 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Robust Linear Regression in Nearly Linear Time
Jul 16, 2020We study the problem of high-dimensional robust linear regression where a learner is given access to $n$ samples from the generative model $Y = \langle X,w^* \rangle + \epsilon$ (with $X \in \mathbb{R}^d$ and $\epsilon$ independent), in which an $\eta$ fraction of the samples have been adversarially corrupted. We propose estimators for this problem under two settings: (i) $X$ is L4-L2 hypercontractive, $\mathbb{E} [XX^\top]$ has bounded condition number and $\epsilon$ has bounded variance and (ii) $X$ is sub-Gaussian with identity second moment and $\epsilon$ is sub-Gaussian. In both settings, our estimators: (a) Achieve optimal sample complexities and recovery guarantees up to log factors and (b) Run in near linear time ($\tilde{O}(nd / \eta^6)$). Prior to our work, polynomial time algorithms achieving near optimal sample complexities were only known in the setting where $X$ is Gaussian with identity covariance and $\epsilon$ is Gaussian, and no linear time estimators were known for robust linear regression in any setting. Our estimators and their analysis leverage recent developments in the construction of faster algorithms for robust mean estimation to improve runtimes, and refined concentration of measure arguments alongside Gaussian rounding techniques to improve statistical sample complexities.
Manifold Learning via Manifold Deflation
Jul 07, 2020
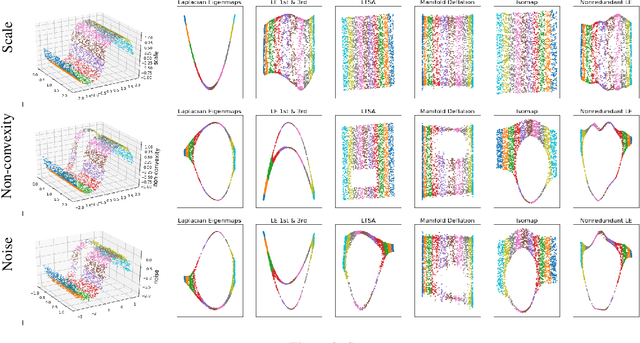
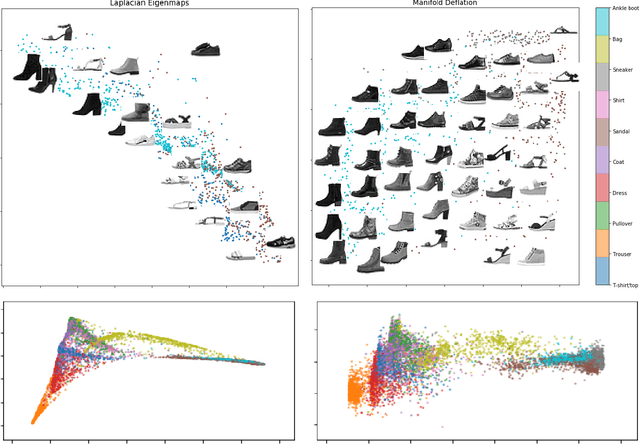
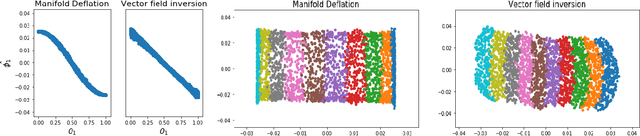
Nonlinear dimensionality reduction methods provide a valuable means to visualize and interpret high-dimensional data. However, many popular methods can fail dramatically, even on simple two-dimensional manifolds, due to problems such as vulnerability to noise, repeated eigendirections, holes in convex bodies, and boundary bias. We derive an embedding method for Riemannian manifolds that iteratively uses single-coordinate estimates to eliminate dimensions from an underlying differential operator, thus "deflating" it. These differential operators have been shown to characterize any local, spectral dimensionality reduction method. The key to our method is a novel, incremental tangent space estimator that incorporates global structure as coordinates are added. We prove its consistency when the coordinates converge to true coordinates. Empirically, we show our algorithm recovers novel and interesting embeddings on real-world and synthetic datasets.
