 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKL-Entropy-Regularized RL with a Generative Model is Minimax Optimal
May 27, 2022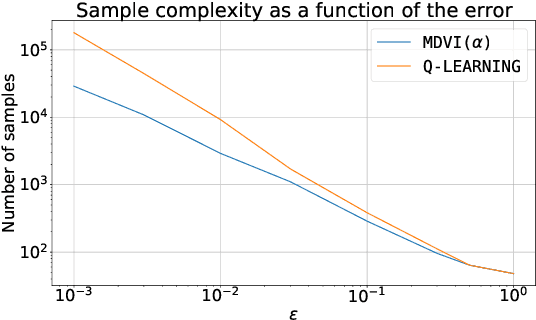

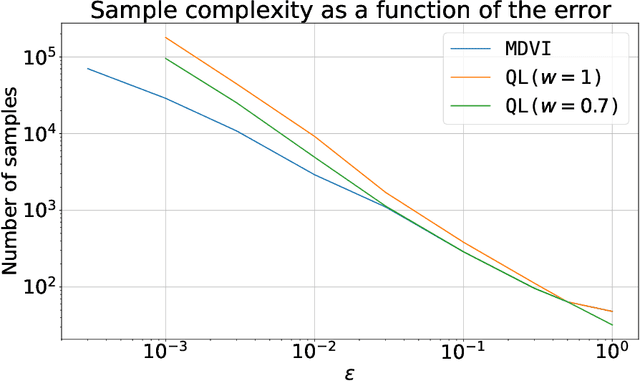
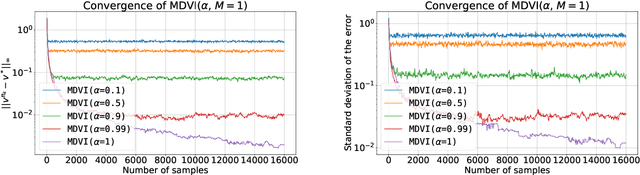
In this work, we consider and analyze the sample complexity of model-free reinforcement learning with a generative model. Particularly, we analyze mirror descent value iteration (MDVI) by Geist et al. (2019) and Vieillard et al. (2020a), which uses the Kullback-Leibler divergence and entropy regularization in its value and policy updates. Our analysis shows that it is nearly minimax-optimal for finding an $\varepsilon$-optimal policy when $\varepsilon$ is sufficiently small. This is the first theoretical result that demonstrates that a simple model-free algorithm without variance-reduction can be nearly minimax-optimal under the considered setting.
Learning Mean Field Games: A Survey
May 25, 2022
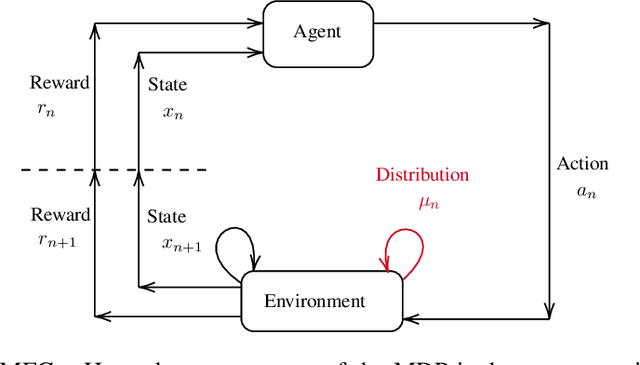
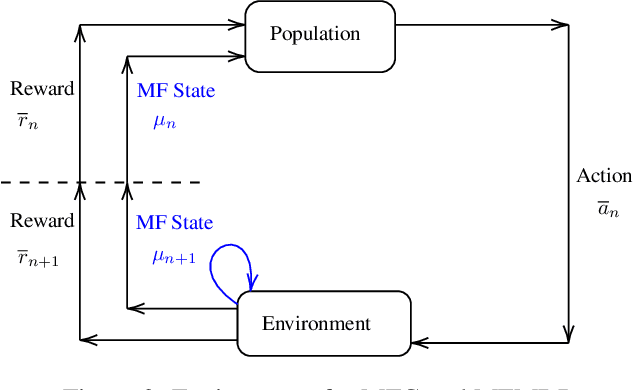
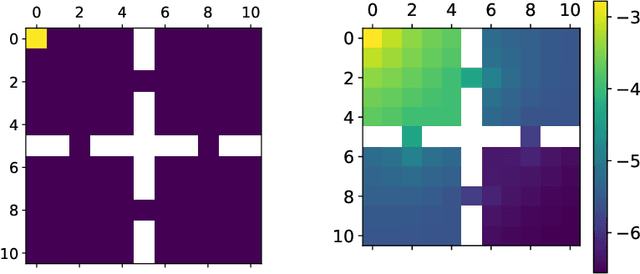
Non-cooperative and cooperative games with a very large number of players have many applications but remain generally intractable when the number of players increases. Introduced by Lasry and Lions, and Huang, Caines and Malham\'e, Mean Field Games (MFGs) rely on a mean-field approximation to allow the number of players to grow to infinity. Traditional methods for solving these games generally rely on solving partial or stochastic differential equations with a full knowledge of the model. Recently, Reinforcement Learning (RL) has appeared promising to solve complex problems. By combining MFGs and RL, we hope to solve games at a very large scale both in terms of population size and environment complexity. In this survey, we review