 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAM: A Unified Encoder for Speech and Language Modeling via Speech-Text Joint Pre-Training
Oct 20, 2021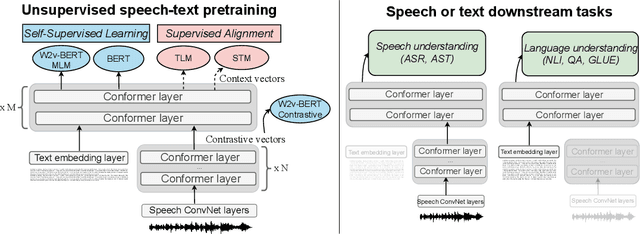
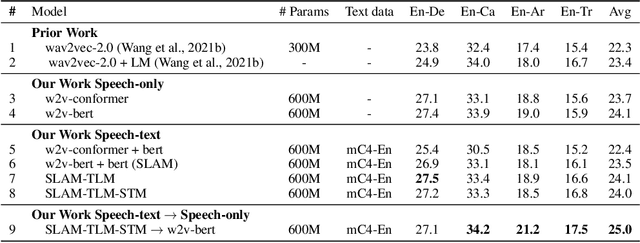
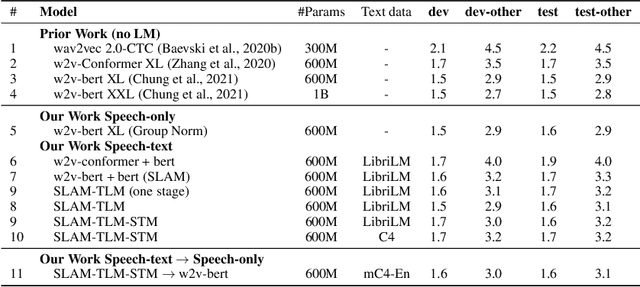
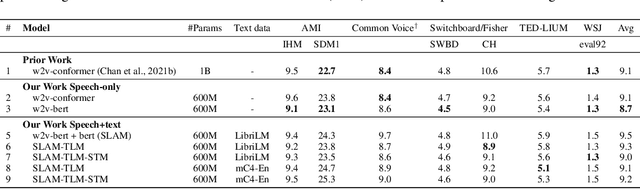
Unsupervised pre-training is now the predominant approach for both text and speech understanding. Self-attention models pre-trained on large amounts of unannotated data have been hugely successful when fine-tuned on downstream tasks from a variety of domains and languages. This paper takes the universality of unsupervised language pre-training one step further, by unifying speech and text pre-training within a single model. We build a single encoder with the BERT objective on unlabeled text together with the w2v-BERT objective on unlabeled speech. To further align our model representations across modalities, we leverage alignment losses, specifically Translation Language Modeling (TLM) and Speech Text Matching (STM) that make use of supervised speech-text recognition data. We demonstrate that incorporating both speech and text data during pre-training can significantly improve downstream quality on CoVoST~2 speech translation, by around 1 BLEU compared to single-modality pre-trained models, while retaining close to SotA performance on LibriSpeech and SpeechStew ASR tasks. On four GLUE tasks and text-normalization, we observe evidence of capacity limitations and interference between the two modalities, leading to degraded performance compared to an equivalent text-only model, while still being competitive with BERT. Through extensive empirical analysis we also demonstrate the importance of the choice of objective function for speech pre-training, and the beneficial effect of adding additional supervised signals on the quality of the learned representations.
