 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgefastMRI+: Clinical Pathology Annotations for Knee and Brain Fully Sampled Multi-Coil MRI Data
Sep 14, 2021
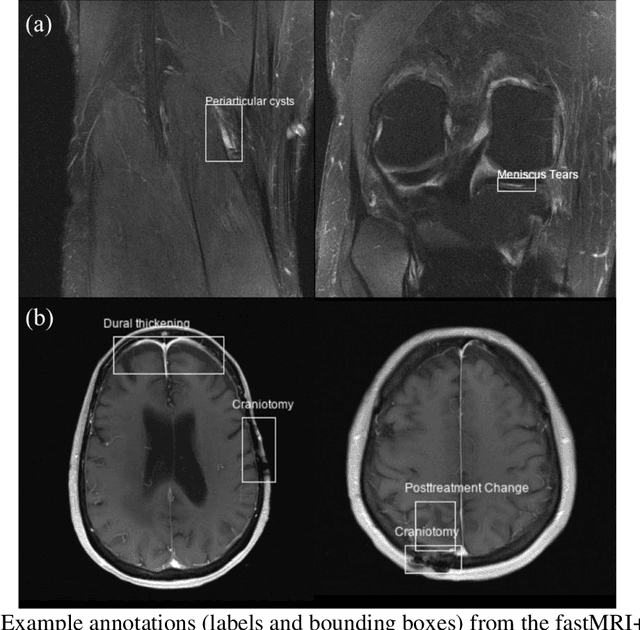
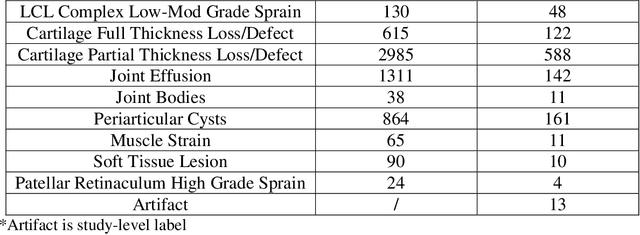
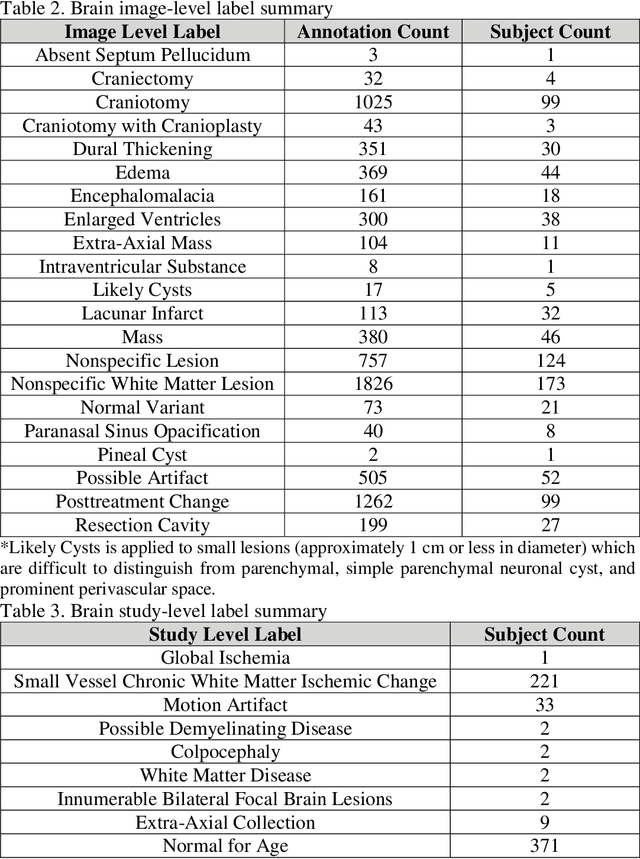
Improving speed and image quality of Magnetic Resonance Imaging (MRI) via novel reconstruction approaches remains one of the highest impact applications for deep learning in medical imaging. The fastMRI dataset, unique in that it contains large volumes of raw MRI data, has enabled significant advances in accelerating MRI using deep learning-based reconstruction methods. While the impact of the fastMRI dataset on the field of medical imaging is unquestioned, the dataset currently lacks clinical expert pathology annotations, critical to addressing clinically relevant reconstruction frameworks and exploring important questions regarding rendering of specific pathology using such novel approaches. This work introduces fastMRI+, which consists of 16154 subspecialist expert bounding box annotations and 13 study-level labels for 22 different pathology categories on the fastMRI knee dataset, and 7570 subspecialist expert bounding box annotations and 643 study-level labels for 30 different pathology categories for the fastMRI brain dataset. The fastMRI+ dataset is open access and aims to support further research and advancement of medical imaging in MRI reconstruction and beyond.