the quickly growing recent literature on RL methods to learn Nash equilibria in MFGs. We first identify the most common settings (static, stationary, and evolutive). We then present a general framework for classical iterative methods (based on best-response computation or policy evaluation) to solve MFGs in an exact way. Building on these algorithms and the connection with Markov Decision Processes, we explain how RL can be used to learn MFG solutions in a model-free way. Last, we present numerical illustrations on a benchmark problem, and conclude with some perspectives.
Learning Energy Networks with Generalized Fenchel-Young Losses
May 19, 2022
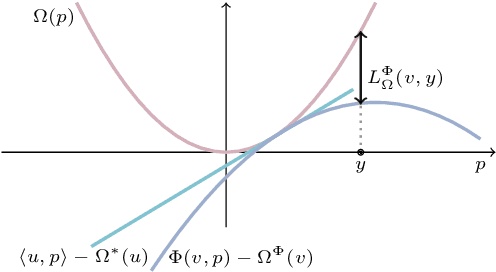
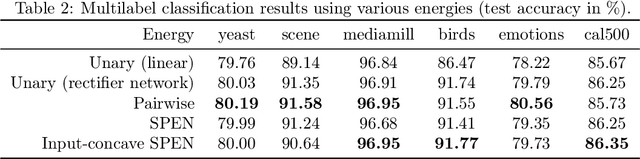
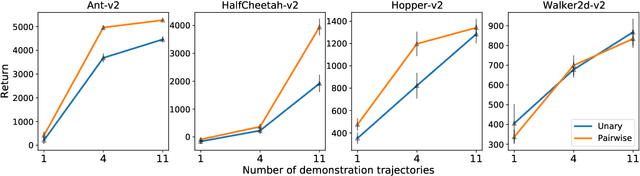
Energy-based models, a.k.a. energy networks, perform inference by optimizing an energy function, typically parametrized by a neural network. This allows one to capture potentially complex relationships between inputs and outputs. To learn the parameters of the energy function, the solution to that optimization problem is typically fed into a loss function. The key challenge for training energy networks lies in computing loss gradients, as this typically requires argmin/argmax differentiation. In this paper, building upon a generalized notion of conjugate function, which replaces the usual bilinear pairing with a general energy function, we propose generalized Fenchel-Young losses, a natural loss construction for learning energy networks. Our losses enjoy many desirable properties and their gradients can be computed efficiently without argmin/argmax differentiation. We also prove the calibration of their excess risk in the case of linear-concave energies. We demonstrate our losses on multilabel classification and imitation learning tasks.
