 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Probabilistic Multi-Modal Actor Models for Vision-Based Robotic Grasping
Apr 15, 2019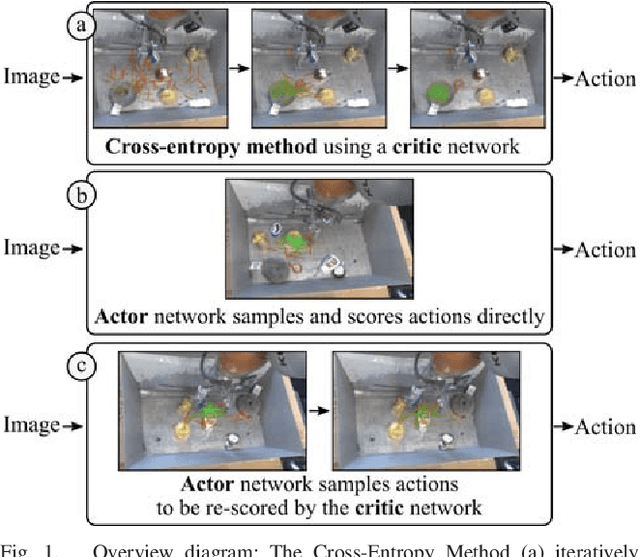
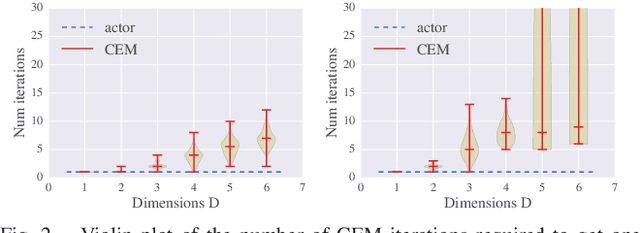
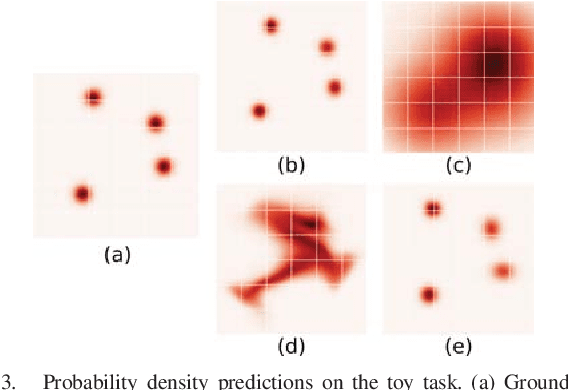

Many previous works approach vision-based robotic grasping by training a value network that evaluates grasp proposals. These approaches require an optimization process at run-time to infer the best action from the value network. As a result, the inference time grows exponentially as the dimension of action space increases. We propose an alternative method, by directly training a neural density model to approximate the conditional distribution of successful grasp poses from the input images. We construct a neural network that combines Gaussian mixture and normalizing flows, which is able to represent multi-modal, complex probability distributions. We demonstrate on both simulation and real robot that the proposed actor model achieves similar performance compared to the value network using the Cross-Entropy Method (CEM) for inference, on top-down grasping with a 4 dimensional action space. Our actor model reduces the inference time by 3 times compared to the state-of-the-art CEM method. We believe that actor models will play an important role when scaling up these approaches to higher dimensional action spaces.
Sim-to-Real Transfer of Accurate Grasping with Eye-In-Hand Observations and Continuous Control
Dec 19, 2017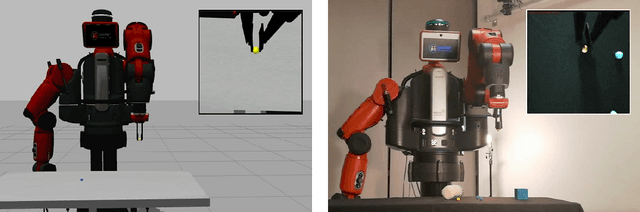
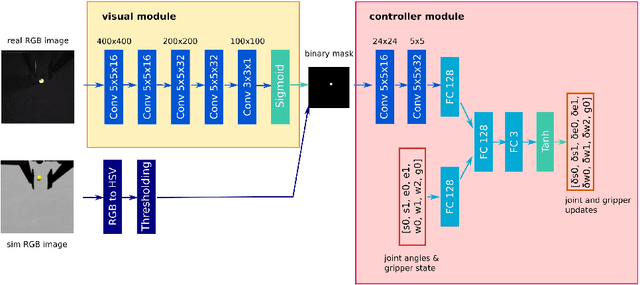

