 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBattery health prediction under generalized conditions using a Gaussian process transition model
Jul 17, 2018
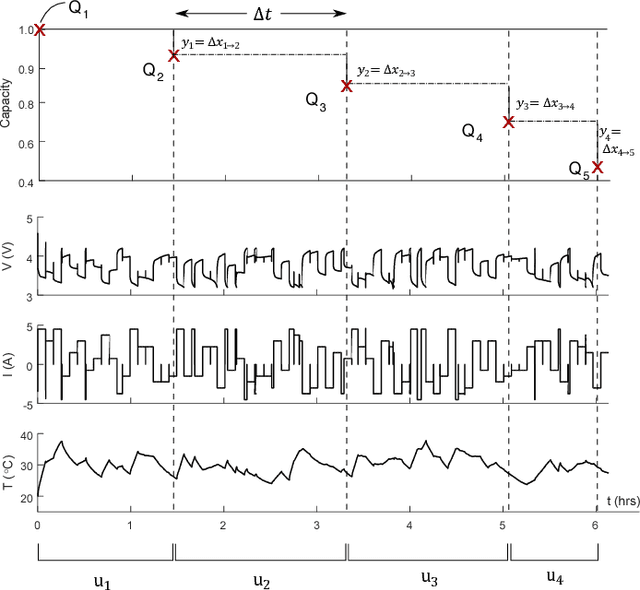
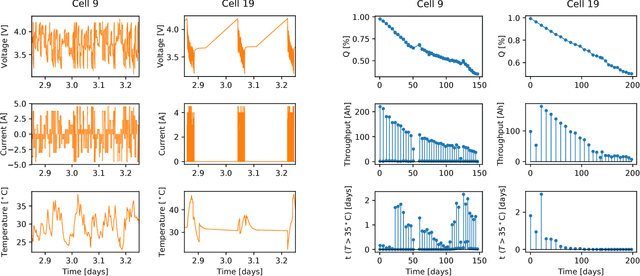

Accurately predicting the future health of batteries is necessary to ensure reliable operation, minimise maintenance costs, and calculate the value of energy storage investments. The complex nature of degradation renders data-driven approaches a promising alternative to mechanistic modelling. This study predicts the changes in battery capacity over time using a Bayesian non-parametric approach based on Gaussian process regression. These changes can be integrated against an arbitrary input sequence to predict capacity fade in a variety of usage scenarios, forming a generalised health model. The approach naturally incorporates varying current, voltage and temperature inputs, crucial for enabling real world application. A key innovation is the feature selection step, where arbitrary length current, voltage and temperature measurement vectors are mapped to fixed size feature vectors, enabling them to be efficiently used as exogenous variables. The approach is demonstrated on the open-source NASA Randomised Battery Usage Dataset, with data of 26 cells aged under randomized operational conditions. Using half of the cells for training, and half for validation, the method is shown to accurately predict non-linear capacity fade, with a best case normalised root mean square error of 4.3%, including accurate estimation of prediction uncertainty.
Fast Information-theoretic Bayesian Optimisation
Jun 06, 2018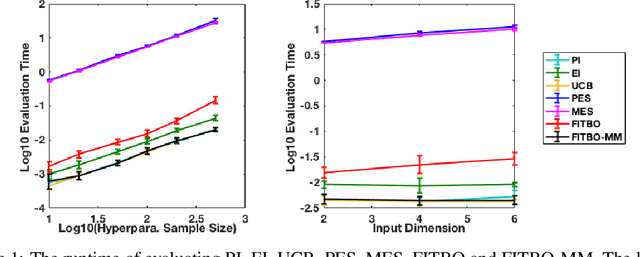
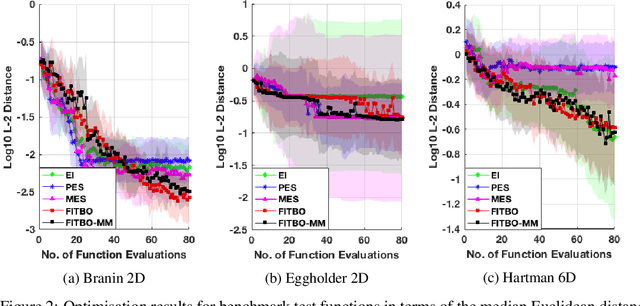
Information-theoretic Bayesian optimisation techniques have demonstrated state-of-the-art performance in tackling important global optimisation problems. However, current information-theoretic approaches require many approximations in implementation, introduce often-prohibitive computational overhead and limit the choice of kernels available to model the objective. We develop a fast information-theoretic Bayesian Optimisation method, FITBO, that avoids the need for sampling the global minimiser, thus significantly reducing computational overhead. Moreover, in comparison with existing approaches, our method faces fewer constraints on kernel choice and enjoys the merits of dealing with the output space. We demonstrate empirically that FITBO inherits the performance associated with information-theoretic Bayesian optimisation, while being even faster than simpler Bayesian optimisation approaches, such as Expected Improvement.