Scalable Deep Reinforcement Learning Algorithms for Mean Field Games
Mar 22, 2022



Mean Field Games (MFGs) have been introduced to efficiently approximate games with very large populations of strategic agents. Recently, the question of learning equilibria in MFGs has gained momentum, particularly using model-free reinforcement learning (RL) methods. One limiting factor to further scale up using RL is that existing algorithms to solve MFGs require the mixing of approximated quantities such as strategies or $q$-values. This is non-trivial in the case of non-linear function approximation that enjoy good generalization properties, e.g. neural networks. We propose two methods to address this shortcoming. The first one learns a mixed strategy from distillation of historical data into a neural network and is applied to the Fictitious Play algorithm. The second one is an online mixing method based on regularization that does not require memorizing historical data or previous estimates. It is used to extend Online Mirror Descent. We demonstrate numerically that these methods efficiently enable the use of Deep RL algorithms to solve various MFGs. In addition, we show that these methods outperform SotA baselines from the literature.
Lazy-MDPs: Towards Interpretable Reinforcement Learning by Learning When to Act
Mar 16, 2022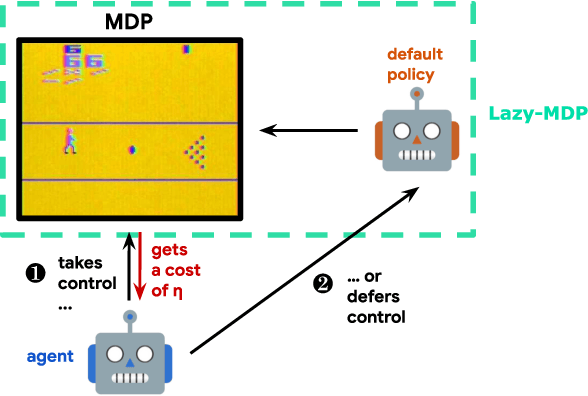
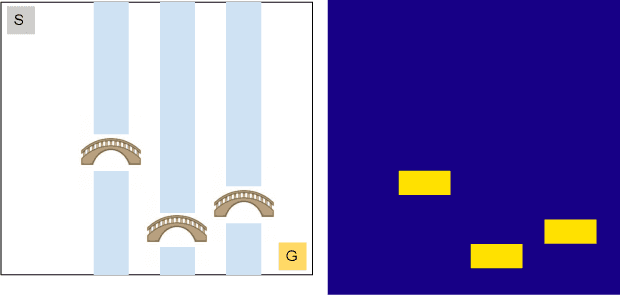
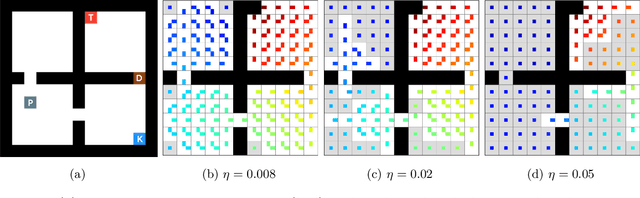
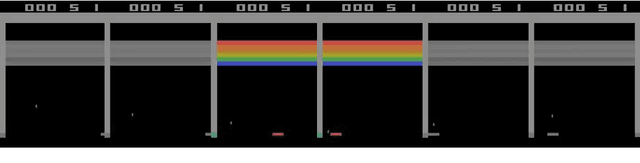
Traditionally, Reinforcement Learning (RL) aims at deciding how to act optimally for an artificial agent. We argue that deciding when to act is equally important. As humans, we drift from default, instinctive or memorized behaviors to focused, thought-out behaviors when required by the situation. To enhance RL agents with this aptitude, we propose to augment the standard Markov Decision Process and make a new mode of action available: being lazy, which defers decision-making to a default policy. In addition, we penalize non-lazy actions in order to encourage minimal effort and have agents focus on critical decisions only. We name the resulting formalism lazy-MDPs. We study the theoretical properties of lazy-MDPs, expressing value functions and characterizing optimal solutions. Then we empirically demonstrate that policies learned in lazy-MDPs generally come with a form of interpretability: by construction, they show us the states where the agent takes control over the default policy. We deem those states and corresponding actions important since they explain the difference in performance between the default and the new, lazy policy. With suboptimal policies as default (pretrained or random), we observe that agents are able to get competitive performance in Atari games while only taking control in a limited subset of states.