OncoPetNet: A Deep Learning based AI system for mitotic figure counting on H&E stained whole slide digital images in a large veterinary diagnostic lab setting
Aug 17, 2021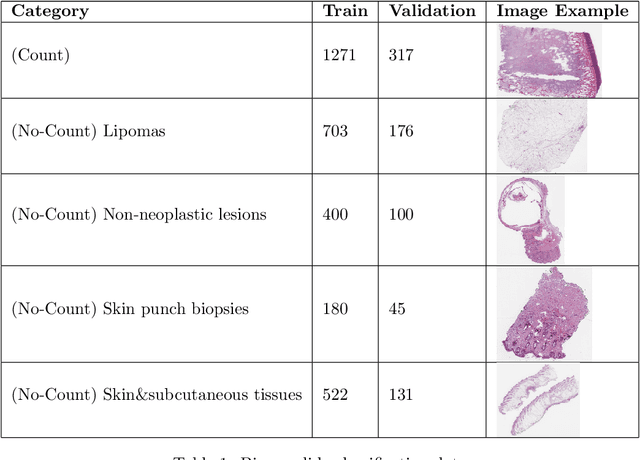


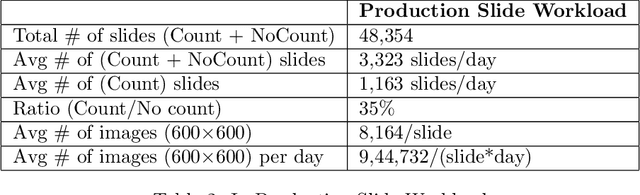
Background: Histopathology is an important modality for the diagnosis and management of many diseases in modern healthcare, and plays a critical role in cancer care. Pathology samples can be large and require multi-site sampling, leading to upwards of 20 slides for a single tumor, and the human-expert tasks of site selection and and quantitative assessment of mitotic figures are time consuming and subjective. Automating these tasks in the setting of a digital pathology service presents significant opportunities to improve workflow efficiency and augment human experts in practice. Approach: Multiple state-of-the-art deep learning techniques for histopathology image classification and mitotic figure detection were used in the development of OncoPetNet. Additionally, model-free approaches were used to increase speed and accuracy. The robust and scalable inference engine leverages Pytorch's performance optimizations as well as specifically developed speed up techniques in inference. Results: The proposed system, demonstrated significantly improved mitotic counting performance for 41 cancer cases across 14 cancer types compared to human expert baselines. In 21.9% of cases use of OncoPetNet led to change in tumor grading compared to human expert evaluation. In deployment, an effective 0.27 min/slide inference was achieved in a high throughput veterinary diagnostic pathology service across 2 centers processing 3,323 digital whole slide images daily. Conclusion: This work represents the first successful automated deployment of deep learning systems for real-time expert-level performance on important histopathology tasks at scale in a high volume clinical practice. The resulting impact outlines important considerations for model development, deployment, clinical decision making, and informs best practices for implementation of deep learning systems in digital histopathology practices.
RadGraph: Extracting Clinical Entities and Relations from Radiology Reports
Jun 28, 2021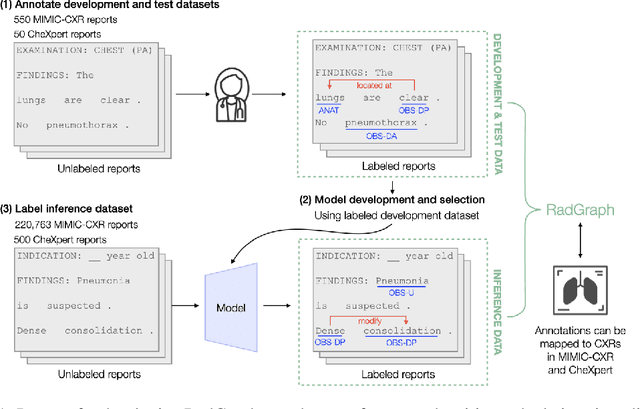
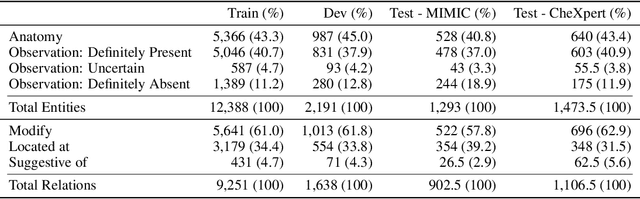
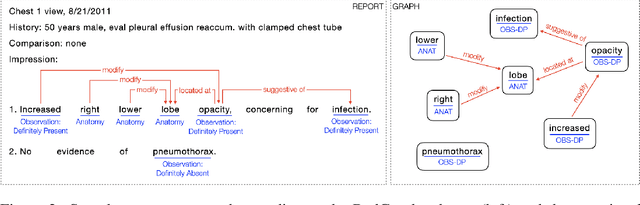
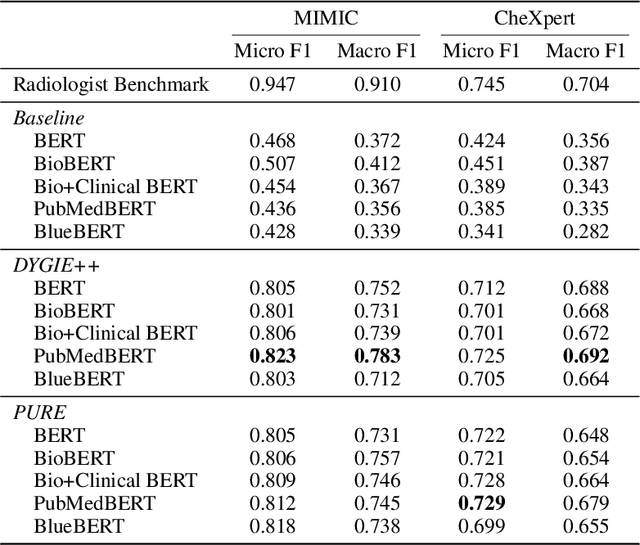