Multilingual Document-Level Translation Enables Zero-Shot Transfer From Sentences to Documents
Sep 21, 2021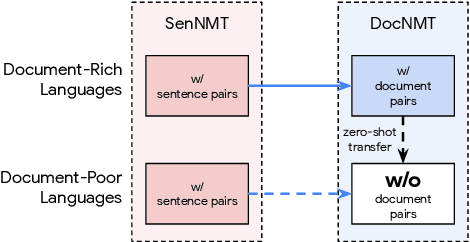

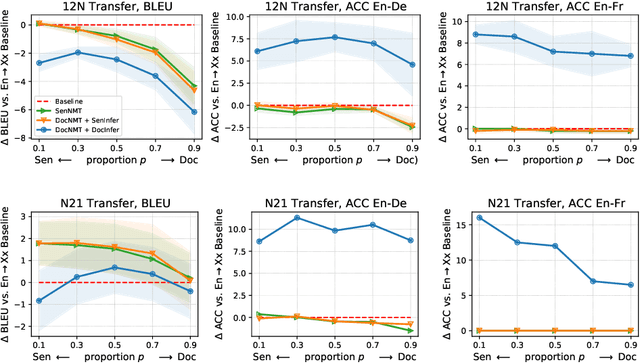
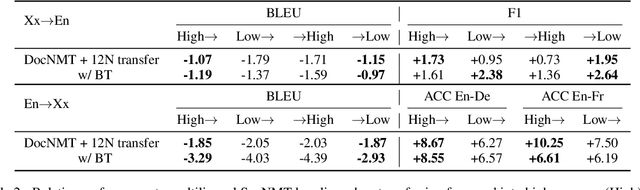
Document-level neural machine translation (DocNMT) delivers coherent translations by incorporating cross-sentence context. However, for most language pairs there's a shortage of parallel documents, although parallel sentences are readily available. In this paper, we study whether and how contextual modeling in DocNMT is transferable from sentences to documents in a zero-shot fashion (i.e. no parallel documents for student languages) through multilingual modeling. Using simple concatenation-based DocNMT, we explore the effect of 3 factors on multilingual transfer: the number of document-supervised teacher languages, the data schedule for parallel documents at training, and the data condition of parallel documents (genuine vs. backtranslated). Our experiments on Europarl-7 and IWSLT-10 datasets show the feasibility of multilingual transfer for DocNMT, particularly on document-specific metrics. We observe that more teacher languages and adequate data schedule both contribute to better transfer quality. Surprisingly, the transfer is less sensitive to the data condition and multilingual DocNMT achieves comparable performance with both back-translated and genuine document pairs.
HintedBT: Augmenting Back-Translation with Quality and Transliteration Hints
Sep 09, 2021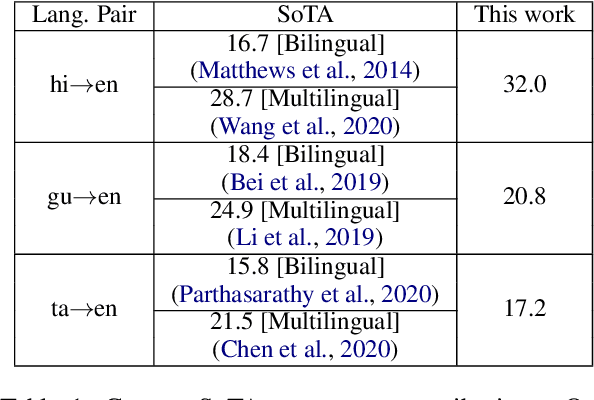


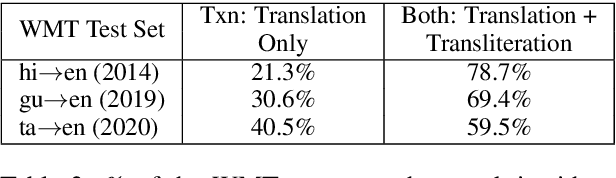
Back-translation (BT) of target monolingual corpora is a widely used data augmentation strategy for neural machine translation (NMT), especially for low-resource language pairs. To improve effectiveness of the available BT data, we introduce HintedBT -- a family of techniques which provides hints (through tags) to the encoder and decoder. First, we propose a novel method of using both high and low quality BT data by providing hints (as source tags on the encoder) to the model about the quality of each source-target pair. We don't filter out low quality data but instead show that these hints enable the model to learn effectively from noisy data. Second, we address the problem of predicting whether a source token needs to be translated or transliterated to the target language, which is common in cross-script translation tasks (i.e., where source and target do not share the written script). For such cases, we propose training the model with additional hints (as target tags on the decoder) that provide information about the operation required on the source (translation or both translation and transliteration). We conduct experiments and detailed analyses on standard WMT benchmarks for three cross-script low/medium-resource language pairs: {Hindi,Gujarati,Tamil}-to-English. Our methods compare favorably with five strong and well established baselines. We show that using these hints, both separately and together, significantly improves translation quality and leads to state-of-the-art performance in all three language pairs in corresponding bilingual settings.
