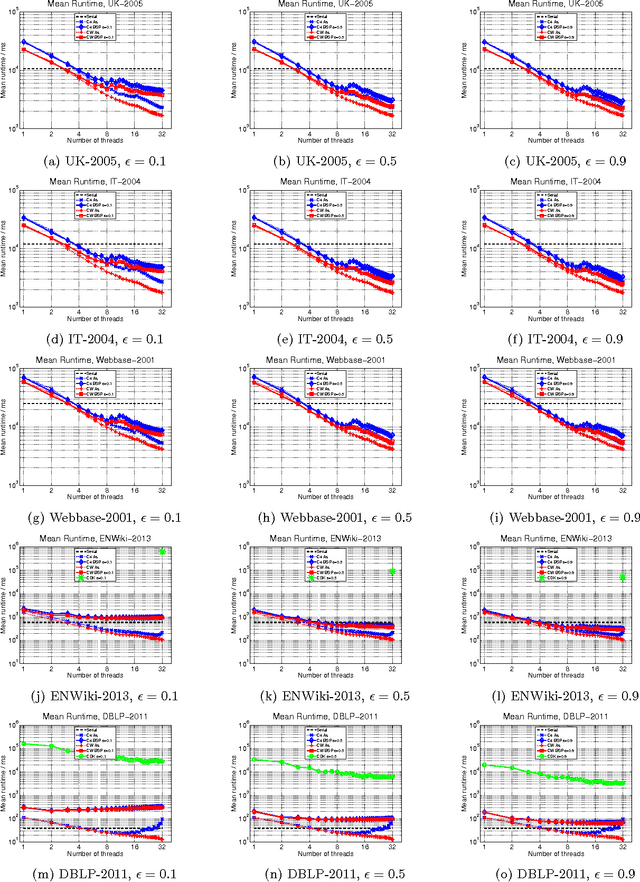
Given a similarity graph between items, correlation clustering (CC) groups similar items together and dissimilar ones apart. One of the most popular CC algorithms is KwikCluster: an algorithm that serially clusters neighborhoods of vertices, and obtains a 3-approximation ratio. Unfortunately, KwikCluster in practice requires a large number of clustering rounds, a potential bottleneck for large graphs. We present C4 and ClusterWild!, two algorithms for parallel correlation clustering that run in a polylogarithmic number of rounds and achieve nearly linear speedups, provably. C4 uses concurrency control to enforce serializability of a parallel clustering process, and guarantees a 3-approximation ratio. ClusterWild! is a coordination free algorithm that abandons consistency for the benefit of better scaling; this leads to a provably small loss in the 3-approximation ratio. We provide extensive experimental results for both algorithms, where we outperform the state of the art, both in terms of clustering accuracy and running time. We show that our algorithms can cluster billion-edge graphs in under 5 seconds on 32 cores, while achieving a 15x speedup.
Adding vs. Averaging in Distributed Primal-Dual Optimization
Jul 03, 2015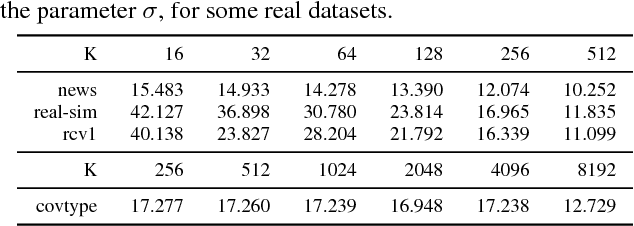
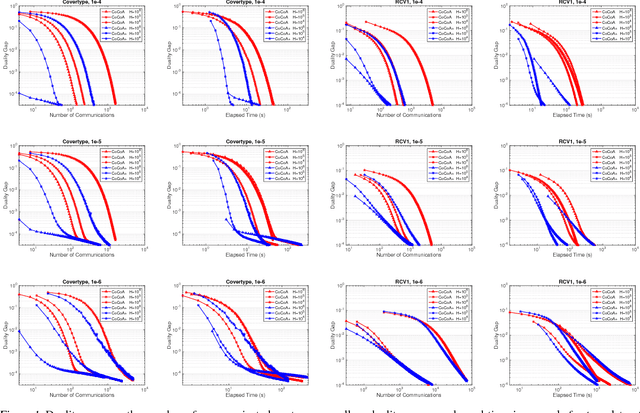
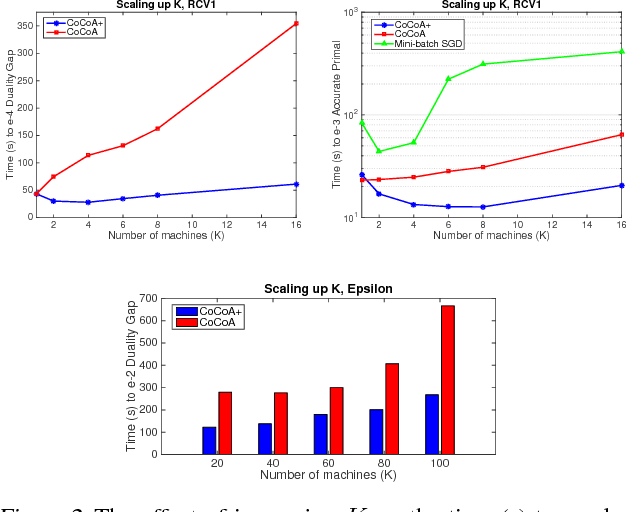
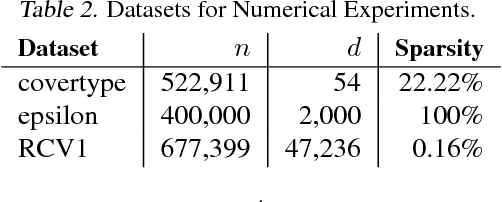
Distributed optimization methods for large-scale machine learning suffer from a communication bottleneck. It is difficult to reduce this bottleneck while still efficiently and accurately aggregating partial work from different machines. In this paper, we present a novel generalization of the recent communication-efficient primal-dual framework (CoCoA) for distributed optimization. Our framework, CoCoA+, allows for additive combination of local updates to the global parameters at each iteration, whereas previous schemes with convergence guarantees only allow conservative averaging. We give stronger (primal-dual) convergence rate guarantees for both CoCoA as well as our new variants, and generalize the theory for both methods to cover non-smooth convex loss functions. We provide an extensive experimental comparison that shows the markedly improved performance of CoCoA+ on several real-world distributed datasets, especially when scaling up the number of machines.