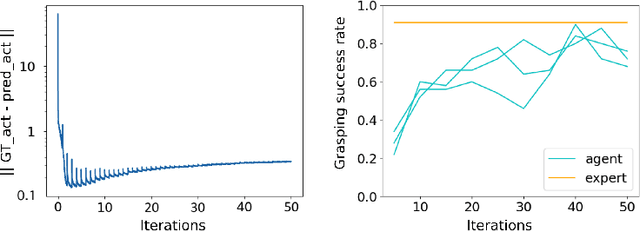
In the context of deep learning for robotics, we show effective method of training a real robot to grasp a tiny sphere (1.37cm of diameter), with an original combination of system design choices. We decompose the end-to-end system into a vision module and a closed-loop controller module. The two modules use target object segmentation as their common interface. The vision module extracts information from the robot end-effector camera, in the form of a binary segmentation mask of the target. We train it to achieve effective domain transfer by composing real background images with simulated images of the target. The controller module takes as input the binary segmentation mask, and thus is agnostic to visual discrepancies between simulated and real environments. We train our closed-loop controller in simulation using imitation learning and show it is robust with respect to discrepancies between the dynamic model of the simulated and real robot: when combined with eye-in-hand observations, we achieve a 90% success rate in grasping a tiny sphere with a real robot. The controller can generalize to unseen scenarios where the target is moving and even learns to recover from failures.
Volumetric and Multi-View CNNs for Object Classification on 3D Data
Apr 29, 2016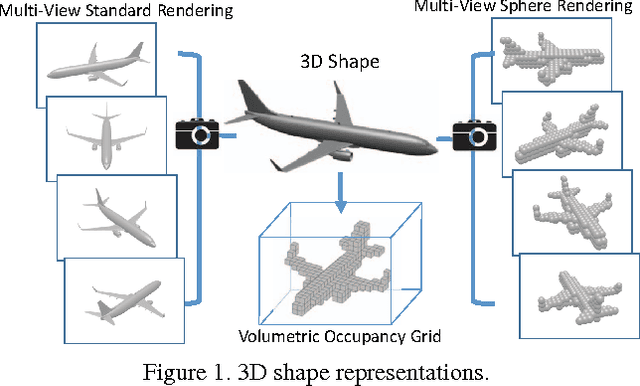
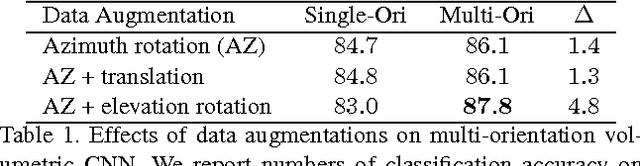

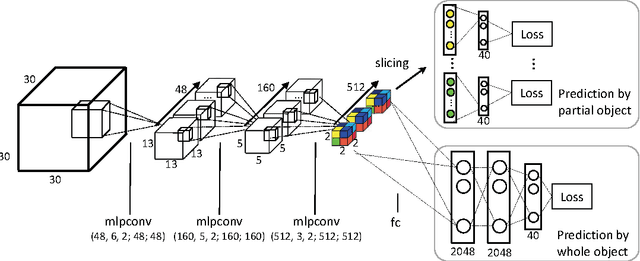
3D shape models are becoming widely available and easier to capture, making available 3D information crucial for progress in object classification. Current state-of-the-art methods rely on CNNs to address this problem. Recently, we witness two types of CNNs being developed: CNNs based upon volumetric representations versus CNNs based upon multi-view representations. Empirical results from these two types of CNNs exhibit a large gap, indicating that existing volumetric CNN architectures and approaches are unable to fully exploit the power of 3D representations. In this paper, we aim to improve both volumetric CNNs and multi-view CNNs according to extensive analysis of existing approaches. To this end, we introduce two distinct network architectures of volumetric CNNs. In addition, we examine multi-view CNNs, where we introduce multi-resolution filtering in 3D. Overall, we are able to outperform current state-of-the-art methods for both volumetric CNNs and multi-view CNNs. We provide extensive experiments designed to evaluate underlying design choices, thus providing a better understanding of the space of methods available for object classification on 3D data.
3D Reconstruction from Full-view Fisheye Camera
Jun 20, 2015

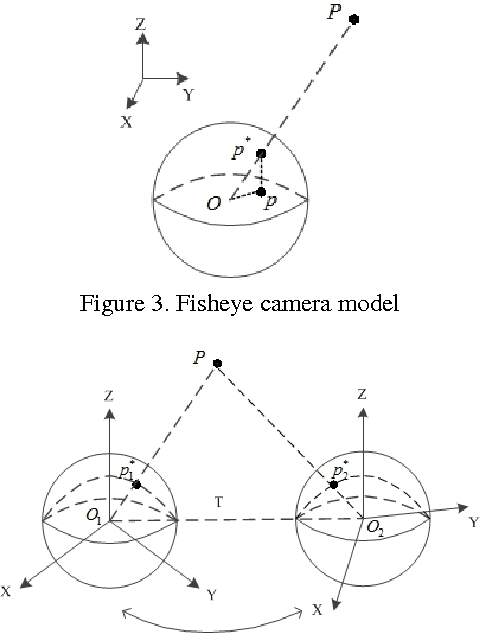
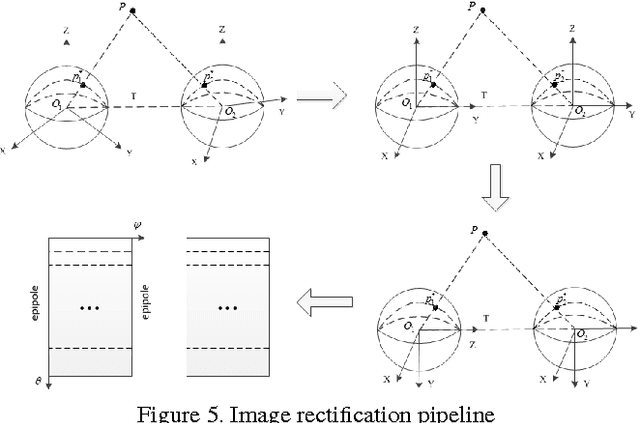
In this report, we proposed a 3D reconstruction method for the full-view fisheye camera. The camera we used is Ricoh Theta, which captures spherical images and has a wide field of view (FOV). The conventional stereo apporach based on perspective camera model cannot be directly applied and instead we used a spherical camera model to depict the relation between 3D point and its corresponding observation in the image. We implemented a system that can reconstruct the 3D scene using captures from two or more cameras. A GUI is also created to allow users to control the view perspective and obtain a better intuition of how the scene is rebuilt. Experiments showed that our reconstruction results well preserved the structure of the scene in the real world.