 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch Your Block Floating Point Scales!
May 12, 2026Quantization has emerged as a standard technique for accelerating inference for generative models by enabling faster low-precision computations and reduced memory transfers. Recently, GPU accelerators have added first-class support for microscaling Block Floating Point (BFP) formats. Standard BFP algorithms use a fixed scale based on the maximum magnitude of the block. We observe that this scale choice can be suboptimal with respect to quantization errors. In this work, we propose ScaleSearch, an alternative strategy for selecting these scale factors: using a fine-grained search leveraging the mantissa bits in microscaling formats to minimize the quantization error for the given distribution. ScaleSearch can be integrated with existing quantization methods such as Post Training Quantization and low-precision attention, and is shown to improve their performance. Additionally, we introduce ScaleSearchAttention, an accelerated NVFP4-based attention algorithm, which uses ScaleSearch and adapted prior techniques to ensure near-0 performance loss for causal language modeling. Experiments show that ScaleSearch reduces quantization error by 27% for NVFP4 and improves language model PTQ by up to 15 points for MATH500 (Qwen3-8B), while ScaleSearchAttention improves Wikitext-2 PPL by upto 0.77 points for Llama 3.1 70B. The proposed methods closely match baseline performance while providing quantization accuracy improvements.
Understanding and Steering the Cognitive Behaviors of Reasoning Models at Test-Time
Dec 31, 2025Large Language Models (LLMs) often rely on long chain-of-thought (CoT) reasoning to solve complex tasks. While effective, these trajectories are frequently inefficient, leading to high latency from excessive token generation, or unstable reasoning that alternates between underthinking (shallow, inconsistent steps) and overthinking (repetitive, verbose reasoning). In this work, we study the structure of reasoning trajectories and uncover specialized attention heads that correlate with distinct cognitive behaviors such as verification and backtracking. By lightly intervening on these heads at inference time, we can steer the model away from inefficient modes. Building on this insight, we propose CREST, a training-free method for Cognitive REasoning Steering at Test-time. CREST has two components: (1) an offline calibration step that identifies cognitive heads and derives head-specific steering vectors, and (2) an inference-time procedure that rotates hidden representations to suppress components along those vectors. CREST adaptively suppresses unproductive reasoning behaviors, yielding both higher accuracy and lower computational cost. Across diverse reasoning benchmarks and models, CREST improves accuracy by up to 17.5% while reducing token usage by 37.6%, offering a simple and effective pathway to faster, more reliable LLM reasoning.
Training-Free Activation Sparsity in Large Language Models
Aug 26, 2024Activation sparsity can enable practical inference speedups in large language models (LLMs) by reducing the compute and memory-movement required for matrix multiplications during the forward pass. However, existing methods face limitations that inhibit widespread adoption. Some approaches are tailored towards older models with ReLU-based sparsity, while others require extensive continued pre-training on up to hundreds of billions of tokens. This paper describes TEAL, a simple training-free method that applies magnitude-based activation sparsity to hidden states throughout the entire model. TEAL achieves 40-50% model-wide sparsity with minimal performance degradation across Llama-2, Llama-3, and Mistral families, with sizes varying from 7B to 70B. We improve existing sparse kernels and demonstrate wall-clock decoding speed-ups of up to 1.53$\times$ and 1.8$\times$ at 40% and 50% model-wide sparsity. TEAL is compatible with weight quantization, enabling further efficiency gains.
