 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaExploitem: Going Beyond the Nash Equilibrium in Poker by Learning to Exploit Suboptimal Play
May 09, 2026Poker is an imperfect information game that has served as a long-standing benchmark for decision-making under uncertainty. To maximize utility beyond the Nash equilibrium, an agent can deviate from Nash-equilibrium policies to exploit suboptimal play. We introduce AlphaExploitem, which extends the competitive RL poker agent AlphaHoldem by using a hierarchical transformer encoder that enables reasoning over previously played hands and modifying the training procedure with the inclusion of a diverse pool of exploitable opponents to facilitate learning to exploit. We train and evaluate AlphaExploitem on two standard benchmarks for imperfect-information games. Empirically, AlphaExploitem successfully exploits weak play by both in- and out-of-distribution opponents, without losing performance against NE opponents.
Parallelizing Tree Search with Twice Sequential Monte Carlo
Nov 18, 2025Model-based reinforcement learning (RL) methods that leverage search are responsible for many milestone breakthroughs in RL. Sequential Monte Carlo (SMC) recently emerged as an alternative to the Monte Carlo Tree Search (MCTS) algorithm which drove these breakthroughs. SMC is easier to parallelize and more suitable to GPU acceleration. However, it also suffers from large variance and path degeneracy which prevent it from scaling well with increased search depth, i.e., increased sequential compute. To address these problems, we introduce Twice Sequential Monte Carlo Tree Search (TSMCTS). Across discrete and continuous environments TSMCTS outperforms the SMC baseline as well as a popular modern version of MCTS. Through variance reduction and mitigation of path degeneracy, TSMCTS scales favorably with sequential compute while retaining the properties that make SMC natural to parallelize.
Bridging the Performance Gap Between Target-Free and Target-Based Reinforcement Learning With Iterated Q-Learning
Jun 04, 2025In value-based reinforcement learning, removing the target network is tempting as the boostrapped target would be built from up-to-date estimates, and the spared memory occupied by the target network could be reallocated to expand the capacity of the online network. However, eliminating the target network introduces instability, leading to a decline in performance. Removing the target network also means we cannot leverage the literature developed around target networks. In this work, we propose to use a copy of the last linear layer of the online network as a target network, while sharing the remaining parameters with the up-to-date online network, hence stepping out of the binary choice between target-based and target-free methods. It enables us to leverage the concept of iterated Q-learning, which consists of learning consecutive Bellman iterations in parallel, to reduce the performance gap between target-free and target-based approaches. Our findings demonstrate that this novel method, termed iterated Shared Q-Learning (iS-QL), improves the sample efficiency of target-free approaches across various settings. Importantly, iS-QL requires a smaller memory footprint and comparable training time to classical target-based algorithms, highlighting its potential to scale reinforcement learning research.
Universal Value-Function Uncertainties
May 27, 2025


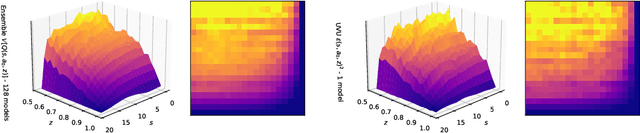
Estimating epistemic uncertainty in value functions is a crucial challenge for many aspects of reinforcement learning (RL), including efficient exploration, safe decision-making, and offline RL. While deep ensembles provide a robust method for quantifying value uncertainty, they come with significant computational overhead. Single-model methods, while computationally favorable, often rely on heuristics and typically require additional propagation mechanisms for myopic uncertainty estimates. In this work we introduce universal value-function uncertainties (UVU), which, similar in spirit to random network distillation (RND), quantify uncertainty as squared prediction errors between an online learner and a fixed, randomly initialized target network. Unlike RND, UVU errors reflect policy-conditional value uncertainty, incorporating the future uncertainties any given policy may encounter. This is due to the training procedure employed in UVU: the online network is trained using temporal difference learning with a synthetic reward derived from the fixed, randomly initialized target network. We provide an extensive theoretical analysis of our approach using neural tangent kernel (NTK) theory and show that in the limit of infinite network width, UVU errors are exactly equivalent to the variance of an ensemble of independent universal value functions. Empirically, we show that UVU achieves equal performance to large ensembles on challenging multi-task offline RL settings, while offering simplicity and substantial computational savings.
Trust-Region Twisted Policy Improvement
Apr 08, 2025
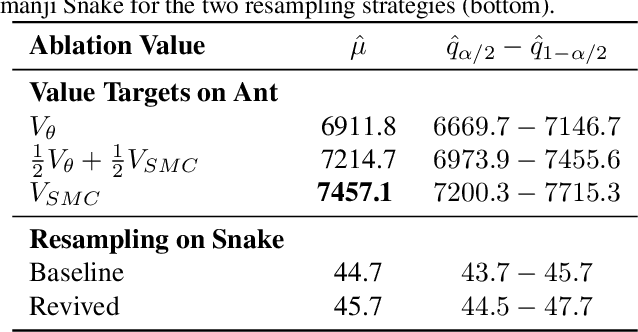


Monte-Carlo tree search (MCTS) has driven many recent breakthroughs in deep reinforcement learning (RL). However, scaling MCTS to parallel compute has proven challenging in practice which has motivated alternative planners like sequential Monte-Carlo (SMC). Many of these SMC methods adopt particle filters for smoothing through a reformulation of RL as a policy inference problem. Yet, persisting design choices of these particle filters often conflict with the aim of online planning in RL, which is to obtain a policy improvement at the start of planning. Drawing inspiration from MCTS, we tailor SMC planners specifically for RL by improving data generation within the planner through constrained action sampling and explicit terminal state handling, as well as improving policy and value target estimation. This leads to our Trust-Region Twisted SMC (TRT-SMC), which shows improved runtime and sample-efficiency over baseline MCTS and SMC methods in both discrete and continuous domains.
Value Improved Actor Critic Algorithms
Jun 03, 2024Many modern reinforcement learning algorithms build on the actor-critic (AC) framework: iterative improvement of a policy (the actor) using policy improvement operators and iterative approximation of the policy's value (the critic). In contrast, the popular value-based algorithm family employs improvement operators in the value update, to iteratively improve the value function directly. In this work, we propose a general extension to the AC framework that employs two separate improvement operators: one applied to the policy in the spirit of policy-based algorithms and one applied to the value in the spirit of value-based algorithms, which we dub Value-Improved AC (VI-AC). We design two practical VI-AC algorithms based in the popular online off-policy AC algorithms TD3 and DDPG. We evaluate VI-TD3 and VI-DDPG in the Mujoco benchmark and find that both improve upon or match the performance of their respective baselines in all environments tested.