Accelerated Message Passing for Entropy-Regularized MAP Inference
Jul 01, 2020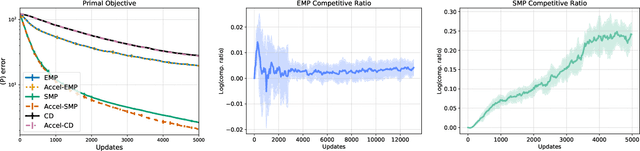
Maximum a posteriori (MAP) inference in discrete-valued Markov random fields is a fundamental problem in machine learning that involves identifying the most likely configuration of random variables given a distribution. Due to the difficulty of this combinatorial problem, linear programming (LP) relaxations are commonly used to derive specialized message passing algorithms that are often interpreted as coordinate descent on the dual LP. To achieve more desirable computational properties, a number of methods regularize the LP with an entropy term, leading to a class of smooth message passing algorithms with convergence guarantees. In this paper, we present randomized methods for accelerating these algorithms by leveraging techniques that underlie classical accelerated gradient methods. The proposed algorithms incorporate the familiar steps of standard smooth message passing algorithms, which can be viewed as coordinate minimization steps. We show that these accelerated variants achieve faster rates for finding $\epsilon$-optimal points of the unregularized problem, and, when the LP is tight, we prove that the proposed algorithms recover the true MAP solution in fewer iterations than standard message passing algorithms.
Projection Robust Wasserstein Distance and Riemannian Optimization
Jun 28, 2020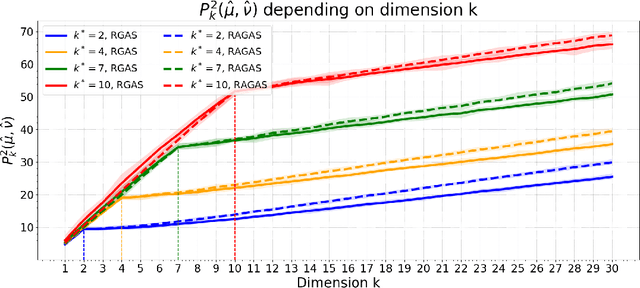

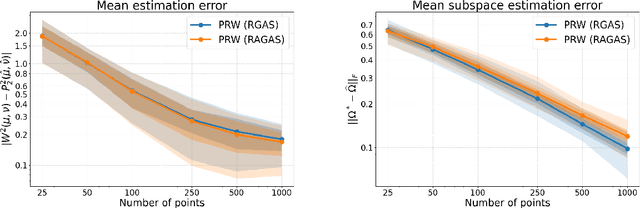
Projection robust Wasserstein (PRW) distance, or Wasserstein projection pursuit (WPP), is a robust variant of the Wasserstein distance. Recent work suggests that this quantity is more robust than the standard Wasserstein distance, in particular when comparing probability measures in high-dimensions. However, it is ruled out for practical application because the optimization model is essentially non-convex and non-smooth which makes the computation intractable. Our contribution in this paper is to revisit the original motivation behind WPP/PRW, but take the hard route of showing that, despite its non-convexity and lack of nonsmoothness, and even despite some hardness results proved by~\citet{Niles-2019-Estimation} in a minimax sense, the original formulation for PRW/WPP \textit{can} be efficiently computed in practice using Riemannian optimization, yielding in relevant cases better behavior than its convex relaxation. More specifically, we provide three simple algorithms with solid theoretical guarantee on their complexity bound (one in the appendix), and demonstrate their effectiveness and efficiency by conducing extensive experiments on synthetic and real data. This paper provides a first step into a computational theory of the PRW distance and provides the links between optimal transport and Riemannian optimization.
