 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciDQA: A Deep Reading Comprehension Dataset over Scientific Papers
Nov 08, 2024



Scientific literature is typically dense, requiring significant background knowledge and deep comprehension for effective engagement. We introduce SciDQA, a new dataset for reading comprehension that challenges LLMs for a deep understanding of scientific articles, consisting of 2,937 QA pairs. Unlike other scientific QA datasets, SciDQA sources questions from peer reviews by domain experts and answers by paper authors, ensuring a thorough examination of the literature. We enhance the dataset's quality through a process that carefully filters out lower quality questions, decontextualizes the content, tracks the source document across different versions, and incorporates a bibliography for multi-document question-answering. Questions in SciDQA necessitate reasoning across figures, tables, equations, appendices, and supplementary materials, and require multi-document reasoning. We evaluate several open-source and proprietary LLMs across various configurations to explore their capabilities in generating relevant and factual responses. Our comprehensive evaluation, based on metrics for surface-level similarity and LLM judgements, highlights notable performance discrepancies. SciDQA represents a rigorously curated, naturally derived scientific QA dataset, designed to facilitate research on complex scientific text understanding.
Speech Recognition Transformers: Topological-lingualism Perspective
Aug 27, 2024



Transformers have evolved with great success in various artificial intelligence tasks. Thanks to our recent prevalence of self-attention mechanisms, which capture long-term dependency, phenomenal outcomes in speech processing and recognition tasks have been produced. The paper presents a comprehensive survey of transformer techniques oriented in speech modality. The main contents of this survey include (1) background of traditional ASR, end-to-end transformer ecosystem, and speech transformers (2) foundational models in a speech via lingualism paradigm, i.e., monolingual, bilingual, multilingual, and cross-lingual (3) dataset and languages, acoustic features, architecture, decoding, and evaluation metric from a specific topological lingualism perspective (4) popular speech transformer toolkit for building end-to-end ASR systems. Finally, highlight the discussion of open challenges and potential research directions for the community to conduct further research in this domain.
SciRIFF: A Resource to Enhance Language Model Instruction-Following over Scientific Literature
Jun 10, 2024



We present SciRIFF (Scientific Resource for Instruction-Following and Finetuning), a dataset of 137K instruction-following demonstrations for 54 tasks covering five essential scientific literature understanding capabilities: information extraction, summarization, question answering, claim verification, and classification. SciRIFF demonstrations are notable for their long input contexts, detailed task specifications, and complex structured outputs. While instruction-following resources are available in specific domains such as clinical medicine and chemistry, SciRIFF is the first dataset focused on extracting and synthesizing information from research literature across a wide range of scientific fields. To demonstrate the utility of SciRIFF, we develop a sample-efficient strategy to adapt a general instruction-following model for science by performing additional finetuning on a mix of general-domain and SciRIFF demonstrations. In evaluations on nine held-out scientific tasks, our model -- called SciTulu -- improves over a strong LLM baseline by 28.1% and 6.5% at the 7B and 70B scales respectively, while maintaining general instruction-following performance within 2% of the baseline. We are optimistic that SciRIFF will facilitate the development and evaluation of LLMs to help researchers navigate the ever-growing body of scientific literature. We release our dataset, model checkpoints, and data processing and evaluation code to enable further research.
Sparse Graph Representations for Procedural Instructional Documents
Feb 06, 2024


Computation of document similarity is a critical task in various NLP domains that has applications in deduplication, matching, and recommendation. Traditional approaches for document similarity computation include learning representations of documents and employing a similarity or a distance function over the embeddings. However, pairwise similarities and differences are not efficiently captured by individual representations. Graph representations such as Joint Concept Interaction Graph (JCIG) represent a pair of documents as a joint undirected weighted graph. JCIGs facilitate an interpretable representation of document pairs as a graph. However, JCIGs are undirected, and don't consider the sequential flow of sentences in documents. We propose two approaches to model document similarity by representing document pairs as a directed and sparse JCIG that incorporates sequential information. We propose two algorithms inspired by Supergenome Sorting and Hamiltonian Path that replace the undirected edges with directed edges. Our approach also sparsifies the graph to $O(n)$ edges from JCIG's worst case of $O(n^2)$. We show that our sparse directed graph model architecture consisting of a Siamese encoder and GCN achieves comparable results to the baseline on datasets not containing sequential information and beats the baseline by ten points on an instructional documents dataset containing sequential information.