Optimization, fast and slow: optimally switching between local and Bayesian optimization
May 22, 2018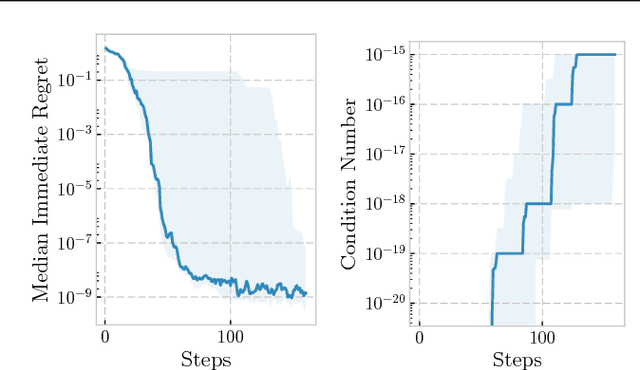
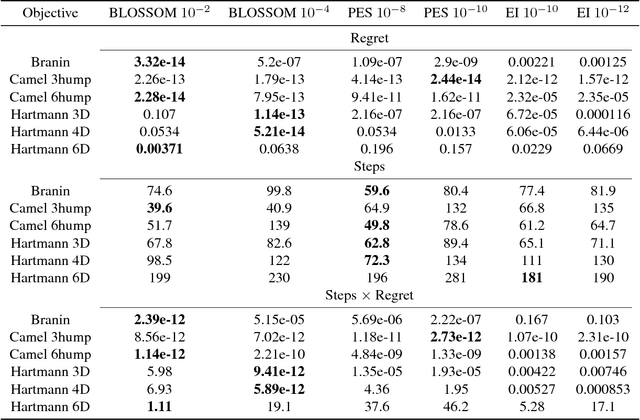
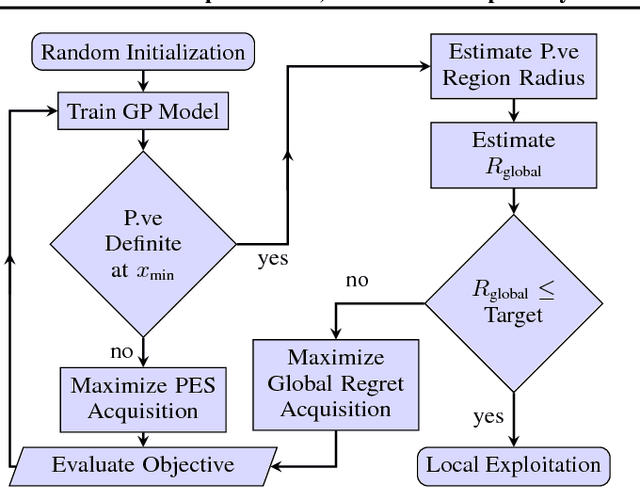
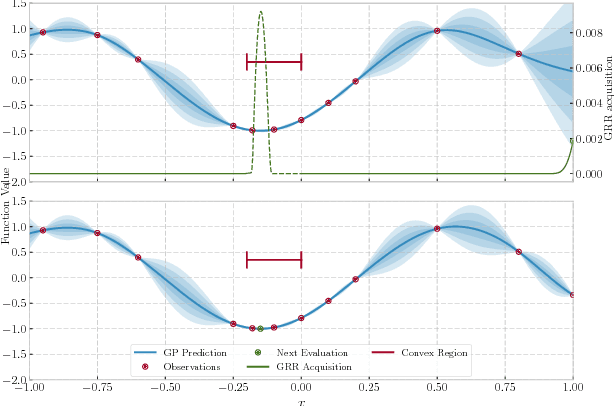
We develop the first Bayesian Optimization algorithm, BLOSSOM, which selects between multiple alternative acquisition functions and traditional local optimization at each step. This is combined with a novel stopping condition based on expected regret. This pairing allows us to obtain the best characteristics of both local and Bayesian optimization, making efficient use of function evaluations while yielding superior convergence to the global minimum on a selection of optimization problems, and also halting optimization once a principled and intuitive stopping condition has been fulfilled.