On Projection Robust Optimal Transport: Sample Complexity and Model Misspecification
Jun 26, 2020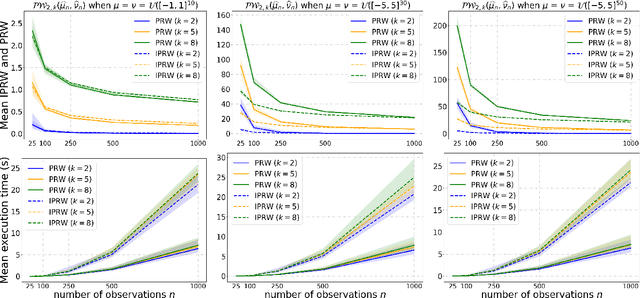
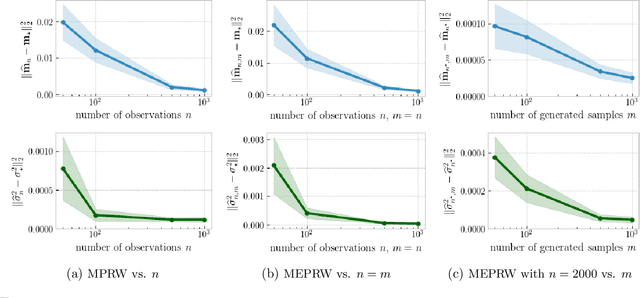
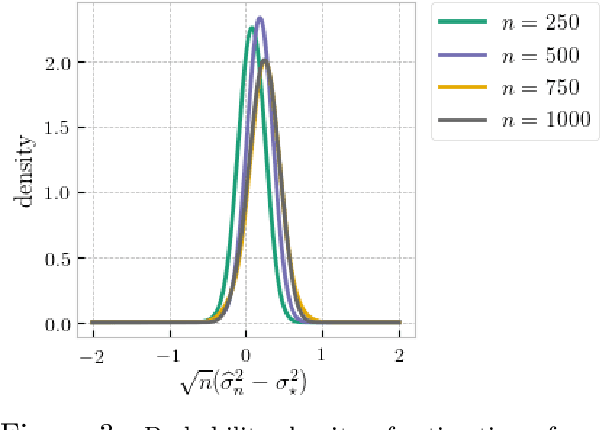
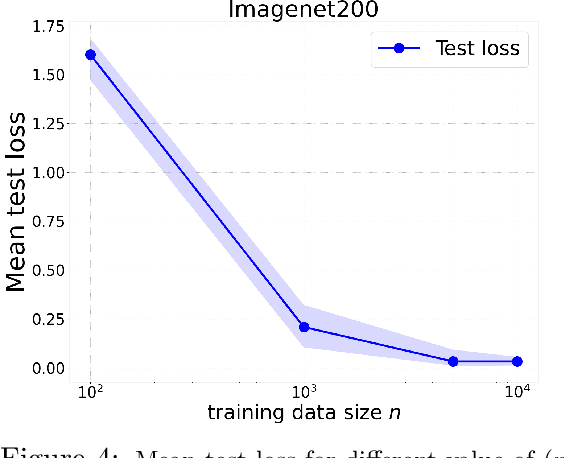
Optimal transport (OT) distances are increasingly used as loss functions for statistical inference, notably in the learning of generative models or supervised learning. Yet, the behavior of minimum Wasserstein estimators is poorly understood, notably in high-dimensional regimes or under model misspecification. In this work we adopt the viewpoint of projection robust (PR) OT, which seeks to maximize the OT cost between two measures by choosing a $k$-dimensional subspace onto which they can be projected. Our first contribution is to establish several fundamental statistical properties of PR Wasserstein distances, complementing and improving previous literature that has been restricted to one-dimensional and well-specified cases. Next, we propose the integral PR Wasserstein (IPRW) distance as an alternative to the PRW distance, by averaging rather than optimizing on subspaces. Our complexity bounds can help explain why both PRW and IPRW distances outperform Wasserstein distances empirically in high-dimensional inference tasks. Finally, we consider parametric inference using the PRW distance. We provide an asymptotic guarantee of two types of minimum PRW estimators and formulate a central limit theorem for max-sliced Wasserstein estimator under model misspecification. To enable our analysis on PRW with projection dimension larger than one, we devise a novel combination of variational analysis and statistical theory.