LEGOBench: Leaderboard Generation Benchmark for Scientific Models
Jan 11, 2024The ever-increasing volume of paper submissions makes it difficult to stay informed about the latest state-of-the-art research. To address this challenge, we introduce LEGOBench, a benchmark for evaluating systems that generate leaderboards. LEGOBench is curated from 22 years of preprint submission data in arXiv and more than 11,000 machine learning leaderboards in the PapersWithCode portal. We evaluate the performance of four traditional graph-based ranking variants and three recently proposed large language models. Our preliminary results show significant performance gaps in automatic leaderboard generation. The code is available on https://github.com/lingo-iitgn/LEGOBench and the dataset is hosted on https://osf.io/9v2py/?view_only=6f91b0b510df498ba01595f8f278f94c .
Unlocking Model Insights: A Dataset for Automated Model Card Generation
Sep 22, 2023



Language models (LMs) are no longer restricted to ML community, and instruction-tuned LMs have led to a rise in autonomous AI agents. As the accessibility of LMs grows, it is imperative that an understanding of their capabilities, intended usage, and development cycle also improves. Model cards are a popular practice for documenting detailed information about an ML model. To automate model card generation, we introduce a dataset of 500 question-answer pairs for 25 ML models that cover crucial aspects of the model, such as its training configurations, datasets, biases, architecture details, and training resources. We employ annotators to extract the answers from the original paper. Further, we explore the capabilities of LMs in generating model cards by answering questions. Our initial experiments with ChatGPT-3.5, LLaMa, and Galactica showcase a significant gap in the understanding of research papers by these aforementioned LMs as well as generating factual textual responses. We posit that our dataset can be used to train models to automate the generation of model cards from paper text and reduce human effort in the model card curation process. The complete dataset is available on https://osf.io/hqt7p/?view_only=3b9114e3904c4443bcd9f5c270158d37
The Inefficiency of Language Models in Scholarly Retrieval: An Experimental Walk-through
Mar 29, 2022
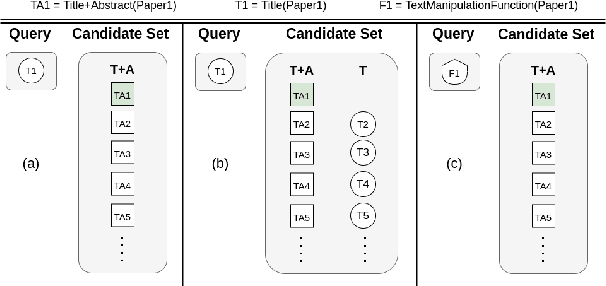
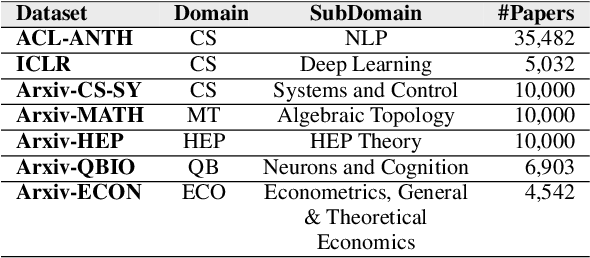
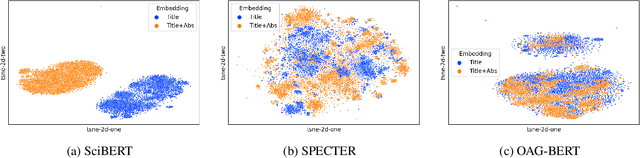
Language models are increasingly becoming popular in AI-powered scientific IR systems. This paper evaluates popular scientific language models in handling (i) short-query texts and (ii) textual neighbors. Our experiments showcase the inability to retrieve relevant documents for a short-query text even under the most relaxed conditions. Additionally, we leverage textual neighbors, generated by small perturbations to the original text, to demonstrate that not all perturbations lead to close neighbors in the embedding space. Further, an exhaustive categorization yields several classes of orthographically and semantically related, partially related, and completely unrelated neighbors. Retrieval performance turns out to be more influenced by the surface form rather than the semantics of the text.