Mechanistic Design and Scaling of Hybrid Architectures
Mar 26, 2024



The development of deep learning architectures is a resource-demanding process, due to a vast design space, long prototyping times, and high compute costs associated with at-scale model training and evaluation. We set out to simplify this process by grounding it in an end-to-end mechanistic architecture design (MAD) pipeline, encompassing small-scale capability unit tests predictive of scaling laws. Through a suite of synthetic token manipulation tasks such as compression and recall, designed to probe capabilities, we identify and test new hybrid architectures constructed from a variety of computational primitives. We experimentally validate the resulting architectures via an extensive compute-optimal and a new state-optimal scaling law analysis, training over 500 language models between 70M to 7B parameters. Surprisingly, we find MAD synthetics to correlate with compute-optimal perplexity, enabling accurate evaluation of new architectures via isolated proxy tasks. The new architectures found via MAD, based on simple ideas such as hybridization and sparsity, outperform state-of-the-art Transformer, convolutional, and recurrent architectures (Transformer++, Hyena, Mamba) in scaling, both at compute-optimal budgets and in overtrained regimes. Overall, these results provide evidence that performance on curated synthetic tasks can be predictive of scaling laws, and that an optimal architecture should leverage specialized layers via a hybrid topology.
Self-Aware Feedback-Based Self-Learning in Large-Scale Conversational AI
Apr 29, 2022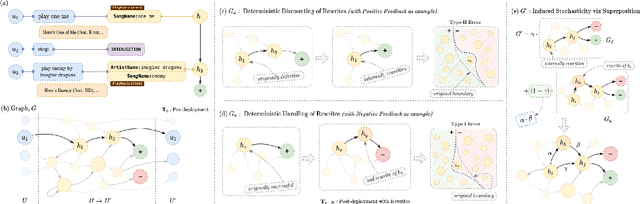
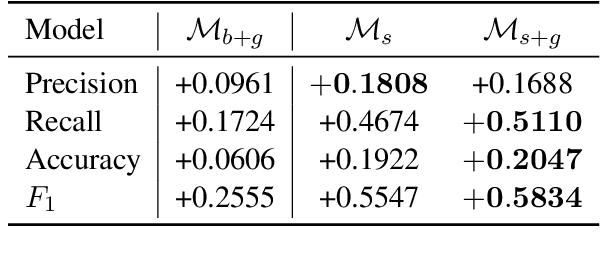

Self-learning paradigms in large-scale conversational AI agents tend to leverage user feedback in bridging between what they say and what they mean. However, such learning, particularly in Markov-based query rewriting systems have far from addressed the impact of these models on future training where successive feedback is inevitably contingent on the rewrite itself, especially in a continually updating environment. In this paper, we explore the consequences of this inherent lack of self-awareness towards impairing the model performance, ultimately resulting in both Type I and II errors over time. To that end, we propose augmenting the Markov Graph construction with a superposition-based adjacency matrix. Here, our method leverages an induced stochasticity to reactively learn a locally-adaptive decision boundary based on the performance of the individual rewrites in a bi-variate beta setting. We also surface a data augmentation strategy that leverages template-based generation in abridging complex conversation hierarchies of dialogs so as to simplify the learning process. All in all, we demonstrate that our self-aware model improves the overall PR-AUC by 27.45%, achieves a relative defect reduction of up to 31.22%, and is able to adapt quicker to changes in global preferences across a large number of customers.
A Vocabulary-Free Multilingual Neural Tokenizer for End-to-End Task Learning
Apr 22, 2022
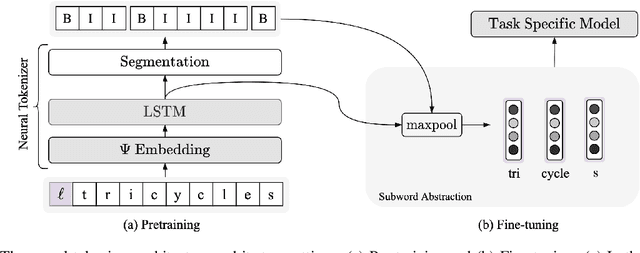
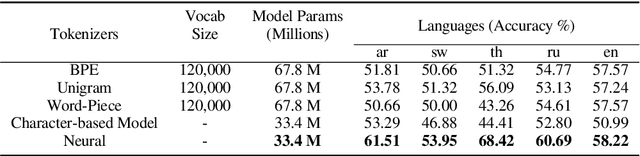

Subword tokenization is a commonly used input pre-processing step in most recent NLP models. However, it limits the models' ability to leverage end-to-end task learning. Its frequency-based vocabulary creation compromises tokenization in low-resource languages, leading models to produce suboptimal representations. Additionally, the dependency on a fixed vocabulary limits the subword models' adaptability across languages and domains. In this work, we propose a vocabulary-free neural tokenizer by distilling segmentation information from heuristic-based subword tokenization. We pre-train our character-based tokenizer by processing unique words from multilingual corpus, thereby extensively increasing word diversity across languages. Unlike the predefined and fixed vocabularies in subword methods, our tokenizer allows end-to-end task learning, resulting in optimal task-specific tokenization. The experimental results show that replacing the subword tokenizer with our neural tokenizer consistently improves performance on multilingual (NLI) and code-switching (sentiment analysis) tasks, with larger gains in low-resource languages. Additionally, our neural tokenizer exhibits a robust performance on downstream tasks when adversarial noise is present (typos and misspelling), further increasing the initial improvements over statistical subword tokenizers.
