 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemocratic ICAI: Debating Our Way to Steering Principles from Preferences
Jun 26, 2026Preference-based alignment often struggles to capture the reasoning that underlies human judgments. Many evaluations rely on multiple interacting criteria, yet pairwise labels reveal only the final choice rather than the considerations that shape preferences. Inverse Constitutional AI (ICAI) improves interpretability in decision making by summarizing preferences into natural-language principles, but its single-pass explanations miss much of the nuance involved in complex decisions. We introduce Democratic ICAI, a novel approach that gathers multiple competing rationales through structured persona debate, offering a broader and more expressive account of the factors influencing each comparison. From these richer signals, we derive clearer and more comprehensive steering principles and use them to guide decision modeling through both LLM-based and decision-tree judges. Experiments on creative preference benchmarks, MuCE-Pref and LiTBench, across multiple creative task categories show that Democratic ICAI yields a more faithful preference structure. It improves average preference prediction across tasks relative to deliberative prompting and principle-based baselines, while producing constitutions that LLM annotators prefer.
Polaris: A Gödel Agent Framework for Small Language Models through Experience-Abstracted Policy Repair
Mar 24, 2026Gödel agent realize recursive self-improvement: an agent inspects its own policy and traces and then modifies that policy in a tested loop. We introduce Polaris, a Gödel agent for compact models that performs policy repair via experience abstraction, turning failures into policy updates through a structured cycle of analysis, strategy formation, abstraction, and minimal code pat ch repair with conservative checks. Unlike response level self correction or parameter tuning, Polaris makes policy level changes with small, auditable patches that persist in the policy and are reused on unseen instances within each benchmark. As part of the loop, the agent engages in meta reasoning: it explains its errors, proposes concrete revisions to its own policy, and then updates the policy. To enable cumulative policy refinement, we introduce experience abstraction, which distills failures into compact, reusable strategies that transfer to unseen instances. On MGSM, DROP, GPQA, and LitBench (covering arithmetic reasoning, compositional inference, graduate-level problem solving, and creative writing evaluation), a 7-billion-parameter model equipped with Polaris achieves consistent gains over the base policy and competitive baselines.
Forgetting is Competition: Rethinking Unlearning as Representation Interference in Diffusion Models
Mar 01, 2026Unlearning in text-to-image diffusion models often leads to uneven concept removal and unintended forgetting of unrelated capabilities. This complicates tasks such as copyright compliance, protected data mitigation, artist opt-outs, and policy-driven content updates. As models grow larger and adopt more diverse architectures, achieving precise and selective unlearning while preserving generative quality becomes increasingly challenging. We introduce SurgUn (pronounced as Surgeon), a surgical unlearning method that applies targeted weight-space updates to remove specific visual concepts in text-conditioned diffusion models. Our approach is motivated by retroactive interference theory, which holds that newly acquired memories can overwrite, suppress, or impede access to prior ones by competing for shared representational pathways. We adapt this principle to diffusion models by inducing retroactive concept interference, enabling focused destabilization of only the target concept while preserving unrelated capabilities through a novel training paradigm. SurgUn achieves high-precision unlearning across diverse settings. It performs strongly on compact U-Net based models such as Stable Diffusion v1.5, scales effectively to the larger U-Net architecture SDXL, and extends to SANA, representing an underexplored Diffusion Transformer based architecture for unlearning.
Style Based Clustering of Visual Artworks
Sep 12, 2024



Clustering artworks based on style has many potential real-world applications like art recommendations, style-based search and retrieval, and the study of artistic style evolution in an artwork corpus. However, clustering artworks based on style is largely an unaddressed problem. A few present methods for clustering artworks principally rely on generic image feature representations derived from deep neural networks and do not specifically deal with the artistic style. In this paper, we introduce and deliberate over the notion of style-based clustering of visual artworks. Our main objective is to explore neural feature representations and architectures that can be used for style-based clustering and observe their impact and effectiveness. We develop different methods and assess their relative efficacy for style-based clustering through qualitative and quantitative analysis by applying them to four artwork corpora and four curated synthetically styled datasets. Our analysis provides some key novel insights on architectures, feature representations, and evaluation methods suitable for style-based clustering.
MMT: A Multilingual and Multi-Topic Indian Social Media Dataset
Apr 02, 2023Social media plays a significant role in cross-cultural communication. A vast amount of this occurs in code-mixed and multilingual form, posing a significant challenge to Natural Language Processing (NLP) tools for processing such information, like language identification, topic modeling, and named-entity recognition. To address this, we introduce a large-scale multilingual, and multi-topic dataset (MMT) collected from Twitter (1.7 million Tweets), encompassing 13 coarse-grained and 63 fine-grained topics in the Indian context. We further annotate a subset of 5,346 tweets from the MMT dataset with various Indian languages and their code-mixed counterparts. Also, we demonstrate that the currently existing tools fail to capture the linguistic diversity in MMT on two downstream tasks, i.e., topic modeling and language identification. To facilitate future research, we will make the anonymized and annotated dataset available in the public domain.
MUTANT: A Multi-sentential Code-mixed Hinglish Dataset
Feb 23, 2023