Practical Bayesian Optimization for Variable Cost Objectives
May 15, 2018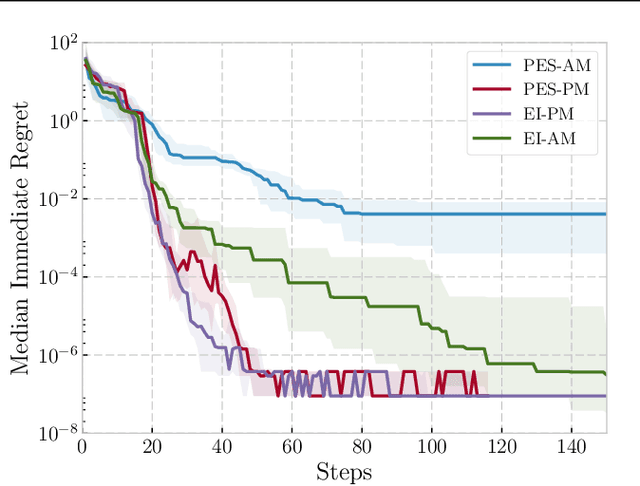
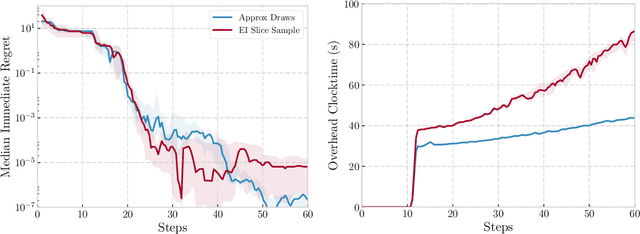
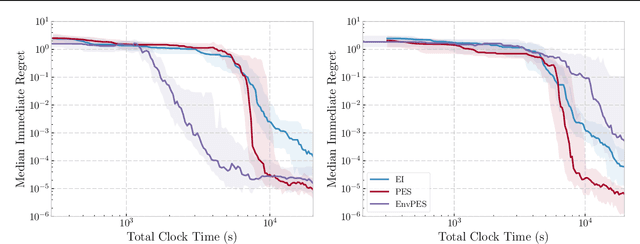
We propose a novel Bayesian Optimization approach for black-box functions with an environmental variable whose value determines the tradeoff between evaluation cost and the fidelity of the evaluations. Further, we use a novel approach to sampling support points, allowing faster construction of the acquisition function. This allows us to achieve optimization with lower overheads than previous approaches and is implemented for a more general class of problem. We show this approach to be effective on synthetic and real world benchmark problems.