* AAMAS 2022 (14 pages extended version, added Sec. 7.4 and appendix K)
Continuous Control with Action Quantization from Demonstrations
Oct 19, 2021

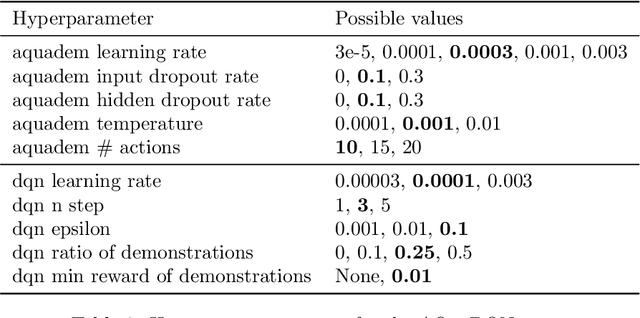
In Reinforcement Learning (RL), discrete actions, as opposed to continuous actions, result in less complex exploration problems and the immediate computation of the maximum of the action-value function which is central to dynamic programming-based methods. In this paper, we propose a novel method: Action Quantization from Demonstrations (AQuaDem) to learn a discretization of continuous action spaces by leveraging the priors of demonstrations. This dramatically reduces the exploration problem, since the actions faced by the agent not only are in a finite number but also are plausible in light of the demonstrator's behavior. By discretizing the action space we can apply any discrete action deep RL algorithm to the continuous control problem. We evaluate the proposed method on three different setups: RL with demonstrations, RL with play data --demonstrations of a human playing in an environment but not solving any specific task-- and Imitation Learning. For all three setups, we only consider human data, which is more challenging than synthetic data. We found that AQuaDem consistently outperforms state-of-the-art continuous control methods, both in terms of performance and sample efficiency. We provide visualizations and videos in the paper's website: https://google-research.github.io/aquadem.
Twice regularized MDPs and the equivalence between robustness and regularization
Oct 12, 2021
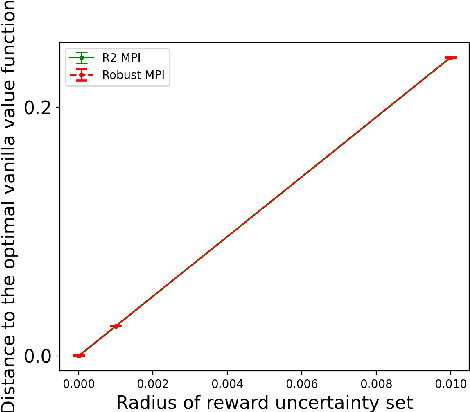
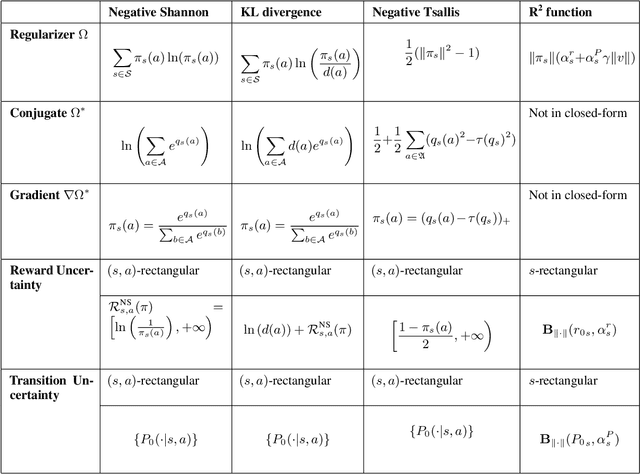
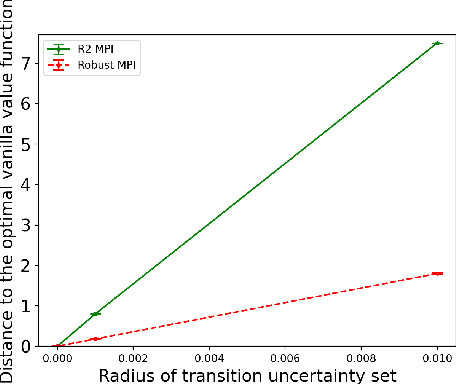