The multi-sentential long sequence textual data unfolds several interesting research directions pertaining to natural language processing and generation. Though we observe several high-quality long-sequence datasets for English and other monolingual languages, there is no significant effort in building such resources for code-mixed languages such as Hinglish (code-mixing of Hindi-English). In this paper, we propose a novel task of identifying multi-sentential code-mixed text (MCT) from multilingual articles. As a use case, we leverage multilingual articles from two different data sources and build a first-of-its-kind multi-sentential code-mixed Hinglish dataset i.e., MUTANT. We propose a token-level language-aware pipeline and extend the existing metrics measuring the degree of code-mixing to a multi-sentential framework and automatically identify MCT in the multilingual articles. The MUTANT dataset comprises 67k articles with 85k identified Hinglish MCTs. To facilitate future research, we make the publicly available.
Quality Evaluation of the Low-Resource Synthetically Generated Code-Mixed Hinglish Text
Aug 04, 2021

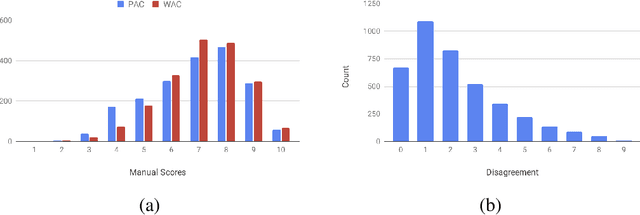

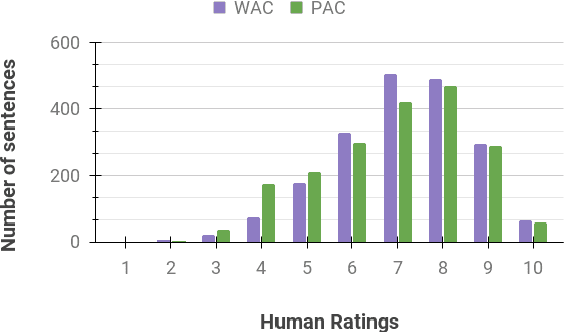
In this shared task, we seek the participating teams to investigate the factors influencing the quality of the code-mixed text generation systems. We synthetically generate code-mixed Hinglish sentences using two distinct approaches and employ human annotators to rate the generation quality. We propose two subtasks, quality rating prediction and annotators' disagreement prediction of the synthetic Hinglish dataset. The proposed subtasks will put forward the reasoning and explanation of the factors influencing the quality and human perception of the code-mixed text.
MIPE: A Metric Independent Pipeline for Effective Code-Mixed NLG Evaluation
Jul 24, 2021
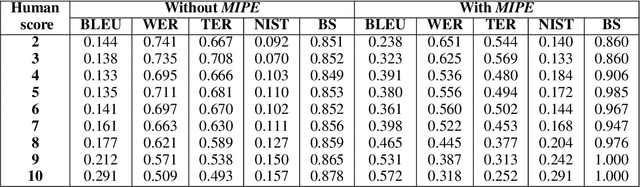
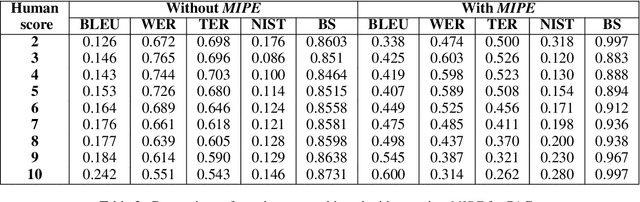
Code-mixing is a phenomenon of mixing words and phrases from two or more languages in a single utterance of speech and text. Due to the high linguistic diversity, code-mixing presents several challenges in evaluating standard natural language generation (NLG) tasks. Various widely popular metrics perform poorly with the code-mixed NLG tasks. To address this challenge, we present a metric independent evaluation pipeline MIPE that significantly improves the correlation between evaluation metrics and human judgments on the generated code-mixed text. As a use case, we demonstrate the performance of MIPE on the machine-generated Hinglish (code-mixing of Hindi and English languages) sentences from the HinGE corpus. We can extend the proposed evaluation strategy to other code-mixed language pairs, NLG tasks, and evaluation metrics with minimal to no effort.
HinGE: A Dataset for Generation and Evaluation of Code-Mixed Hinglish Text
Jul 08, 2021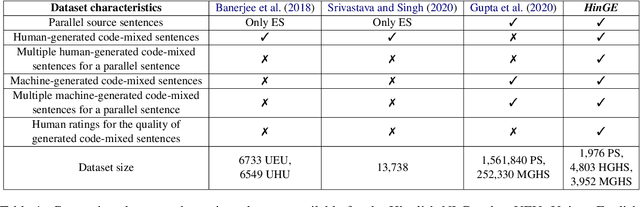



