 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle over Substance: Distilled Language Models Reason Via Stylistic Replication
Apr 02, 2025Specialized reasoning language models (RLMs) have demonstrated that scaling test-time computation through detailed reasoning traces significantly enhances performance. Although these traces effectively facilitate knowledge distillation into smaller, instruction-tuned models, the precise nature of transferred reasoning remains unclear. In this study, we investigate to what extent distilled models internalize replicated stylistic patterns during reasoning. To this end, we systematically analyze reasoning traces, identifying structural and lexical patterns that characterize successful reasoning. We then introduce two new datasets -- a dataset of emergent reasoning traces and a synthetic dataset explicitly constructed to replicate these stylistic patterns -- to precisely examine their influence on distilled models' reasoning capabilities. We find that models trained on the synthetic traces achieve comparable performance, indicating that distilled reasoning abilities rely significantly on surface-level patterns. Surprisingly, we observe an increase in performance even when the synthetic traces are altered to lead to the wrong answer. Our findings highlight how stylistic patterns can be leveraged to efficiently enhance LM reasoning across diverse model families.
Positive Experience Reflection for Agents in Interactive Text Environments
Nov 04, 2024



Intelligent agents designed for interactive environments face significant challenges in text-based games, a domain that demands complex reasoning and adaptability. While agents based on large language models (LLMs) using self-reflection have shown promise, they struggle when initially successful and exhibit reduced effectiveness when using smaller LLMs. We introduce Sweet&Sour, a novel approach that addresses these limitations in existing reflection methods by incorporating positive experiences and managed memory to enrich the context available to the agent at decision time. Our comprehensive analysis spans both closed- and open-source LLMs and demonstrates the effectiveness of Sweet&Sour in improving agent performance, particularly in scenarios where previous approaches fall short.
Context-Informed Machine Translation of Manga using Multimodal Large Language Models
Nov 04, 2024



Due to the significant time and effort required for handcrafting translations, most manga never leave the domestic Japanese market. Automatic manga translation is a promising potential solution. However, it is a budding and underdeveloped field and presents complexities even greater than those found in standard translation due to the need to effectively incorporate visual elements into the translation process to resolve ambiguities. In this work, we investigate to what extent multimodal large language models (LLMs) can provide effective manga translation, thereby assisting manga authors and publishers in reaching wider audiences. Specifically, we propose a methodology that leverages the vision component of multimodal LLMs to improve translation quality and evaluate the impact of translation unit size, context length, and propose a token efficient approach for manga translation. Moreover, we introduce a new evaluation dataset -- the first parallel Japanese-Polish manga translation dataset -- as part of a benchmark to be used in future research. Finally, we contribute an open-source software suite, enabling others to benchmark LLMs for manga translation. Our findings demonstrate that our proposed methods achieve state-of-the-art results for Japanese-English translation and set a new standard for Japanese-Polish.
Exploring LLMs as a Source of Targeted Synthetic Textual Data to Minimize High Confidence Misclassifications
Apr 02, 2024



Natural Language Processing (NLP) models optimized for predictive performance often make high confidence errors and suffer from vulnerability to adversarial and out-of-distribution data. Existing work has mainly focused on mitigation of such errors using either humans or an automated approach. In this study, we explore the usage of large language models (LLMs) for data augmentation as a potential solution to the issue of NLP models making wrong predictions with high confidence during classification tasks. We compare the effectiveness of synthetic data generated by LLMs with that of human data obtained via the same procedure. For mitigation, humans or LLMs provide natural language characterizations of high confidence misclassifications to generate synthetic data, which are then used to extend the training set. We conduct an extensive evaluation of our approach on three classification tasks and demonstrate its effectiveness in reducing the number of high confidence misclassifications present in the model, all while maintaining the same level of accuracy. Moreover, we find that the cost gap between humans and LLMs surpasses an order of magnitude, as LLMs attain human-like performance while being more scalable.
Red Teaming for Large Language Models At Scale: Tackling Hallucinations on Mathematics Tasks
Dec 30, 2023We consider the problem of red teaming LLMs on elementary calculations and algebraic tasks to evaluate how various prompting techniques affect the quality of outputs. We present a framework to procedurally generate numerical questions and puzzles, and compare the results with and without the application of several red teaming techniques. Our findings suggest that even though structured reasoning and providing worked-out examples slow down the deterioration of the quality of answers, the gpt-3.5-turbo and gpt-4 models are not well suited for elementary calculations and reasoning tasks, also when being red teamed.
A.I. Robustness: a Human-Centered Perspective on Technological Challenges and Opportunities
Oct 19, 2022
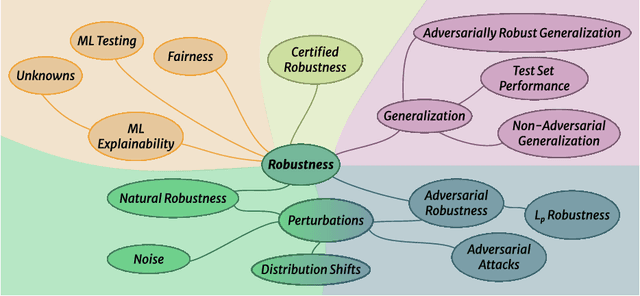
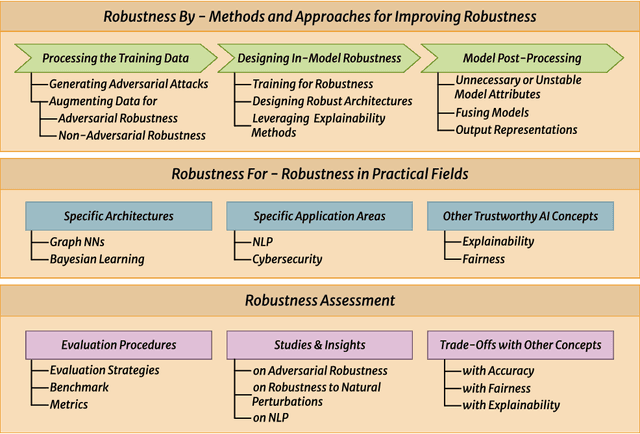
Despite the impressive performance of Artificial Intelligence (AI) systems, their robustness remains elusive and constitutes a key issue that impedes large-scale adoption. Robustness has been studied in many domains of AI, yet with different interpretations across domains and contexts. In this work, we systematically survey the recent progress to provide a reconciled terminology of concepts around AI robustness. We introduce three taxonomies to organize and describe the literature both from a fundamental and applied point of view: 1) robustness by methods and approaches in different phases of the machine learning pipeline; 2) robustness for specific model architectures, tasks, and systems; and in addition, 3) robustness assessment methodologies and insights, particularly the trade-offs with other trustworthiness properties. Finally, we identify and discuss research gaps and opportunities and give an outlook on the field. We highlight the central role of humans in evaluating and enhancing AI robustness, considering the necessary knowledge humans can provide, and discuss the need for better understanding practices and developing supportive tools in the future.