Robust Markov decision processes (MDPs) aim to handle changing or partially known system dynamics. To solve them, one typically resorts to robust optimization methods. However, this significantly increases computational complexity and limits scalability in both learning and planning. On the other hand, regularized MDPs show more stability in policy learning without impairing time complexity. Yet, they generally do not encompass uncertainty in the model dynamics. In this work, we aim to learn robust MDPs using regularization. We first show that regularized MDPs are a particular instance of robust MDPs with uncertain reward. We thus establish that policy iteration on reward-robust MDPs can have the same time complexity as on regularized MDPs. We further extend this relationship to MDPs with uncertain transitions: this leads to a regularization term with an additional dependence on the value function. We finally generalize regularized MDPs to twice regularized MDPs (R${}^2$ MDPs), i.e., MDPs with $\textit{both}$ value and policy regularization. The corresponding Bellman operators enable developing policy iteration schemes with convergence and robustness guarantees. It also reduces planning and learning in robust MDPs to regularized MDPs.
Large Batch Experience Replay
Oct 04, 2021
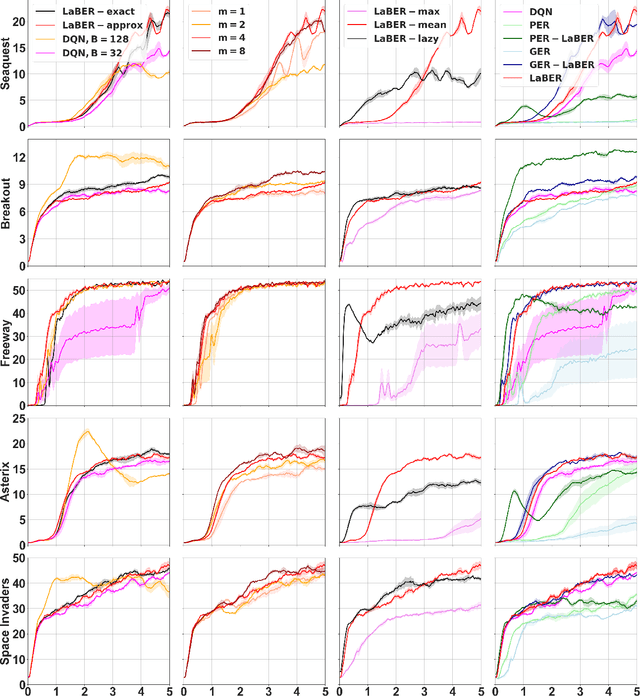
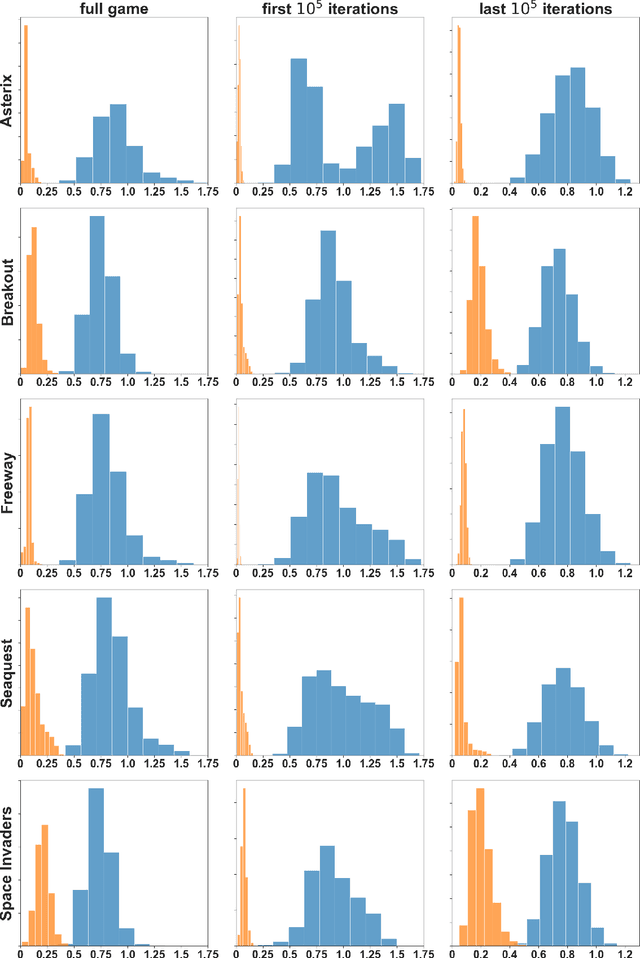

Several algorithms have been proposed to sample non-uniformly the replay buffer of deep Reinforcement Learning (RL) agents to speed-up learning, but very few theoretical foundations of these sampling schemes have been provided. Among others, Prioritized Experience Replay appears as a hyperparameter sensitive heuristic, even though it can provide good performance. In this work, we cast the replay buffer sampling problem as an importance sampling one for estimating the gradient. This allows deriving the theoretically optimal sampling distribution, yielding the best theoretical convergence speed. Elaborating on the knowledge of the ideal sampling scheme, we exhibit new theoretical foundations of Prioritized Experience