MergeDistill: Merging Pre-trained Language Models using Distillation
Jun 05, 2021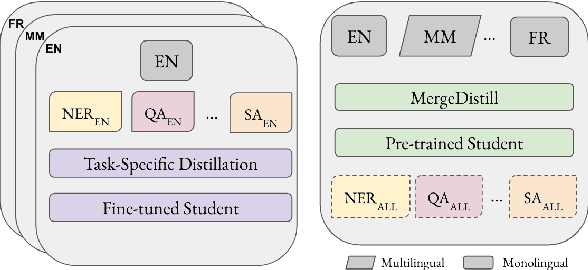
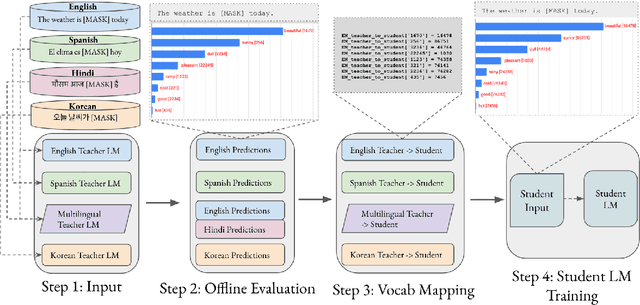
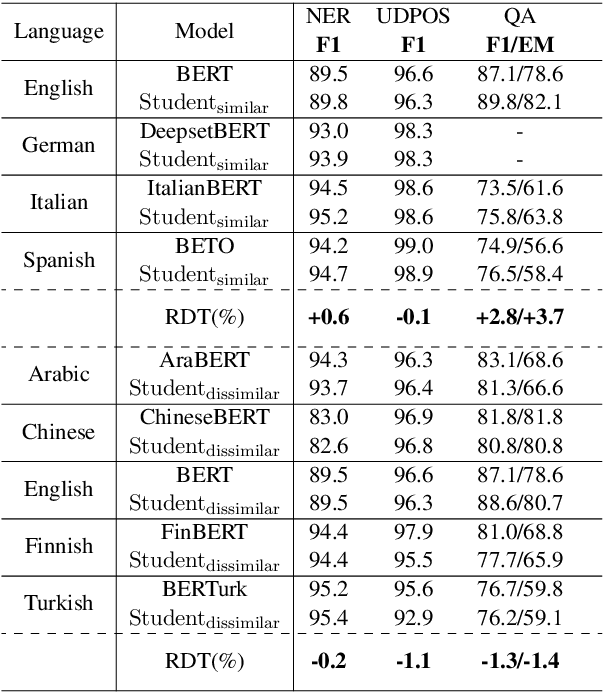
Pre-trained multilingual language models (LMs) have achieved state-of-the-art results in cross-lingual transfer, but they often lead to an inequitable representation of languages due to limited capacity, skewed pre-training data, and sub-optimal vocabularies. This has prompted the creation of an ever-growing pre-trained model universe, where each model is trained on large amounts of language or domain specific data with a carefully curated, linguistically informed vocabulary. However, doing so brings us back full circle and prevents one from leveraging the benefits of multilinguality. To address the gaps at both ends of the spectrum, we propose MergeDistill, a framework to merge pre-trained LMs in a way that can best leverage their assets with minimal dependencies, using task-agnostic knowledge distillation. We demonstrate the applicability of our framework in a practical setting by leveraging pre-existing teacher LMs and training student LMs that perform competitively with or even outperform teacher LMs trained on several orders of magnitude more data and with a fixed model capacity. We also highlight the importance of teacher selection and its impact on student model performance.
nmT5 -- Is parallel data still relevant for pre-training massively multilingual language models?
