 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling interdisciplinary interactions among Physics, Mathematics & Computer Science
Sep 19, 2023Interdisciplinarity has over the recent years have gained tremendous importance and has become one of the key ways of doing cutting edge research. In this paper we attempt to model the citation flow across three different fields -- Physics (PHY), Mathematics (MA) and Computer Science (CS). For instance, is there a specific pattern in which these fields cite one another? We carry out experiments on a dataset comprising more than 1.2 million articles taken from these three fields. We quantify the citation interactions among these three fields through temporal bucket signatures. We present numerical models based on variants of the recently proposed relay-linking framework to explain the citation dynamics across the three disciplines. These models make a modest attempt to unfold the underlying principles of how citation links could have been formed across the three fields over time.
Metric@CustomerN: Evaluating Metrics at a Customer Level in E-Commerce
Jul 31, 2023Accuracy measures such as Recall, Precision, and Hit Rate have been a standard way of evaluating Recommendation Systems. The assumption is to use a fixed Top-N to represent them. We propose that median impressions viewed from historical sessions per diner be used as a personalized value for N. We present preliminary exploratory results and list future steps to improve upon and evaluate the efficacy of these personalized metrics.
Analogy-Forming Transformers for Few-Shot 3D Parsing
Apr 27, 2023We present Analogical Networks, a model that encodes domain knowledge explicitly, in a collection of structured labelled 3D scenes, in addition to implicitly, as model parameters, and segments 3D object scenes with analogical reasoning: instead of mapping a scene to part segments directly, our model first retrieves related scenes from memory and their corresponding part structures, and then predicts analogous part structures for the input scene, via an end-to-end learnable modulation mechanism. By conditioning on more than one retrieved memories, compositions of structures are predicted, that mix and match parts across the retrieved memories. One-shot, few-shot or many-shot learning are treated uniformly in Analogical Networks, by conditioning on the appropriate set of memories, whether taken from a single, few or many memory exemplars, and inferring analogous parses. We show Analogical Networks are competitive with state-of-the-art 3D segmentation transformers in many-shot settings, and outperform them, as well as existing paradigms of meta-learning and few-shot learning, in few-shot settings. Analogical Networks successfully segment instances of novel object categories simply by expanding their memory, without any weight updates. Our code and models are publicly available in the project webpage: http://analogicalnets.github.io/.
MMT: A Multilingual and Multi-Topic Indian Social Media Dataset
Apr 02, 2023Social media plays a significant role in cross-cultural communication. A vast amount of this occurs in code-mixed and multilingual form, posing a significant challenge to Natural Language Processing (NLP) tools for processing such information, like language identification, topic modeling, and named-entity recognition. To address this, we introduce a large-scale multilingual, and multi-topic dataset (MMT) collected from Twitter (1.7 million Tweets), encompassing 13 coarse-grained and 63 fine-grained topics in the Indian context. We further annotate a subset of 5,346 tweets from the MMT dataset with various Indian languages and their code-mixed counterparts. Also, we demonstrate that the currently existing tools fail to capture the linguistic diversity in MMT on two downstream tasks, i.e., topic modeling and language identification. To facilitate future research, we will make the anonymized and annotated dataset available in the public domain.
MUTANT: A Multi-sentential Code-mixed Hinglish Dataset
Feb 23, 2023



