 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Map Denoising Network and Lightweight Fusion Network for Enhanced 3D Face Recognition
Jan 01, 2024



With the increasing availability of consumer depth sensors, 3D face recognition (FR) has attracted more and more attention. However, the data acquired by these sensors are often coarse and noisy, making them impractical to use directly. In this paper, we introduce an innovative Depth map denoising network (DMDNet) based on the Denoising Implicit Image Function (DIIF) to reduce noise and enhance the quality of facial depth images for low-quality 3D FR. After generating clean depth faces using DMDNet, we further design a powerful recognition network called Lightweight Depth and Normal Fusion network (LDNFNet), which incorporates a multi-branch fusion block to learn unique and complementary features between different modalities such as depth and normal images. Comprehensive experiments conducted on four distinct low-quality databases demonstrate the effectiveness and robustness of our proposed methods. Furthermore, when combining DMDNet and LDNFNet, we achieve state-of-the-art results on the Lock3DFace database.
Skeleton2vec: A Self-supervised Learning Framework with Contextualized Target Representations for Skeleton Sequence
Jan 01, 2024Self-supervised pre-training paradigms have been extensively explored in the field of skeleton-based action recognition. In particular, methods based on masked prediction have pushed the performance of pre-training to a new height. However, these methods take low-level features, such as raw joint coordinates or temporal motion, as prediction targets for the masked regions, which is suboptimal. In this paper, we show that using high-level contextualized features as prediction targets can achieve superior performance. Specifically, we propose Skeleton2vec, a simple and efficient self-supervised 3D action representation learning framework, which utilizes a transformer-based teacher encoder taking unmasked training samples as input to create latent contextualized representations as prediction targets. Benefiting from the self-attention mechanism, the latent representations generated by the teacher encoder can incorporate the global context of the entire training samples, leading to a richer training task. Additionally, considering the high temporal correlations in skeleton sequences, we propose a motion-aware tube masking strategy which divides the skeleton sequence into several tubes and performs persistent masking within each tube based on motion priors, thus forcing the model to build long-range spatio-temporal connections and focus on action-semantic richer regions. Extensive experiments on NTU-60, NTU-120, and PKU-MMD datasets demonstrate that our proposed Skeleton2vec outperforms previous methods and achieves state-of-the-art results.
Oracle Character Recognition using Unsupervised Discriminative Consistency Network
Dec 11, 2023Ancient history relies on the study of ancient characters. However, real-world scanned oracle characters are difficult to collect and annotate, posing a major obstacle for oracle character recognition (OrCR). Besides, serious abrasion and inter-class similarity also make OrCR more challenging. In this paper, we propose a novel unsupervised domain adaptation method for OrCR, which enables to transfer knowledge from labeled handprinted oracle characters to unlabeled scanned data. We leverage pseudo-labeling to incorporate the semantic information into adaptation and constrain augmentation consistency to make the predictions of scanned samples consistent under different perturbations, leading to the model robustness to abrasion, stain and distortion. Simultaneously, an unsupervised transition loss is proposed to learn more discriminative features on the scanned domain by optimizing both between-class and within-class transition probability. Extensive experiments show that our approach achieves state-of-the-art result on Oracle-241 dataset and substantially outperforms the recently proposed structure-texture separation network by 15.1%.
Survey on Deep Face Restoration: From Non-blind to Blind and Beyond
Sep 27, 2023



Face restoration (FR) is a specialized field within image restoration that aims to recover low-quality (LQ) face images into high-quality (HQ) face images. Recent advances in deep learning technology have led to significant progress in FR methods. In this paper, we begin by examining the prevalent factors responsible for real-world LQ images and introduce degradation techniques used to synthesize LQ images. We also discuss notable benchmarks commonly utilized in the field. Next, we categorize FR methods based on different tasks and explain their evolution over time. Furthermore, we explore the various facial priors commonly utilized in the restoration process and discuss strategies to enhance their effectiveness. In the experimental section, we thoroughly evaluate the performance of state-of-the-art FR methods across various tasks using a unified benchmark. We analyze their performance from different perspectives. Finally, we discuss the challenges faced in the field of FR and propose potential directions for future advancements. The open-source repository corresponding to this work can be found at https:// github.com/ 24wenjie-li/ Awesome-Face-Restoration.