Text generation is a highly active area of research in the computational linguistic community. The evaluation of the generated text is a challenging task and multiple theories and metrics have been proposed over the years. Unfortunately, text generation and evaluation are relatively understudied due to the scarcity of high-quality resources in code-mixed languages where the words and phrases from multiple languages are mixed in a single utterance of text and speech. To address this challenge, we present a corpus (HinGE) for a widely popular code-mixed language Hinglish (code-mixing of Hindi and English languages). HinGE has Hinglish sentences generated by humans as well as two rule-based algorithms corresponding to the parallel Hindi-English sentences. In addition, we demonstrate the inefficacy of widely-used evaluation metrics on the code-mixed data. The HinGE dataset will facilitate the progress of natural language generation research in code-mixed languages.
Challenges and Limitations with the Metrics Measuring the Complexity of Code-Mixed Text
Jun 18, 2021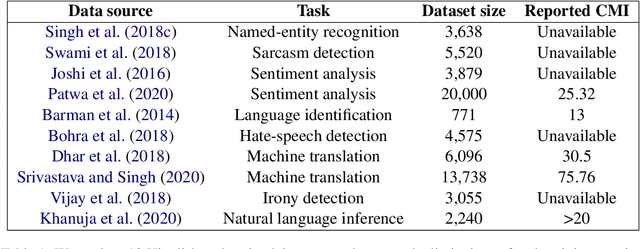

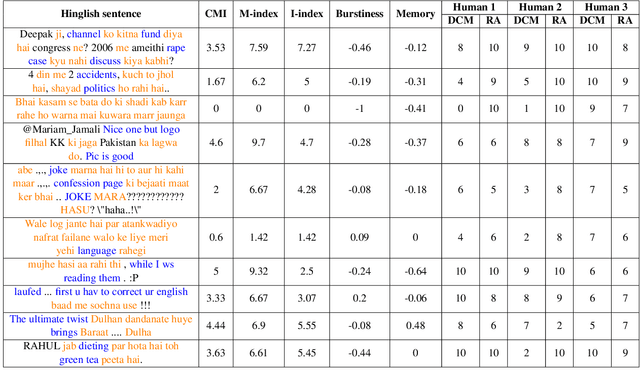
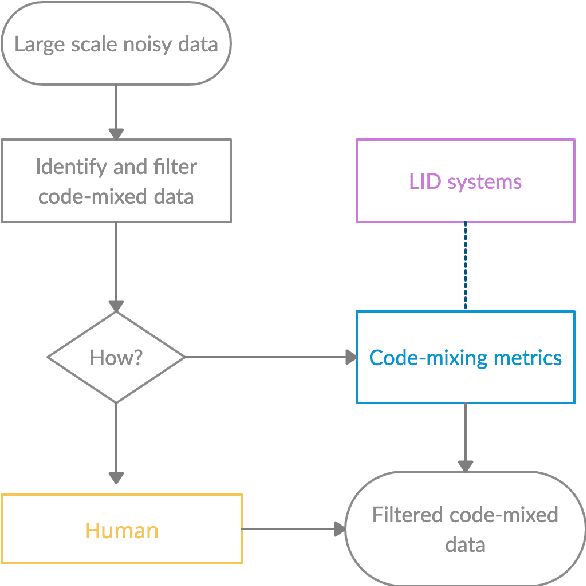
Code-mixing is a frequent communication style among multilingual speakers where they mix words and phrases from two different languages in the same utterance of text or speech. Identifying and filtering code-mixed text is a challenging task due to its co-existence with monolingual and noisy text. Over the years, several code-mixing metrics have been extensively used to identify and validate code-mixed text quality. This paper demonstrates several inherent limitations of code-mixing metrics with examples from the already existing datasets that are popularly used across various experiments.