Jun 03, 2021
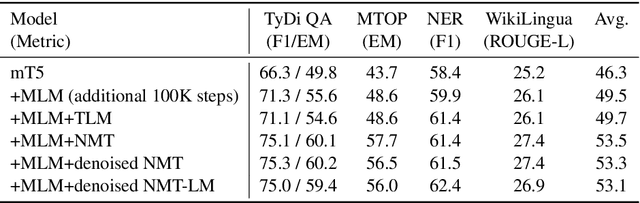
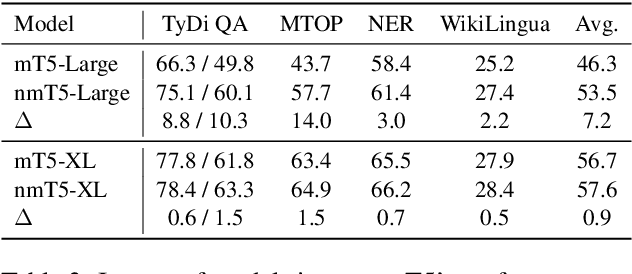
Recently, mT5 - a massively multilingual version of T5 - leveraged a unified text-to-text format to attain state-of-the-art results on a wide variety of multilingual NLP tasks. In this paper, we investigate the impact of incorporating parallel data into mT5 pre-training. We find that multi-tasking language modeling with objectives such as machine translation during pre-training is a straightforward way to improve performance on downstream multilingual and cross-lingual tasks. However, the gains start to diminish as the model capacity increases, suggesting that parallel data might not be as essential for larger models. At the same time, even at larger model sizes, we find that pre-training with parallel data still provides benefits in the limited labelled data regime.
XTREME-R: Towards More Challenging and Nuanced Multilingual Evaluation
Apr 15, 2021
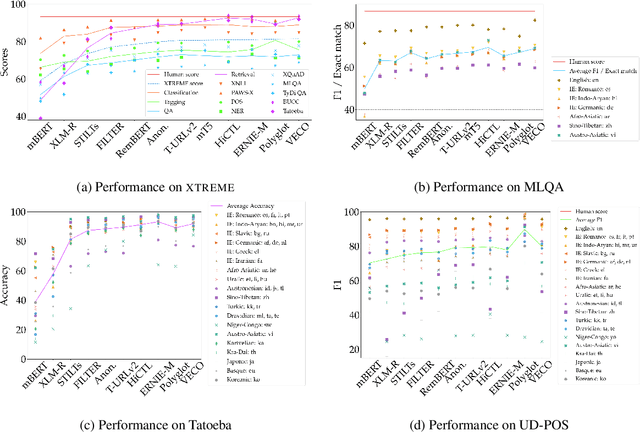
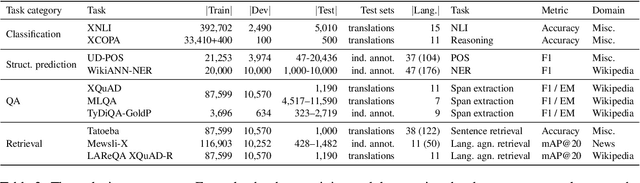
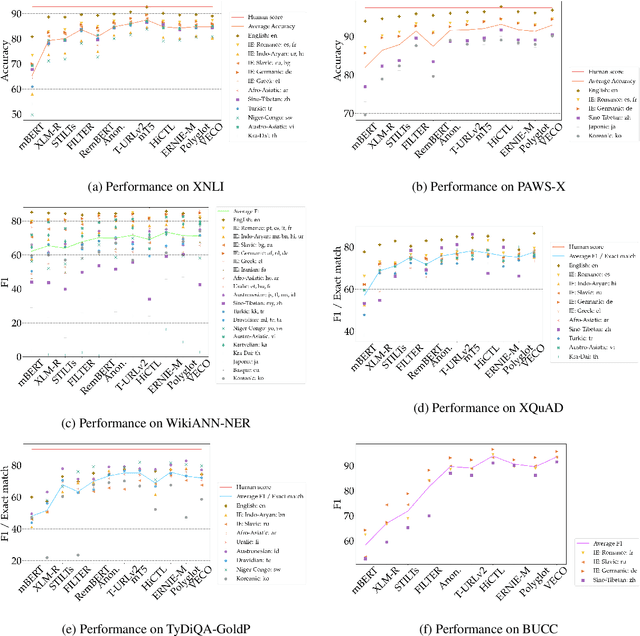
Machine learning has brought striking advances in multilingual natural language processing capabilities over the past year. For example, the latest techniques have improved the state-of-the-art performance on the XTREME multilingual benchmark by more than 13 points. While a sizeable gap to human-level performance remains, improvements have been easier to achieve in some tasks than in others. This paper analyzes the current state of cross-lingual transfer learning and summarizes some lessons learned. In order to catalyze meaningful progress, we extend XTREME to XTREME-R, which consists of an improved set of ten natural language understanding tasks, including challenging language-agnostic retrieval tasks, and covers 50 typologically diverse languages. In addition, we provide a massively multilingual diagnostic suite and fine-grained multi-dataset evaluation capabilities through an interactive public leaderboard to gain a better understanding of such models.