Personalized Query Rewriting in Conversational AI Agents
Nov 09, 2020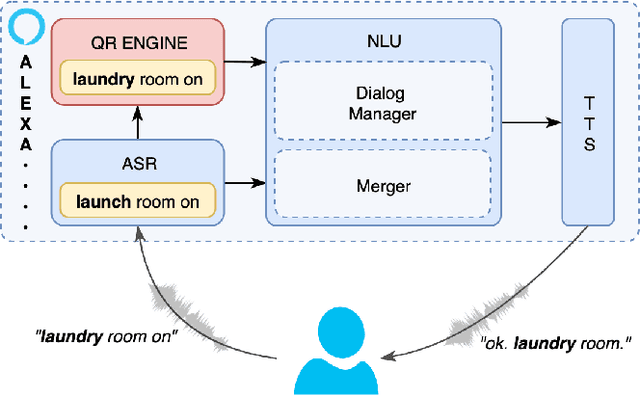
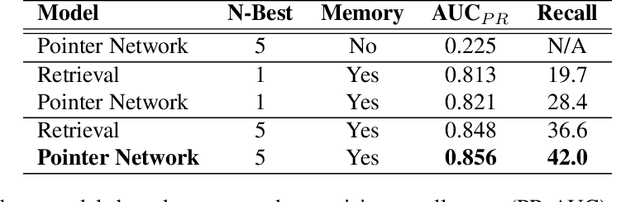
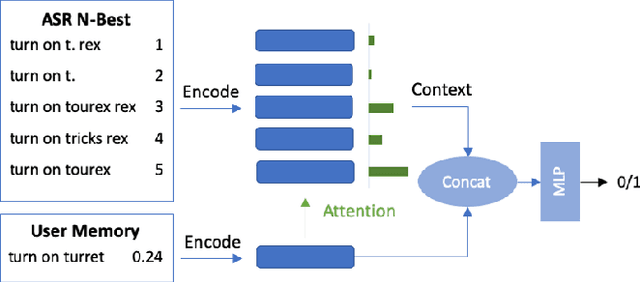
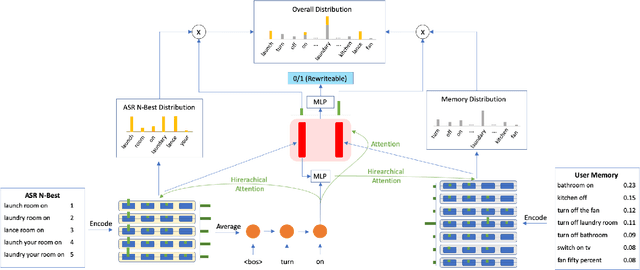
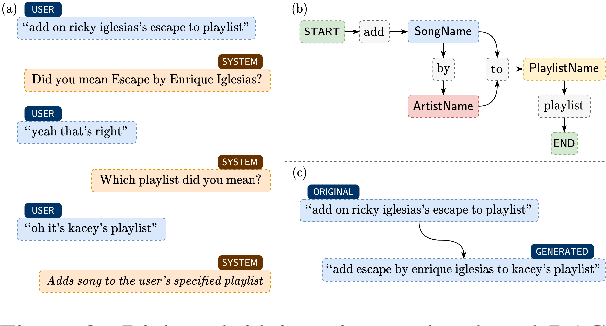
Spoken language understanding (SLU) systems in conversational AI agents often experience errors in the form of misrecognitions by automatic speech recognition (ASR) or semantic gaps in natural language understanding (NLU). These errors easily translate to user frustrations, particularly so in recurrent events e.g. regularly toggling an appliance, calling a frequent contact, etc. In this work, we propose a query rewriting approach by leveraging users' historically successful interactions as a form of memory. We present a neural retrieval model and a pointer-generator network with hierarchical attention and show that they perform significantly better at the query rewriting task with the aforementioned user memories than without. We also highlight how our approach with the proposed models leverages the structural and semantic diversity in ASR's output towards recovering users' intents.
