 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafePILCO: a software tool for safe and data-efficient policy synthesis
Aug 07, 2020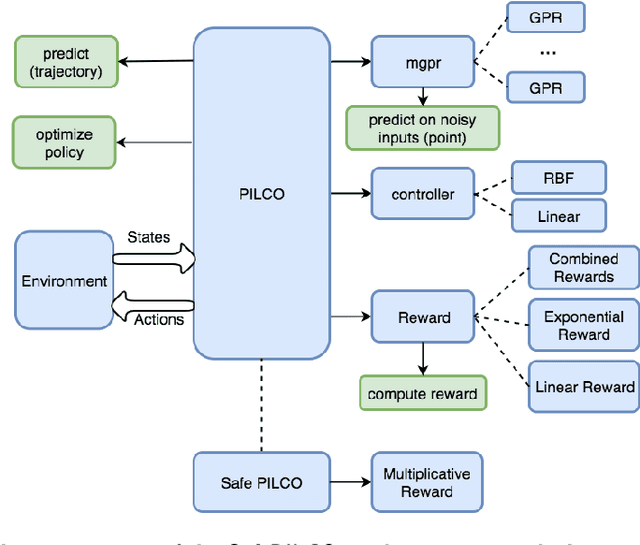
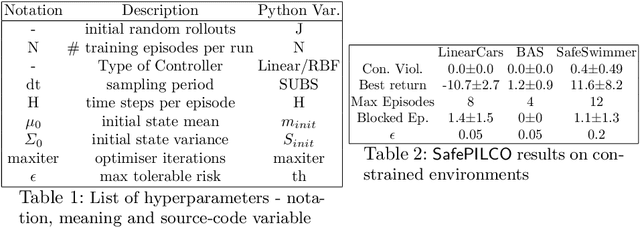
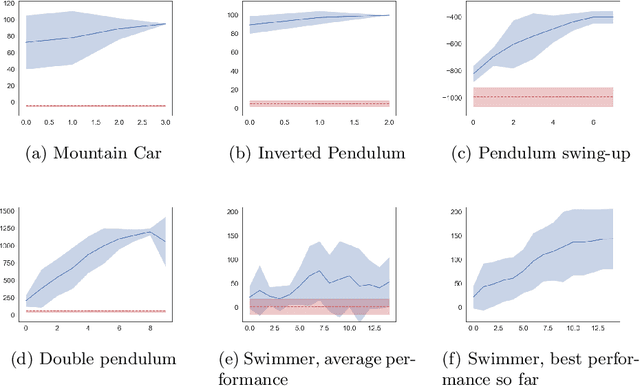
SafePILCO is a software tool for safe and data-efficient policy search with reinforcement learning. It extends the known PILCO algorithm, originally written in MATLAB, to support safe learning. We provide a Python implementation and leverage existing libraries that allow the codebase to remain short and modular, which is appropriate for wider use by the verification, reinforcement learning, and control communities.
Distributionally Ambiguous Optimization Techniques for Batch Bayesian Optimization
Apr 16, 2018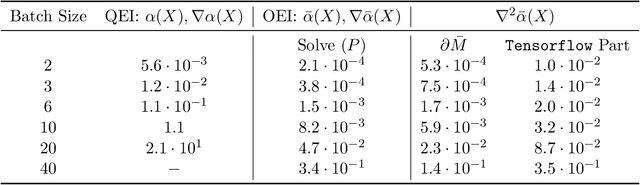
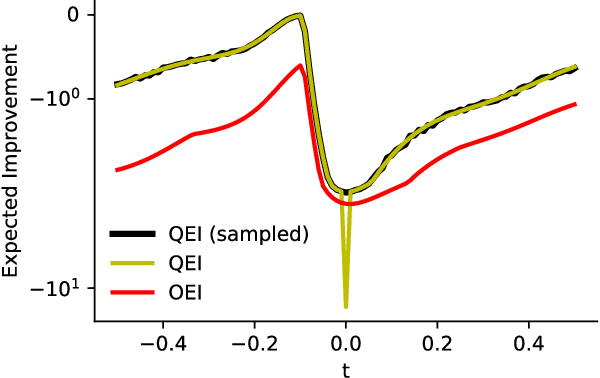
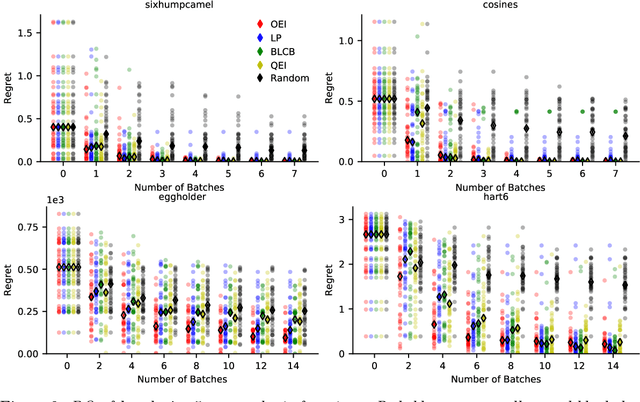

We propose a novel, theoretically-grounded, acquisition function for Batch Bayesian optimization informed by insights from distributionally ambiguous optimization. Our acquisition function is a lower bound on the well-known Expected Improvement function, which requires evaluation of a Gaussian Expectation over a multivariate piecewise affine function. Our bound is computed instead by evaluating the best-case expectation over all probability distributions consistent with the same mean and variance as the original Gaussian distribution. Unlike alternative approaches, including Expected Improvement, our proposed acquisition function avoids multi-dimensional integrations entirely, and can be computed exactly - even on large batch sizes - as the solution of a tractable convex optimization problem. Our suggested acquisition function can also be optimized efficiently, since first and second derivative information can be calculated inexpensively as by-products of the acquisition function calculation itself. We derive various novel theorems that ground our work theoretically and we demonstrate superior performance via simple motivating examples, benchmark functions and real-world problems.