COMPARE: A Taxonomy and Dataset of Comparison Discussions in Peer Reviews
Aug 09, 2021
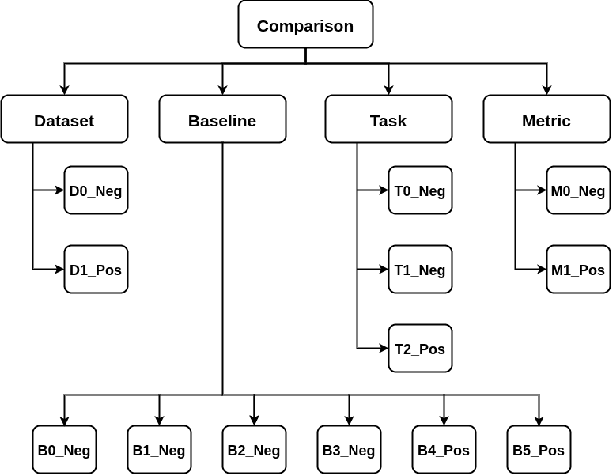
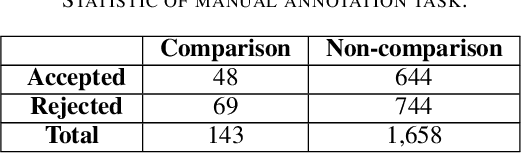
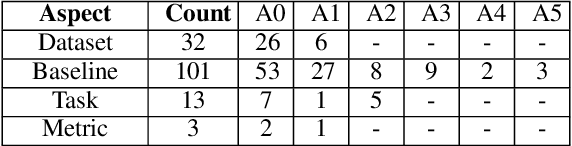
Comparing research papers is a conventional method to demonstrate progress in experimental research. We present COMPARE, a taxonomy and a dataset of comparison discussions in peer reviews of research papers in the domain of experimental deep learning. From a thorough observation of a large set of review sentences, we build a taxonomy of categories in comparison discussions and present a detailed annotation scheme to analyze this. Overall, we annotate 117 reviews covering 1,800 sentences. We experiment with various methods to identify comparison sentences in peer reviews and report a maximum F1 Score of 0.49. We also pretrain two language models specifically on ML, NLP, and CV paper abstracts and reviews to learn informative representations of peer reviews. The annotated dataset and the pretrained models are available at https://github.com/shruti-singh/COMPARE .
TweeNLP: A Twitter Exploration Portal for Natural Language Processing
Jun 19, 2021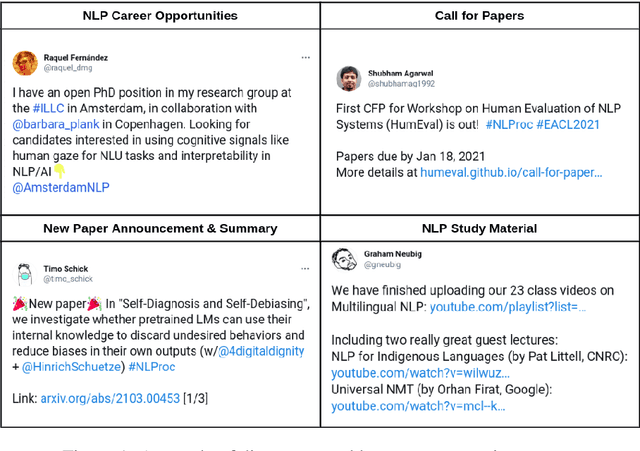
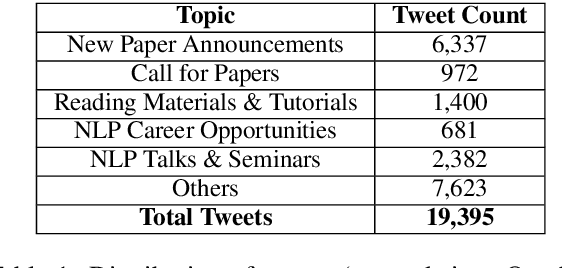
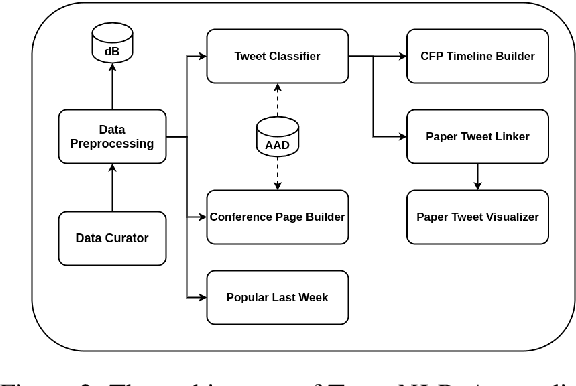
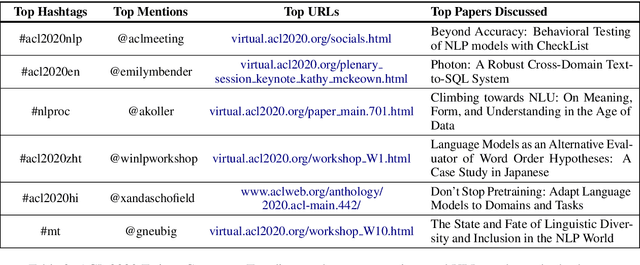
We present TweeNLP, a one-stop portal that organizes Twitter's natural language processing (NLP) data and builds a visualization and exploration platform. It curates 19,395 tweets (as of April 2021) from various NLP conferences and general NLP