Distributionally Ambiguous Optimization Techniques for Batch Bayesian Optimization
Apr 16, 2018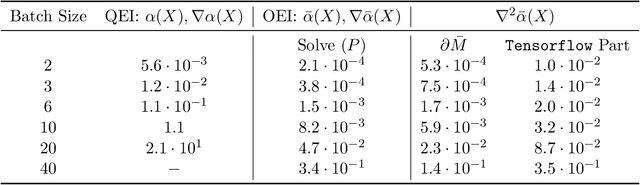
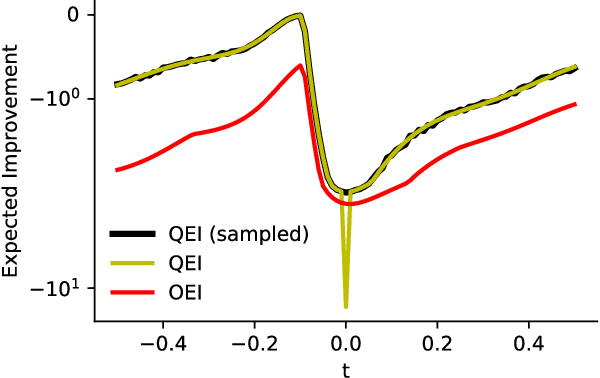
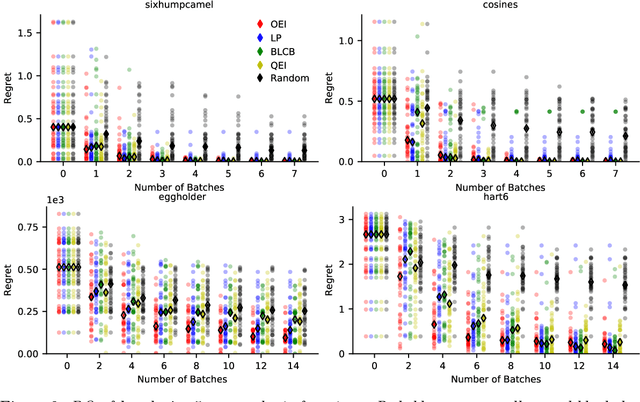

We propose a novel, theoretically-grounded, acquisition function for Batch Bayesian optimization informed by insights from distributionally ambiguous optimization. Our acquisition function is a lower bound on the well-known Expected Improvement function, which requires evaluation of a Gaussian Expectation over a multivariate piecewise affine function. Our bound is computed instead by evaluating the best-case expectation over all probability distributions consistent with the same mean and variance as the original Gaussian distribution. Unlike alternative approaches, including Expected Improvement, our proposed acquisition function avoids multi-dimensional integrations entirely, and can be computed exactly - even on large batch sizes - as the solution of a tractable convex optimization problem. Our suggested acquisition function can also be optimized efficiently, since first and second derivative information can be calculated inexpensively as by-products of the acquisition function calculation itself. We derive various novel theorems that ground our work theoretically and we demonstrate superior performance via simple motivating examples, benchmark functions and real-world problems.
Quantum algorithms for training Gaussian Processes
Mar 28, 2018Gaussian processes (GPs) are important models in supervised machine learning. Training in Gaussian processes refers to selecting the covariance functions and the associated parameters in order to improve the outcome of predictions, the core of which amounts to evaluating the logarithm of the marginal likelihood (LML) of a given model. LML gives a concrete measure of the quality of prediction that a GP model is expected to achieve. The classical computation of LML typically carries a polynomial time overhead with respect to the input size. We propose a quantum algorithm that computes the logarithm of the determinant of a Hermitian matrix, which runs in logarithmic time for sparse matrices. This is applied in conjunction with a variant of the quantum linear system algorithm that allows for logarithmic time computation of the form $\mathbf{y}^TA^{-1}\mathbf{y}$, where $\mathbf{y}$ is a dense vector and $A$ is the covariance matrix. We hence show that quantum computing can be used to estimate the LML of a GP with exponentially improved efficiency under certain conditions.
Bayesian Optimization for Dynamic Problems
Mar 09, 2018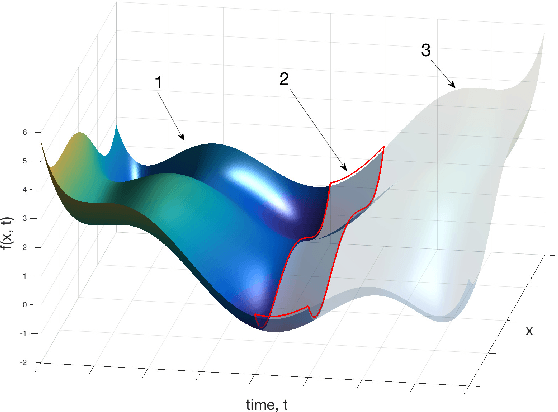

We propose practical extensions to Bayesian optimization for solving dynamic problems. We model dynamic objective functions using spatiotemporal Gaussian process priors which capture all the instances of the functions over time. Our extensions to Bayesian optimization use the information learnt from this model to guide the tracking of a temporally evolving minimum. By exploiting temporal correlations, the proposed method also determines when to make evaluations, how fast to make those evaluations, and it induces an appropriate budget of steps based on the available information. Lastly, we evaluate our technique on synthetic and real-world problems.