SwinFace: A Multi-task Transformer for Face Recognition, Expression Recognition, Age Estimation and Attribute Estimation
Aug 22, 2023



In recent years, vision transformers have been introduced into face recognition and analysis and have achieved performance breakthroughs. However, most previous methods generally train a single model or an ensemble of models to perform the desired task, which ignores the synergy among different tasks and fails to achieve improved prediction accuracy, increased data efficiency, and reduced training time. This paper presents a multi-purpose algorithm for simultaneous face recognition, facial expression recognition, age estimation, and face attribute estimation (40 attributes including gender) based on a single Swin Transformer. Our design, the SwinFace, consists of a single shared backbone together with a subnet for each set of related tasks. To address the conflicts among multiple tasks and meet the different demands of tasks, a Multi-Level Channel Attention (MLCA) module is integrated into each task-specific analysis subnet, which can adaptively select the features from optimal levels and channels to perform the desired tasks. Extensive experiments show that the proposed model has a better understanding of the face and achieves excellent performance for all tasks. Especially, it achieves 90.97% accuracy on RAF-DB and 0.22 $\epsilon$-error on CLAP2015, which are state-of-the-art results on facial expression recognition and age estimation respectively. The code and models will be made publicly available at https://github.com/lxq1000/SwinFace.
Adaptive Face Recognition Using Adversarial Information Network
May 23, 2023In many real-world applications, face recognition models often degenerate when training data (referred to as source domain) are different from testing data (referred to as target domain). To alleviate this mismatch caused by some factors like pose and skin tone, the utilization of pseudo-labels generated by clustering algorithms is an effective way in unsupervised domain adaptation. However, they always miss some hard positive samples. Supervision on pseudo-labeled samples attracts them towards their prototypes and would cause an intra-domain gap between pseudo-labeled samples and the remaining unlabeled samples within target domain, which results in the lack of discrimination in face recognition. In this paper, considering the particularity of face recognition, we propose a novel adversarial information network (AIN) to address it. First, a novel adversarial mutual information (MI) loss is proposed to alternately minimize MI with respect to the target classifier and maximize MI with respect to the feature extractor. By this min-max manner, the positions of target prototypes are adaptively modified which makes unlabeled images clustered more easily such that intra-domain gap can be mitigated. Second, to assist adversarial MI loss, we utilize a graph convolution network to predict linkage likelihoods between target data and generate pseudo-labels. It leverages valuable information in the context of nodes and can achieve more reliable results. The proposed method is evaluated under two scenarios, i.e., domain adaptation across poses and image conditions, and domain adaptation across faces with different skin tones. Extensive experiments show that AIN successfully improves cross-domain generalization and offers a new state-of-the-art on RFW dataset.
Gradient Attention Balance Network: Mitigating Face Recognition Racial Bias via Gradient Attention
Apr 05, 2023



Although face recognition has made impressive progress in recent years, we ignore the racial bias of the recognition system when we pursue a high level of accuracy. Previous work found that for different races, face recognition networks focus on different facial regions, and the sensitive regions of darker-skinned people are much smaller. Based on this discovery, we propose a new de-bias method based on gradient attention, called Gradient Attention Balance Network (GABN). Specifically, we use the gradient attention map (GAM) of the face recognition network to track the sensitive facial regions and make the GAMs of different races tend to be consistent through adversarial learning. This method mitigates the bias by making the network focus on similar facial regions. In addition, we also use masks to erase the Top-N sensitive facial regions, forcing the network to allocate its attention to a larger facial region. This method expands the sensitive region of darker-skinned people and further reduces the gap between GAM of darker-skinned people and GAM of Caucasians. Extensive experiments show that GABN successfully mitigates racial bias in face recognition and learns more balanced performance for people of different races.