On the Theory of Transfer Learning: The Importance of Task Diversity
Jun 20, 2020We provide new statistical guarantees for transfer learning via representation learning--when transfer is achieved by learning a feature representation shared across different tasks. This enables learning on new tasks using far less data than is required to learn them in isolation. Formally, we consider $t+1$ tasks parameterized by functions of the form $f_j \circ h$ in a general function class $\mathcal{F} \circ \mathcal{H}$, where each $f_j$ is a task-specific function in $\mathcal{F}$ and $h$ is the shared representation in $\mathcal{H}$. Letting $C(\cdot)$ denote the complexity measure of the function class, we show that for diverse training tasks (1) the sample complexity needed to learn the shared representation across the first $t$ training tasks scales as $C(\mathcal{H}) + t C(\mathcal{F})$, despite no explicit access to a signal from the feature representation and (2) with an accurate estimate of the representation, the sample complexity needed to learn a new task scales only with $C(\mathcal{F})$. Our results depend upon a new general notion of task diversity--applicable to models with general tasks, features, and losses--as well as a novel chain rule for Gaussian complexities. Finally, we exhibit the utility of our general framework in several models of importance in the literature.
Active Learning for Nonlinear System Identification with Guarantees
Jun 18, 2020While the identification of nonlinear dynamical systems is a fundamental building block of model-based reinforcement learning and feedback control, its sample complexity is only understood for systems that either have discrete states and actions or for systems that can be identified from data generated by i.i.d. random inputs. Nonetheless, many interesting dynamical systems have continuous states and actions and can only be identified through a judicious choice of inputs. Motivated by practical settings, we study a class of nonlinear dynamical systems whose state transitions depend linearly on a known feature embedding of state-action pairs. To estimate such systems in finite time identification methods must explore all directions in feature space. We propose an active learning approach that achieves this by repeating three steps: trajectory planning, trajectory tracking, and re-estimation of the system from all available data. We show that our method estimates nonlinear dynamical systems at a parametric rate, similar to the statistical rate of standard linear regression.
Instability, Computational Efficiency and Statistical Accuracy
May 22, 2020
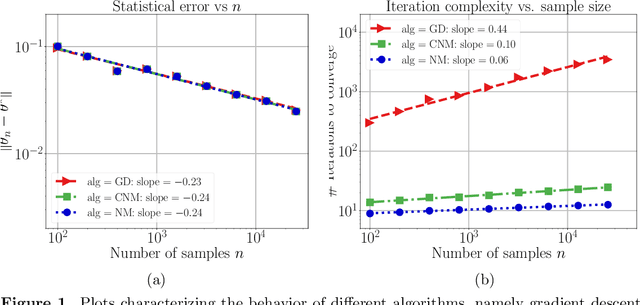
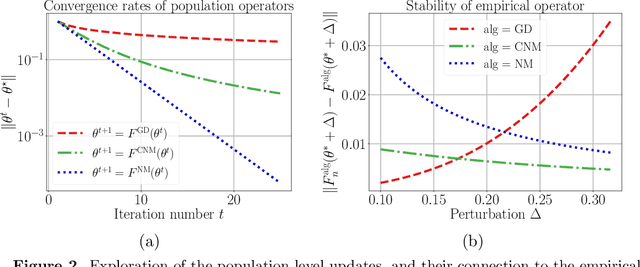

Many statistical estimators are defined as the fixed point of a data-dependent operator, with estimators based on minimizing a cost function being an important special case. The limiting performance of such estimators depends on the properties of the population-level operator in the idealized limit of infinitely many samples. We develop a general framework that yields bounds on statistical accuracy based on the interplay between the deterministic convergence rate of the algorithm at the population level, and its degree of (in)stability when applied to an empirical object based on $n$ samples. Using this framework, we analyze both stable forms of gradient descent and some higher-order and unstable algorithms, including Newton's method and its cubic-regularized variant, as well as the EM algorithm. We provide applications of our general results to several concrete classes of models, including Gaussian mixture estimation, single-index models, and informative non-response models. We exhibit cases in which an unstable algorithm can achieve the same statistical accuracy as a stable algorithm in exponentially fewer steps---namely, with the number of iterations being reduced from polynomial to logarithmic in sample size $n$.