Replay. The optimal sampling distribution being intractable, we make several approximations providing good results in practice and introduce, among others, LaBER (Large Batch Experience Replay), an easy-to-code and efficient method for sampling the replay buffer. LaBER, which can be combined with Deep Q-Networks, distributional RL agents or actor-critic methods, yields improved performance over a diverse range of Atari games and PyBullet environments, compared to the base agent it is implemented on and to other prioritization schemes.
Generalization in Mean Field Games by Learning Master Policies
Sep 20, 2021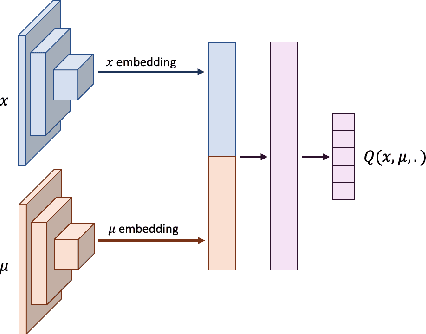
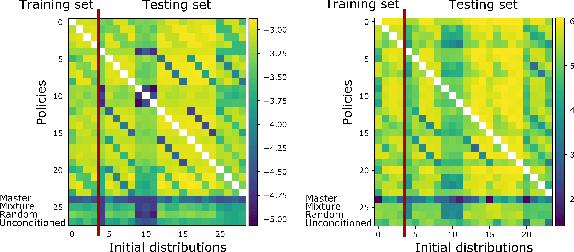

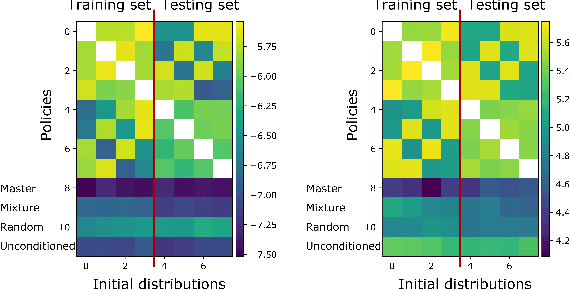
Mean Field Games (MFGs) can potentially scale multi-agent systems to extremely large populations of agents. Yet, most of the literature assumes a single initial distribution for the agents, which limits the practical applications of MFGs. Machine Learning has the potential to solve a wider diversity of MFG problems thanks to generalizations capacities. We study how to leverage these generalization properties to learn policies enabling a typical agent to behave optimally against any population distribution. In reference to the Master equation in MFGs, we coin the term ``Master policies'' to describe them and we prove that a single Master policy provides a Nash equilibrium, whatever the initial distribution. We propose a method to learn such Master policies. Our approach relies on three ingredients: adding the current population distribution as part of the observation, approximating Master policies with neural networks, and training via Reinforcement Learning and Fictitious Play. We illustrate on numerical examples not only the efficiency of the learned Master policy but also its generalization capabilities beyond the distributions used for training.
