 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Masked Attention Policies for Reliable Generalization
Feb 23, 2026In reinforcement learning, abstraction methods that remove unnecessary information from the observation are commonly used to learn policies which generalize better to unseen tasks. However, these methods often overlook a crucial weakness: the function which extracts the reduced-information representation has unknown generalization ability in unseen observations. In this paper, we address this problem by presenting an information removal method which more reliably generalizes to new states. We accomplish this by using a learned masking function which operates on, and is integrated with, the attention weights within an attention-based policy network. We demonstrate that our method significantly improves policy generalization to unseen tasks in the Procgen benchmark compared to standard PPO and masking approaches.
Universal Value-Function Uncertainties
May 27, 2025


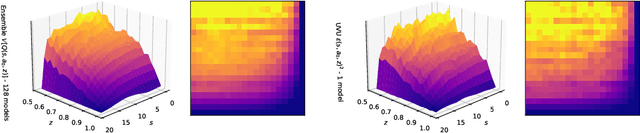
Estimating epistemic uncertainty in value functions is a crucial challenge for many aspects of reinforcement learning (RL), including efficient exploration, safe decision-making, and offline RL. While deep ensembles provide a robust method for quantifying value uncertainty, they come with significant computational overhead. Single-model methods, while computationally favorable, often rely on heuristics and typically require additional propagation mechanisms for myopic uncertainty estimates. In this work we introduce universal value-function uncertainties (UVU), which, similar in spirit to random network distillation (RND), quantify uncertainty as squared prediction errors between an online learner and a fixed, randomly initialized target network. Unlike RND, UVU errors reflect policy-conditional value uncertainty, incorporating the future uncertainties any given policy may encounter. This is due to the training procedure employed in UVU: the online network is trained using temporal difference learning with a synthetic reward derived from the fixed, randomly initialized target network. We provide an extensive theoretical analysis of our approach using neural tangent kernel (NTK) theory and show that in the limit of infinite network width, UVU errors are exactly equivalent to the variance of an ensemble of independent universal value functions. Empirically, we show that UVU achieves equal performance to large ensembles on challenging multi-task offline RL settings, while offering simplicity and substantial computational savings.
How Ensembles of Distilled Policies Improve Generalisation in Reinforcement Learning
May 22, 2025



In the zero-shot policy transfer setting in reinforcement learning, the goal is to train an agent on a fixed set of training environments so that it can generalise to similar, but unseen, testing environments. Previous work has shown that policy distillation after training can sometimes produce a policy that outperforms the original in the testing environments. However, it is not yet entirely clear why that is, or what data should be used to distil the policy. In this paper, we prove, under certain assumptions, a generalisation bound for policy distillation after training. The theory provides two practical insights: for improved generalisation, you should 1) train an ensemble of distilled policies, and 2) distil it on as much data from the training environments as possible. We empirically verify that these insights hold in more general settings, when the assumptions required for the theory no longer hold. Finally, we demonstrate that an ensemble of policies distilled on a diverse dataset can generalise significantly better than the original agent.
Training on more Reachable Tasks for Generalisation in Reinforcement Learning
Oct 04, 2024



In multi-task reinforcement learning, agents train on a fixed set of tasks and have to generalise to new ones. Recent work has shown that increased exploration improves this generalisation, but it remains unclear why exactly that is. In this paper, we introduce the concept of reachability in multi-task reinforcement learning and show that an initial exploration phase increases the number of reachable tasks the agent is trained on. This, and not the increased exploration, is responsible for the improved generalisation, even to unreachable tasks. Inspired by this, we propose a novel method Explore-Go that implements such an exploration phase at the beginning of each episode. Explore-Go only modifies the way experience is collected and can be used with most existing on-policy or off-policy reinforcement learning algorithms. We demonstrate the effectiveness of our method when combined with some popular algorithms and show an increase in generalisation performance across several environments.
Explore-Go: Leveraging Exploration for Generalisation in Deep Reinforcement Learning
Jun 12, 2024



One of the remaining challenges in reinforcement learning is to develop agents that can generalise to novel scenarios they might encounter once deployed. This challenge is often framed in a multi-task setting where agents train on a fixed set of tasks and have to generalise to new tasks. Recent work has shown that in this setting increased exploration during training can be leveraged to increase the generalisation performance of the agent. This makes sense when the states encountered during testing can actually be explored during training. In this paper, we provide intuition why exploration can also benefit generalisation to states that cannot be explicitly encountered during training. Additionally, we propose a novel method Explore-Go that exploits this intuition by increasing the number of states on which the agent trains. Explore-Go effectively increases the starting state distribution of the agent and as a result can be used in conjunction with most existing on-policy or off-policy reinforcement learning algorithms. We show empirically that our method can increase generalisation performance in an illustrative environment and on the Procgen benchmark.
The Role of Diverse Replay for Generalisation in Reinforcement Learning
Jun 09, 2023In reinforcement learning (RL), key components of many algorithms are the exploration strategy and replay buffer. These strategies regulate what environment data is collected and trained on and have been extensively studied in the RL literature. In this paper, we investigate the impact of these components in the context of generalisation in multi-task RL. We investigate the hypothesis that collecting and training on more diverse data from the training environment will improve zero-shot generalisation to new environments/tasks. We motivate mathematically and show empirically that generalisation to states that are "reachable" during training is improved by increasing the diversity of transitions in the replay buffer. Furthermore, we show empirically that this same strategy also shows improvement for generalisation to similar but "unreachable" states and could be due to improved generalisation of latent representations.