The multi-sentential long sequence textual data unfolds several interesting research directions pertaining to natural language processing and generation. Though we observe several high-quality long-sequence datasets for English and other monolingual languages, there is no significant effort in building such resources for code-mixed languages such as Hinglish (code-mixing of Hindi-English). In this paper, we propose a novel task of identifying multi-sentential code-mixed text (MCT) from multilingual articles. As a use case, we leverage multilingual articles from two different data sources and build a first-of-its-kind multi-sentential code-mixed Hinglish dataset i.e., MUTANT. We propose a token-level language-aware pipeline and extend the existing metrics measuring the degree of code-mixing to a multi-sentential framework and automatically identify MCT in the multilingual articles. The MUTANT dataset comprises 67k articles with 85k identified Hinglish MCTs. To facilitate future research, we make the publicly available.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Tables to LaTeX: structure and content extraction from scientific tables
Oct 31, 2022Scientific documents contain tables that list important information in a concise fashion. Structure and content extraction from tables embedded within PDF research documents is a very challenging task due to the existence of visual features like spanning cells and content features like mathematical symbols and equations. Most existing table structure identification methods tend to ignore these academic writing features. In this paper, we adapt the transformer-based language modeling paradigm for scientific table structure and content extraction. Specifically, the proposed model converts a tabular image to its corresponding LaTeX source code. Overall, we outperform the current state-of-the-art baselines and achieve an exact match accuracy of 70.35 and 49.69% on table structure and content extraction, respectively. Further analysis demonstrates that the proposed models efficiently identify the number of rows and columns, the alphanumeric characters, the LaTeX tokens, and symbols.
The Inefficiency of Language Models in Scholarly Retrieval: An Experimental Walk-through
Mar 29, 2022
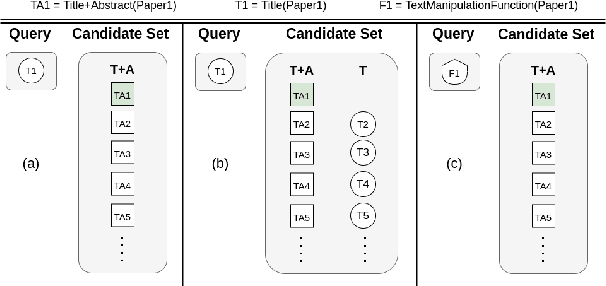
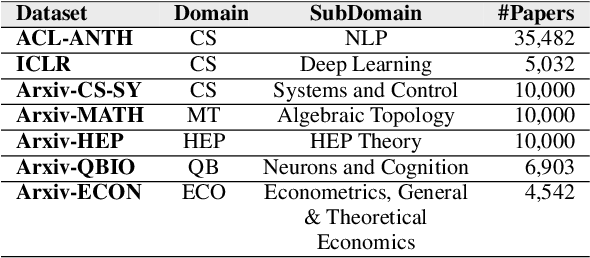
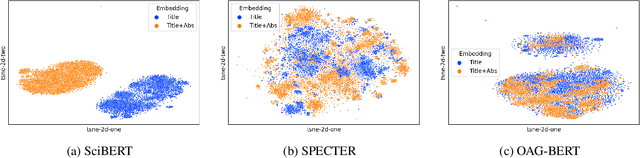
Language models are increasingly becoming popular in AI-powered scientific IR systems. This paper evaluates popular scientific language models in handling (i) short-query texts and (ii) textual neighbors. Our experiments showcase the inability to retrieve relevant documents for a short-query text even under the most relaxed conditions. Additionally, we leverage textual neighbors, generated by small perturbations to the original text, to demonstrate that not all perturbations lead to close neighbors in the embedding space. Further, an exhaustive categorization yields several classes of orthographically and semantically related, partially related, and completely unrelated neighbors. Retrieval performance turns out to be more influenced by the surface form rather than the semantics of the text.
COMPARE: A Taxonomy and Dataset of Comparison Discussions in Peer Reviews
Aug 09, 2021
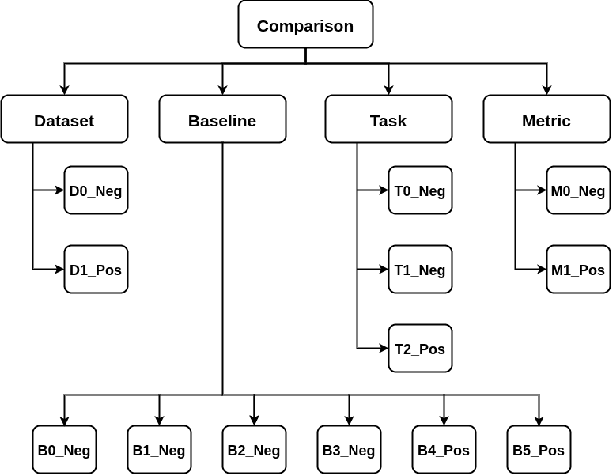
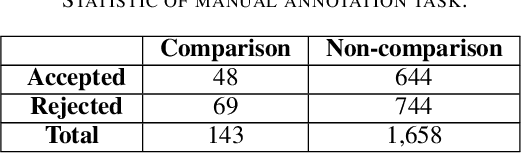
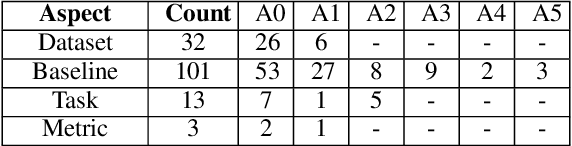
Comparing research papers is a conventional method to demonstrate progress in experimental research. We present COMPARE, a taxonomy and a dataset of comparison discussions in peer reviews of research papers in the domain of experimental deep learning. From a thorough observation of a large set of review sentences, we build a taxonomy of categories in comparison discussions and present a detailed annotation scheme to analyze this. Overall, we annotate 117 reviews covering 1,800 sentences. We experiment with various methods to identify comparison sentences in peer reviews and report a maximum F1 Score of 0.49. We also pretrain two language models specifically on ML, NLP, and CV paper abstracts and reviews to learn informative representations of peer reviews. The annotated dataset and the pretrained models are available at https://github.com/shruti-singh/COMPARE .
Quality Evaluation of the Low-Resource Synthetically Generated Code-Mixed Hinglish Text
Aug 04, 2021

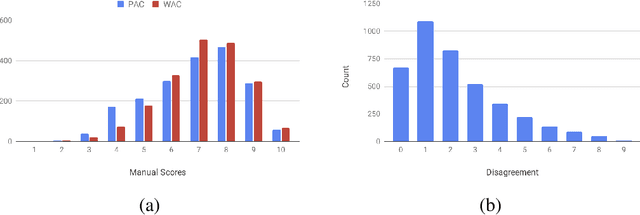

In this shared task, we seek the participating teams to investigate the factors influencing the quality of the code-mixed text generation systems. We synthetically generate code-mixed Hinglish sentences using two distinct approaches and employ human annotators to rate the generation quality. We propose two subtasks, quality rating prediction and annotators' disagreement prediction of the synthetic Hinglish dataset. The proposed subtasks will put forward the reasoning and explanation of the factors influencing the quality and human perception of the code-mixed text.