Spatial Aware Multi-Task Learning Based Speech Separation
Jul 20, 2022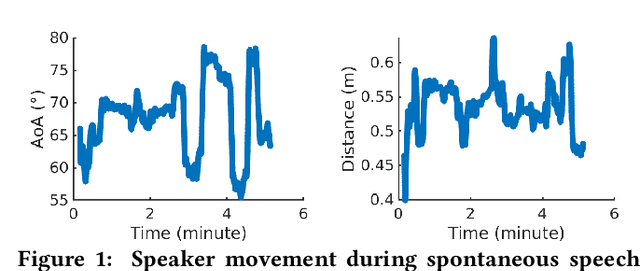
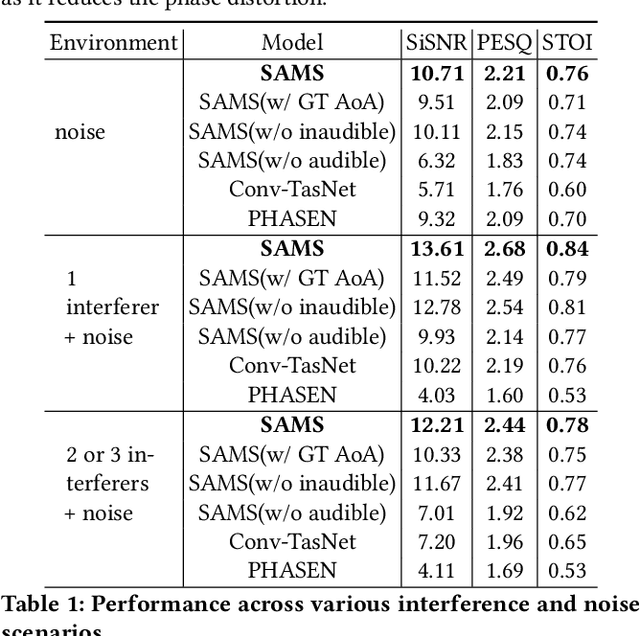
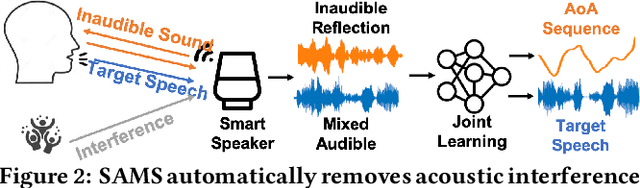
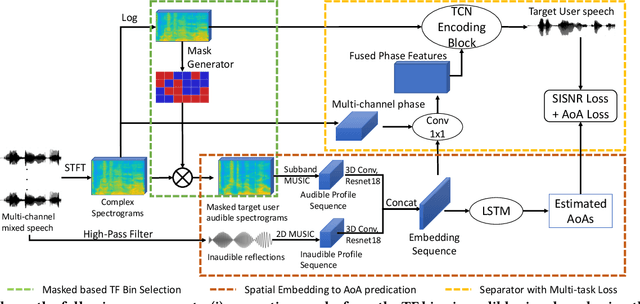
During the Covid, online meetings have become an indispensable part of our lives. This trend is likely to continue due to their convenience and broad reach. However, background noise from other family members, roommates, office-mates not only degrades the voice quality but also raises serious privacy issues. In this paper, we develop a novel system, called Spatial Aware Multi-task learning-based Separation (SAMS), to extract audio signals from the target user during teleconferencing. Our solution consists of three novel components: (i) generating fine-grained location embeddings from the user's voice and inaudible tracking sound, which contains the user's position and rich multipath information, (ii) developing a source separation neural network using multi-task learning to jointly optimize source separation and location, and (iii) significantly speeding up inference to provide a real-time guarantee. Our testbed experiments demonstrate the effectiveness of our approach
Cycle Label-Consistent Networks for Unsupervised Domain Adaptation
May 27, 2022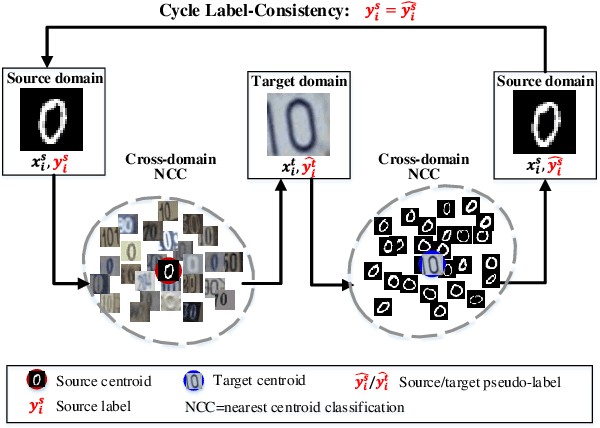
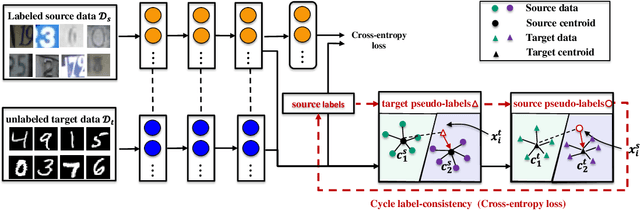
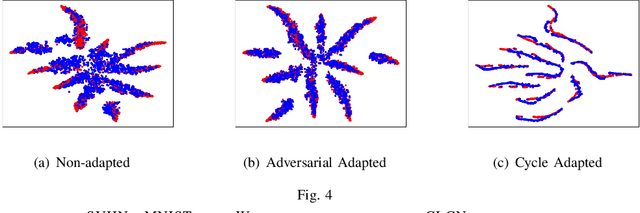
Domain adaptation aims to leverage a labeled source domain to learn a classifier for the unlabeled target domain with a different distribution. Previous methods mostly match the distribution between two domains by global or class alignment. However, global alignment methods cannot achieve a fine-grained class-to-class overlap; class alignment methods supervised by pseudo-labels cannot guarantee their reliability. In this paper, we propose a simple yet efficient domain adaptation method, i.e. Cycle Label-Consistent Network (CLCN), by exploiting the cycle consistency of classification label, which applies dual cross-domain nearest centroid classification procedures to generate a reliable self-supervised signal for the discrimination in the target domain. The cycle label-consistent loss reinforces the consistency between ground-truth labels and pseudo-labels of source