Alternating Optimisation and Quadrature for Robust Control
Dec 18, 2017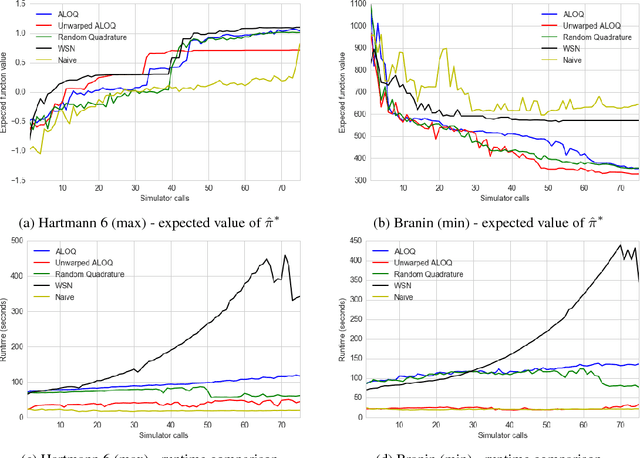
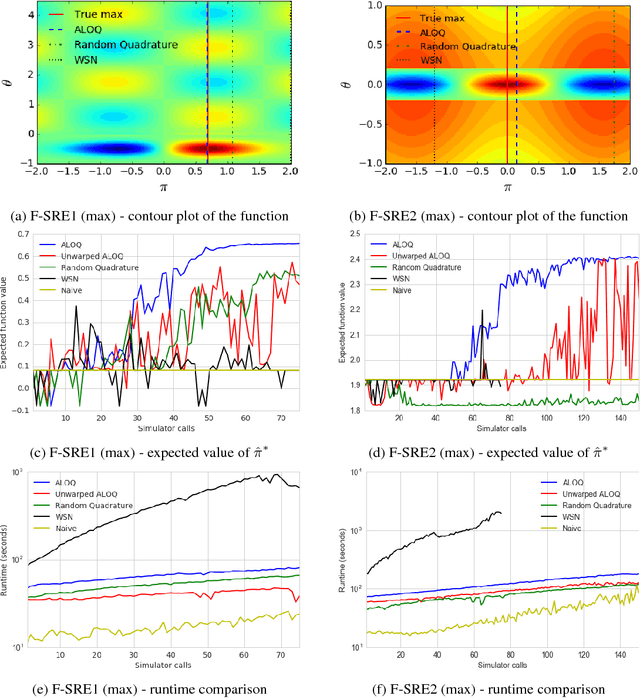
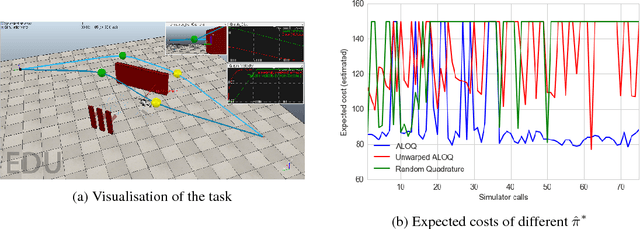
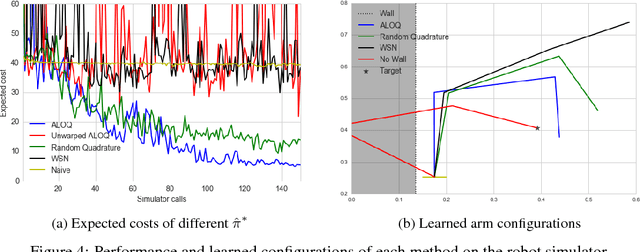
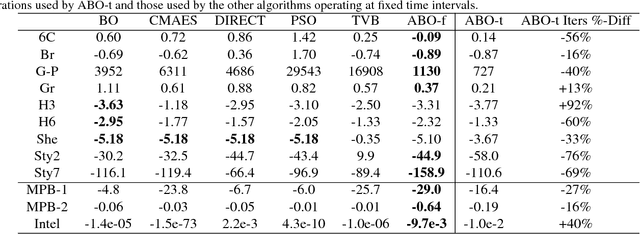
Bayesian optimisation has been successfully applied to a variety of reinforcement learning problems. However, the traditional approach for learning optimal policies in simulators does not utilise the opportunity to improve learning by adjusting certain environment variables: state features that are unobservable and randomly determined by the environment in a physical setting but are controllable in a simulator. This paper considers the problem of finding a robust policy while taking into account the impact of environment variables. We present Alternating Optimisation and Quadrature (ALOQ), which uses Bayesian optimisation and Bayesian quadrature to address such settings. ALOQ is robust to the presence of significant rare events, which may not be observable under random sampling, but play a substantial role in determining the optimal policy. Experimental results across different domains show that ALOQ can learn more efficiently and robustly than existing methods.