Implicitly Regularized RL with Implicit Q-Values
Aug 16, 2021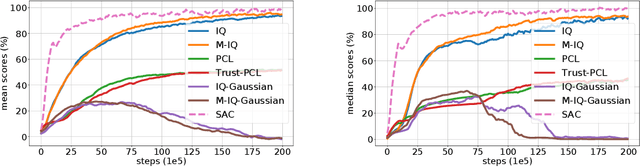
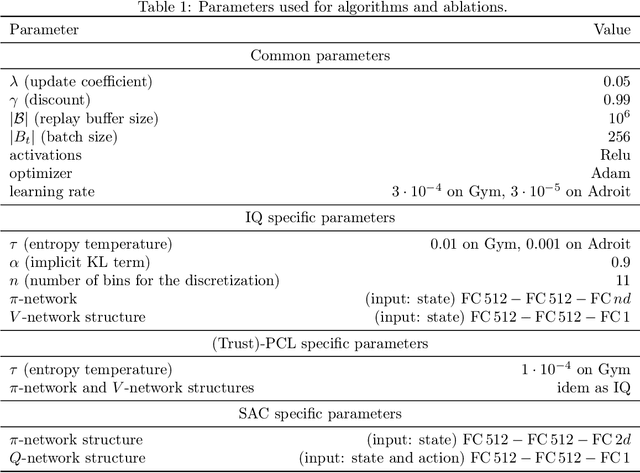
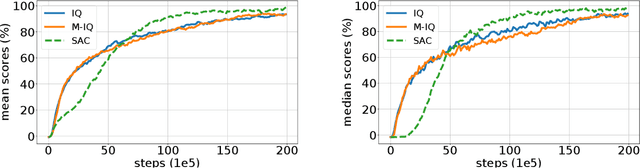

The $Q$-function is a central quantity in many Reinforcement Learning (RL) algorithms for which RL agents behave following a (soft)-greedy policy w.r.t. to $Q$. It is a powerful tool that allows action selection without a model of the environment and even without explicitly modeling the policy. Yet, this scheme can only be used in discrete action tasks, with small numbers of actions, as the softmax cannot be computed exactly otherwise. Especially the usage of function approximation, to deal with continuous action spaces in modern actor-critic architectures, intrinsically prevents the exact computation of a softmax. We propose to alleviate this issue by parametrizing the $Q$-function implicitly, as the sum of a log-policy and of a value function. We use the resulting parametrization to derive a practical off-policy deep RL algorithm, suitable for large action spaces, and that enforces the softmax relation between the policy and the $Q$-value. We provide a theoretical analysis of our algorithm: from an Approximate Dynamic Programming perspective, we show its equivalence to a regularized version of value iteration, accounting for both entropy and Kullback-Leibler regularization, and that enjoys beneficial error propagation results. We then evaluate our algorithm on classic control tasks, where its results compete with state-of-the-art methods.