Gradient-guided Loss Masking for Neural Machine Translation
Feb 26, 2021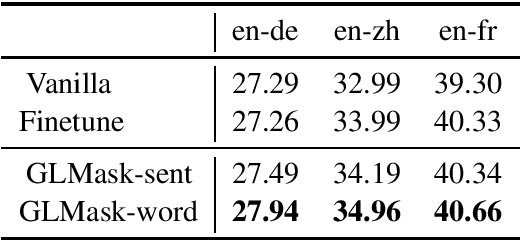
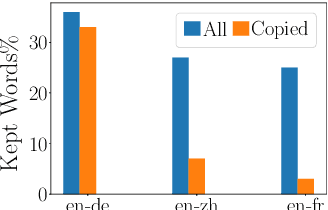
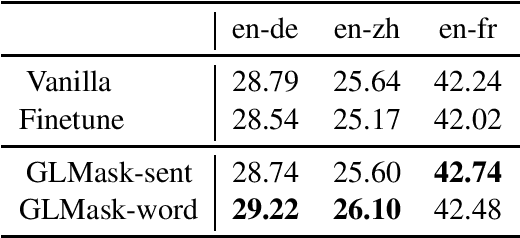
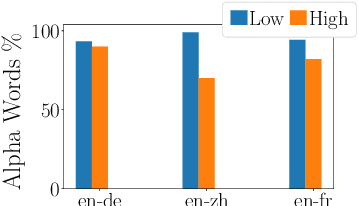
To mitigate the negative effect of low quality training data on the performance of neural machine translation models, most existing strategies focus on filtering out harmful data before training starts. In this paper, we explore strategies that dynamically optimize data usage during the training process using the model's gradients on a small set of clean data. At each training step, our algorithm calculates the gradient alignment between the training data and the clean data to mask out data with negative alignment. Our method has a natural intuition: good training data should update the model parameters in a similar direction as the clean data. Experiments on three WMT language pairs show that our method brings significant improvement over strong baselines, and the improvements are generalizable across test data from different domains.
They, Them, Theirs: Rewriting with Gender-Neutral English
Feb 12, 2021
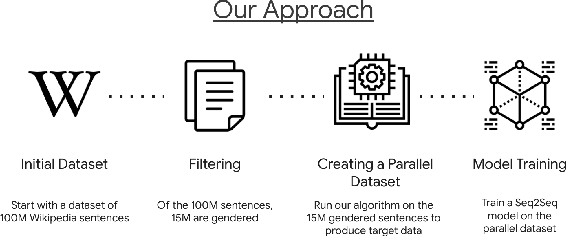
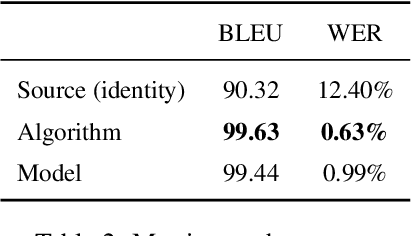
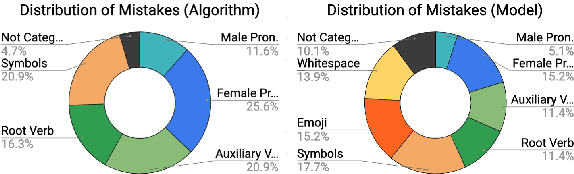
Responsible development of technology involves applications being inclusive of the diverse set of users they hope to support. An important part of this is understanding the many ways to refer to a person and being able to fluently change between the different forms as needed. We perform a case study on the singular they, a common way to promote gender inclusion in English. We define a re-writing task, create an evaluation benchmark, and show how a model can be trained to produce gender-neutral English with <1% word error rate with no human-labeled data. We discuss the practical applications and ethical considerations of the task, providing direction for future work into inclusive natural language systems.