Probabilistic Integration: A Role in Statistical Computation?
Oct 18, 2017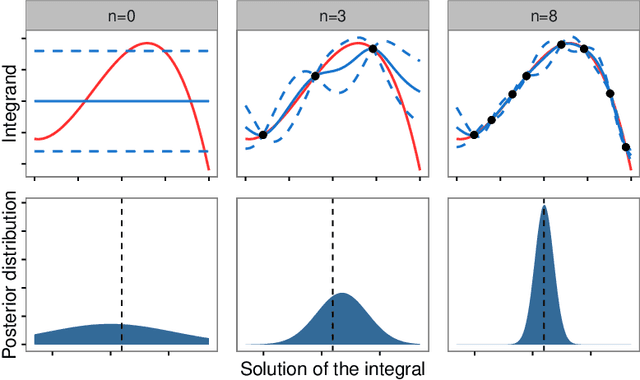
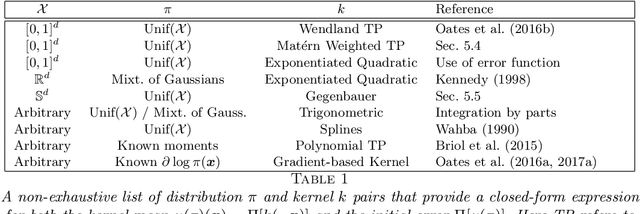
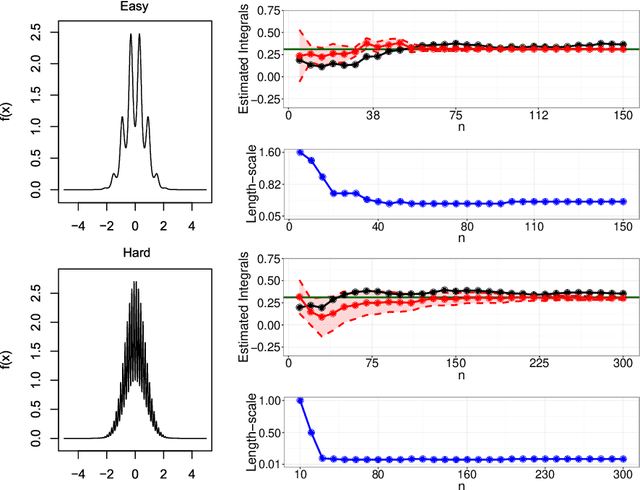
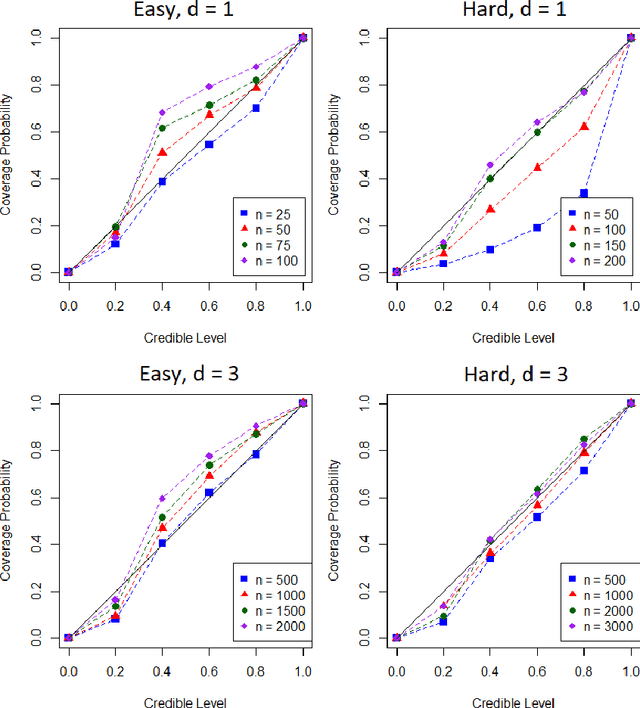
A research frontier has emerged in scientific computation, wherein numerical error is regarded as a source of epistemic uncertainty that can be modelled. This raises several statistical challenges, including the design of statistical methods that enable the coherent propagation of probabilities through a (possibly deterministic) computational work-flow. This paper examines the case for probabilistic numerical methods in routine statistical computation. Our focus is on numerical integration, where a probabilistic integrator is equipped with a full distribution over its output that reflects the presence of an unknown numerical error. Our main technical contribution is to establish, for the first time, rates of posterior contraction for these methods. These show that probabilistic integrators can in principle enjoy the "best of both worlds", leveraging the sampling efficiency of Monte Carlo methods whilst providing a principled route to assess