Feedback-Based Self-Learning in Large-Scale Conversational AI Agents
Nov 06, 2019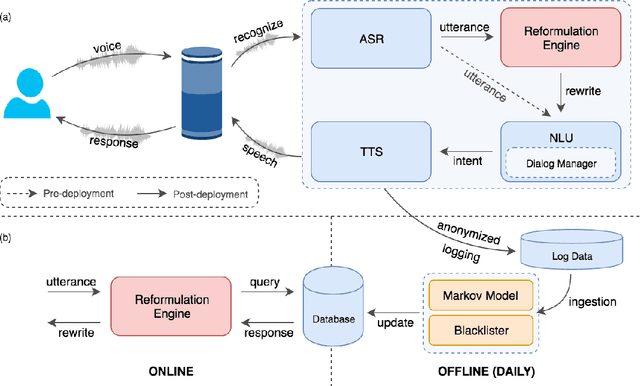

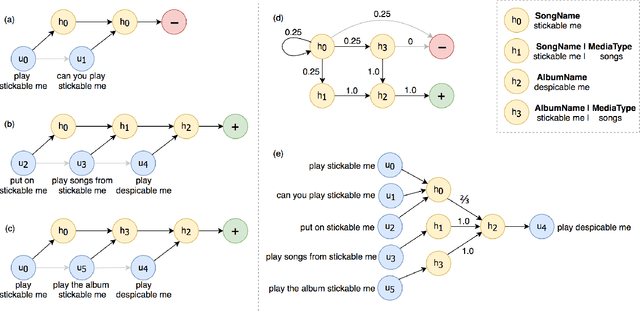
Today, most large-scale conversational AI agents (e.g. Alexa, Siri, or Google Assistant) are built using manually annotated data to train the different components of the system. Typically, the accuracy of the ML models in these components are improved by manually transcribing and annotating data. As the scope of these systems increase to cover more scenarios and domains, manual annotation to improve the accuracy of these components becomes prohibitively costly and time consuming. In this paper, we propose a system that leverages user-system interaction feedback signals to automate learning without any manual annotation. Users here tend to modify a previous query in hopes of fixing an error in the previous turn to get the right results. These reformulations, which are often preceded by defective experiences caused by errors in ASR, NLU, ER or the application. In some cases, users may not properly formulate their requests (e.g. providing partial title of a song), but gleaning across a wider pool of users and sessions reveals the underlying recurrent patterns. Our proposed self-learning system automatically detects the errors, generate reformulations and deploys fixes to the runtime system to correct different types of errors occurring in different components of the system. In particular, we propose leveraging an absorbing Markov Chain model as a collaborative filtering mechanism in a novel attempt to mine these patterns. We show that our approach is highly scalable, and able to learn reformulations that reduce Alexa-user errors by pooling anonymized data across millions of customers. The proposed self-learning system achieves a win/loss ratio of 11.8 and effectively reduces the defect rate by more than 30% on utterance level reformulations in our production A/B tests. To the best of our knowledge, this is the first self-learning large-scale conversational AI system in production.