Lower bounds in multiple testing: A framework based on derandomized proxies
May 07, 2020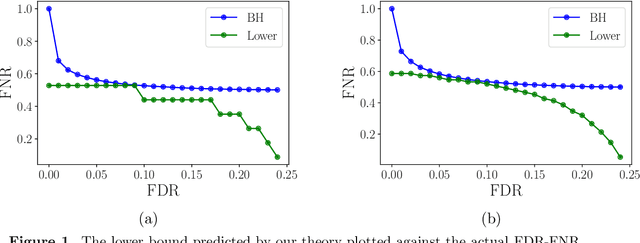
The large bulk of work in multiple testing has focused on specifying procedures that control the false discovery rate (FDR), with relatively less attention being paid to the corresponding Type II error known as the false non-discovery rate (FNR). A line of more recent work in multiple testing has begun to investigate the tradeoffs between the FDR and FNR and to provide lower bounds on the performance of procedures that depend on the model structure. Lacking thus far, however, has been a general approach to obtaining lower bounds for a broad class of models. This paper introduces an analysis strategy based on derandomization, illustrated by applications to various concrete models. Our main result is meta-theorem that gives a general recipe for obtaining lower bounds on the combination of FDR and FNR. We illustrate this meta-theorem by deriving explicit bounds for several models, including instances with dependence, scale-transformed alternatives, and non-Gaussian-like distributions. We provide numerical simulations of some of these lower bounds, and show a close relation to the actual performance of the Benjamini-Hochberg (BH) algorithm.
Mechanism Design with Bandit Feedback
Apr 19, 2020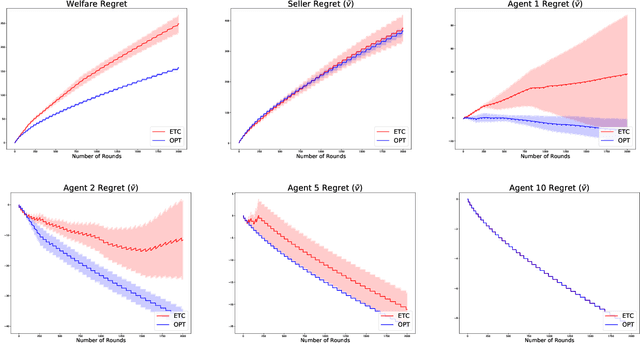
We study a multi-round welfare-maximising mechanism design problem, where, on each round, a mechanism assigns an allocation each to a set of agents and charges them a price. Then the agents report their realised (stochastic) values back to the mechanism. This is motivated by applications in cloud markets and online advertising where an agent may know her value for an allocation only after experiencing it. The distribution of these values is unknown to the agent beforehand which necessitates learning them over multiple rounds while simultaneously attempting to find the socially optimal set of allocations. Our focus is on designing truthful and individually rational mechanisms which imitate the classical VCG mechanism in the long run. To that end, we define three notions of regret for the welfare, the individual utilities of each agent (value minus price) and that of the mechanism (revenue minus cost). We show that these three terms are interdependent via an $\Omega(T^{2/3})$ lower bound for the maximum of these three terms after $T$ rounds of allocations. We describe a family of anytime algorithms which achieve this rate. The proposed framework provides flexibility to control the pricing scheme so as to trade-off between the agent and seller regrets, and additionally to control the degree of truthfulness and individual rationality.