Distilling Large Language Models into Tiny and Effective Students using pQRNN
Jan 21, 2021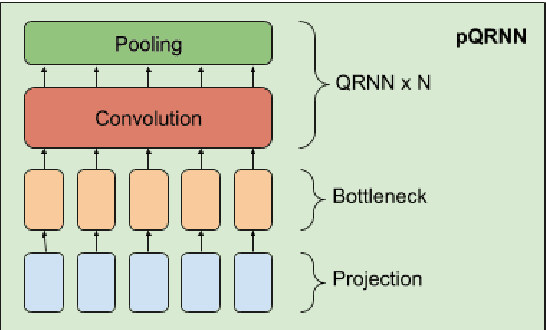
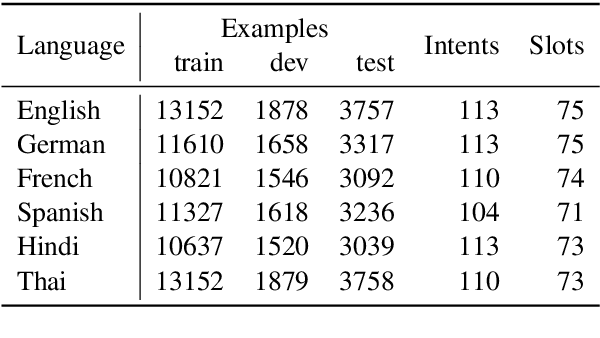
Large pre-trained multilingual models like mBERT, XLM-R achieve state of the art results on language understanding tasks. However, they are not well suited for latency critical applications on both servers and edge devices. It's important to reduce the memory and compute resources required by these models. To this end, we propose pQRNN, a projection-based embedding-free neural encoder that is tiny and effective for natural language processing tasks. Without pre-training, pQRNNs significantly outperform LSTM models with pre-trained embeddings despite being 140x smaller. With the same number of parameters, they outperform transformer baselines thereby showcasing their parameter efficiency. Additionally, we show that pQRNNs are effective student architectures for distilling large pre-trained language models. We perform careful ablations which study the effect of pQRNN parameters, data augmentation, and distillation settings. On MTOP, a challenging multilingual semantic parsing dataset, pQRNN students achieve 95.9\% of the performance of an mBERT teacher while being 350x smaller. On mATIS, a popular parsing task, pQRNN students on average are able to get to 97.1\% of the teacher while again being 350x smaller. Our strong results suggest that our approach is great for latency-sensitive applications while being able to leverage large mBERT-like models.
Rethinking embedding coupling in pre-trained language models
Oct 24, 2020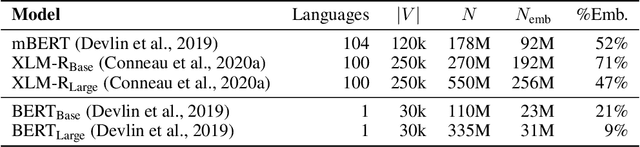
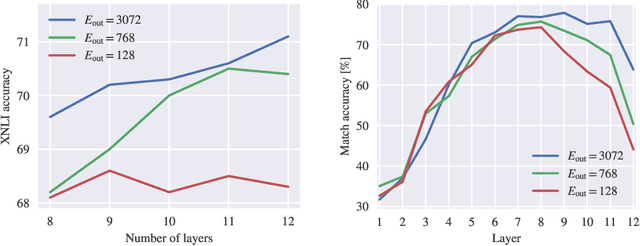


We re-evaluate the standard practice of sharing weights between input and output embeddings in state-of-the-art pre-trained language models. We show that decoupled embeddings provide increased modeling flexibility, allowing us to significantly improve the efficiency of parameter allocation in the input embedding of multilingual models. By reallocating the input embedding parameters in the Transformer layers, we achieve dramatically better performance on standard natural language understanding tasks with the same number of parameters during fine-tuning. We also show that allocating additional capacity to the output embedding provides benefits to the model that persist through the fine-tuning stage even though the output embedding is discarded after pre-training. Our analysis shows that larger output embeddings prevent the model's last layers from overspecializing to the pre-training task and encourage Transformer representations to be more general and more transferable to other tasks and languages. Harnessing these findings, we are able to train models that achieve strong performance on the XTREME benchmark without increasing the number of parameters at the fine-tuning stage.