discussions. It supports multiple features such as TweetExplorer to explore tweets by topics, visualize insights from Twitter activity throughout the organization cycle of conferences, discover popular research papers and researchers. It also builds a timeline of conference and workshop submission deadlines. We envision TweeNLP to function as a collective memory unit for the NLP community by integrating the tweets pertaining to research papers with the NLPExplorer scientific literature search engine. The current system is hosted at http://nlpexplorer.org/twitter/CFP .
Understanding Attention: In Minds and Machines
Dec 04, 2020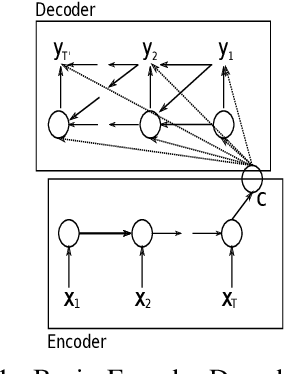
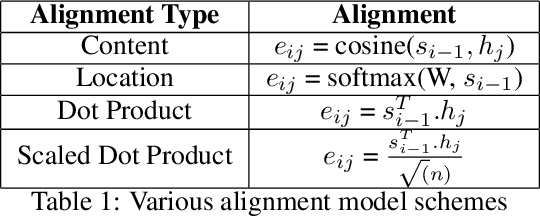
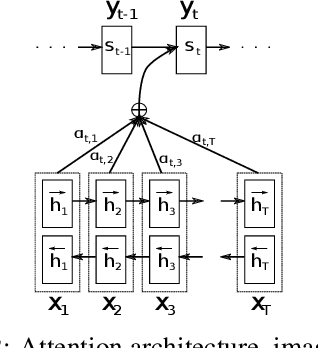
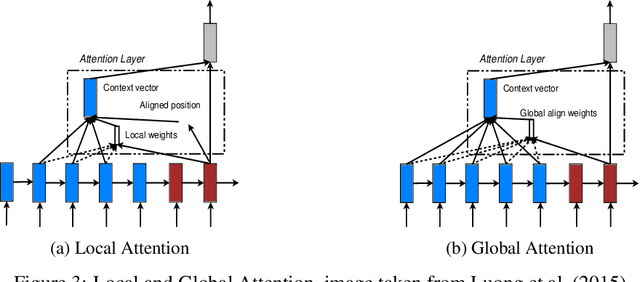
Attention is a complex and broad concept, studied across multiple disciplines spanning artificial intelligence, cognitive science, psychology, neuroscience, and related fields. Although many of the ideas regarding attention do not significantly overlap among these fields, there is a common theme of adaptive control of limited resources. In this work, we review the concept and variants of attention in artificial neural networks (ANNs). We also discuss the origin of attention from the neuroscience point of view parallel to that of ANNs. Instead of having seemingly disconnected dialogues between varied disciplines, we suggest grounding the ideas on common conceptual frameworks for a systematic analysis of attention and towards possible unification of ideas in AI and Neuroscience.