the impact of numerical error on scientific conclusions. Several substantial applications are provided for illustration and critical evaluation, including examples from statistical modelling, computer graphics and a computer model for an oil reservoir.
Bayesian Optimization for Probabilistic Programs
Jul 13, 2017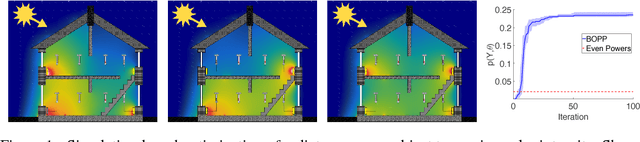
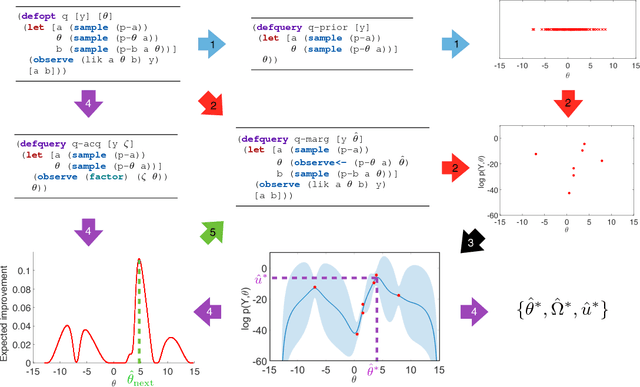
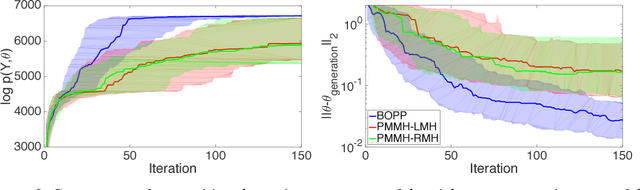
We present the first general purpose framework for marginal maximum a posteriori estimation of probabilistic program variables. By using a series of code transformations, the evidence of any probabilistic program, and therefore of any graphical model, can be optimized with respect to an arbitrary subset of its sampled variables. To carry out this optimization, we develop the first Bayesian optimization package to directly exploit the source code of its target, leading to innovations in problem-independent hyperpriors, unbounded optimization, and implicit constraint satisfaction; delivering significant performance improvements over prominent existing packages. We present applications of our method to a number of tasks including engineering design and parameter optimization.