samples leading to statistically similar latent representations between source and target domains. This new loss can easily be added to any existing classification network with almost no computational overhead. We demonstrate the effectiveness of our approach on MNIST-USPS-SVHN, Office-31, Office-Home and Image CLEF-DA benchmarks. Results validate that the proposed method can alleviate the negative influence of falsely-labeled samples and learn more discriminative features, leading to the absolute improvement over source-only model by 9.4% on Office-31 and 6.3% on Image CLEF-DA.
Deep face recognition with clustering based domain adaptation
May 27, 2022
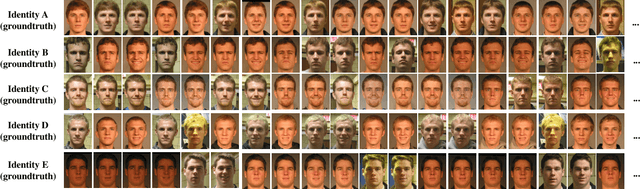
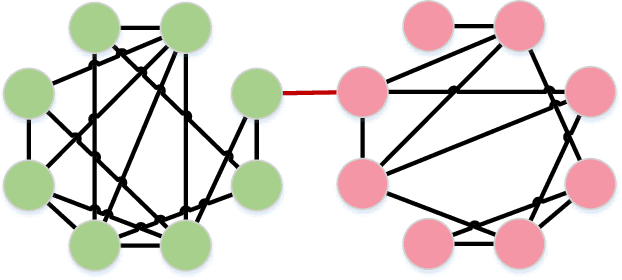
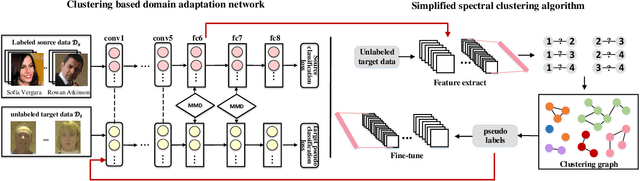
Despite great progress in face recognition tasks achieved by deep convolution neural networks (CNNs), these models often face challenges in real world tasks where training images gathered from Internet are different from test images because of different lighting condition, pose and image quality. These factors increase domain discrepancy between training (source domain) and testing (target domain) database and make the learnt models degenerate in application. Meanwhile, due to lack of labeled target data, directly fine-tuning the pre-learnt models becomes intractable and impractical. In this paper, we propose a new clustering-based domain adaptation method designed for face recognition task in which the source and target domain do not share any classes. Our method effectively learns the discriminative target feature by aligning the feature domain globally, and, at the meantime, distinguishing the target clusters locally. Specifically, it first learns a more reliable representation for clustering by minimizing global domain discrepancy to reduce domain gaps, and then applies simplified spectral clustering method to generate pseudo-labels in the domain-invariant feature space, and finally learns discriminative target representation. Comprehensive experiments on widely-used GBU, IJB-A/B/C and RFW databases clearly demonstrate the effectiveness of our newly proposed approach. State-of-the-art performance of GBU data set is achieved by only unsupervised adaptation from the target training data.