On the accuracy of self-normalized log-linear models
Jun 18, 2015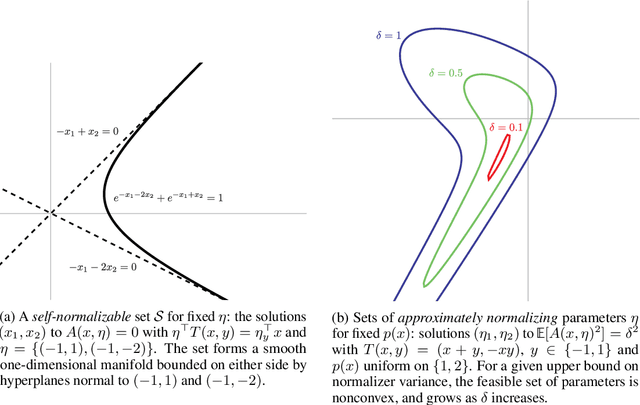
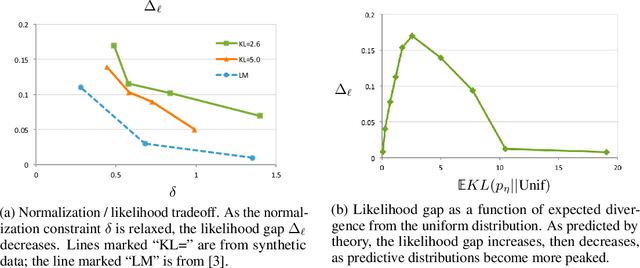
Calculation of the log-normalizer is a major computational obstacle in applications of log-linear models with large output spaces. The problem of fast normalizer computation has therefore attracted significant attention in the theoretical and applied machine learning literature. In this paper, we analyze a recently proposed technique known as "self-normalization", which introduces a regularization term in training to penalize log normalizers for deviating from zero. This makes it possible to use unnormalized model scores as approximate probabilities. Empirical evidence suggests that self-normalization is extremely effective, but a theoretical understanding of why it should work, and how generally it can be applied, is largely lacking. We prove generalization bounds on the estimated variance of normalizers and upper bounds on the loss in accuracy due to self-normalization, describe classes of input distributions that self-normalize easily, and construct explicit examples of high-variance input distributions. Our theoretical results make predictions about the difficulty of fitting self-normalized models to several classes of distributions, and we conclude with empirical validation of these predictions.
Variational consensus Monte Carlo
Jun 09, 2015
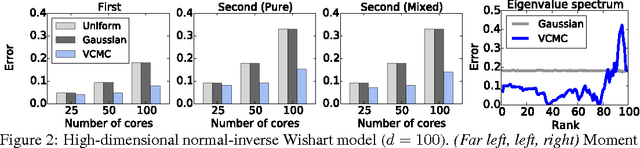
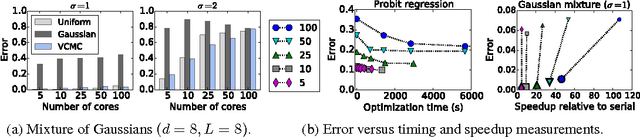
Practitioners of Bayesian statistics have long depended on Markov chain Monte Carlo (MCMC) to obtain samples from intractable posterior distributions. Unfortunately, MCMC algorithms are typically serial, and do not scale to the large datasets typical of modern machine learning. The recently proposed consensus Monte Carlo algorithm removes this limitation by partitioning the data and drawing samples conditional on each partition in parallel (Scott et al, 2013). A fixed aggregation function then combines these samples, yielding approximate posterior samples. We introduce variational consensus Monte Carlo (VCMC), a variational Bayes algorithm that optimizes over aggregation functions to obtain samples from a distribution that better approximates the target. The resulting objective contains an intractable entropy term; we therefore derive a relaxation of the objective and show that the relaxed problem is blockwise concave under mild conditions. We illustrate the advantages of our algorithm on three inference tasks from the literature, demonstrating both the superior quality of the posterior approximation and the moderate overhead of the optimization step. Our algorithm achieves a relative error reduction (measured against serial MCMC) of up to 39% compared to consensus Monte Carlo on the task of estimating 300-dimensional probit regression parameter expectations; similarly, it achieves an error reduction of 92% on the task of estimating cluster comembership probabilities in a Gaussian mixture model with 8 components in 8 dimensions. Furthermore, these gains come at moderate cost compared to the runtime of serial MCMC, achieving near-ideal speedup in some instances.