Extracting structured clinical information from free-text radiology reports can enable the use of radiology report information for a variety of critical healthcare applications. In our work, we present RadGraph, a dataset of entities and relations in full-text chest X-ray radiology reports based on a novel information extraction schema we designed to structure radiology reports. We release a development dataset, which contains board-certified radiologist annotations for 500 radiology reports from the MIMIC-CXR dataset (14,579 entities and 10,889 relations), and a test dataset, which contains two independent sets of board-certified radiologist annotations for 100 radiology reports split equally across the MIMIC-CXR and CheXpert datasets. Using these datasets, we train and test a deep learning model, RadGraph Benchmark, that achieves a micro F1 of 0.82 and 0.73 on relation extraction on the MIMIC-CXR and CheXpert test sets respectively. Additionally, we release an inference dataset, which contains annotations automatically generated by RadGraph Benchmark across 220,763 MIMIC-CXR reports (around 6 million entities and 4 million relations) and 500 CheXpert reports (13,783 entities and 9,908 relations) with mappings to associated chest radiographs. Our freely available dataset can facilitate a wide range of research in medical natural language processing, as well as computer vision and multi-modal learning when linked to chest radiographs.
High-Throughput Precision Phenotyping of Left Ventricular Hypertrophy with Cardiovascular Deep Learning
Jun 23, 2021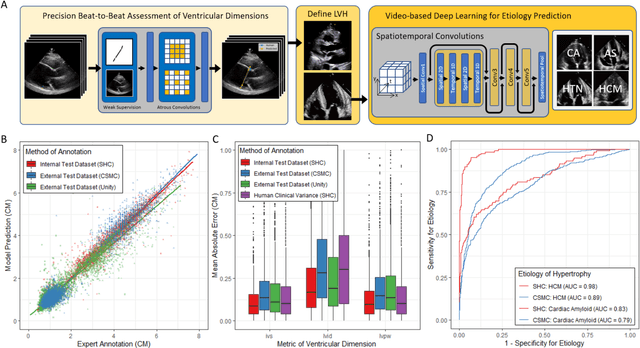
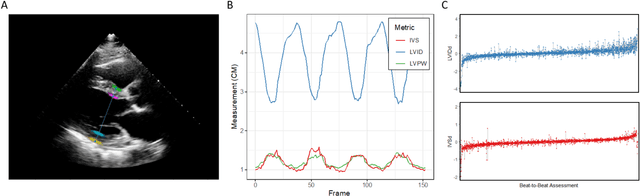
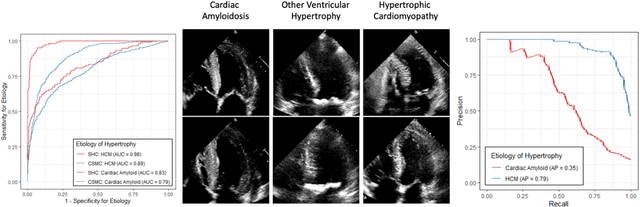
Left ventricular hypertrophy (LVH) results from chronic remodeling caused by a broad range of systemic and cardiovascular disease including hypertension, aortic stenosis, hypertrophic cardiomyopathy, and cardiac amyloidosis. Early detection and characterization of LVH can significantly impact patient care but is limited by under-recognition of hypertrophy, measurement error and variability, and difficulty differentiating etiologies of LVH. To overcome this challenge, we present EchoNet-LVH - a deep learning workflow that automatically quantifies ventricular hypertrophy with precision equal to human experts and predicts etiology of LVH. Trained on 28,201 echocardiogram videos, our model accurately measures intraventricular wall thickness (mean absolute error [MAE] 1.4mm, 95% CI 1.2-1.5mm), left ventricular diameter (MAE 2.4mm, 95% CI 2.2-2.6mm), and posterior wall thickness (MAE 1.2mm, 95% CI 1.1-1.3mm) and classifies cardiac amyloidosis (area under the curve of 0.83) and hypertrophic cardiomyopathy (AUC 0.98) from other etiologies of LVH. In external datasets from independent domestic and international healthcare systems, EchoNet-LVH accurately quantified ventricular parameters (R2 of 0.96 and 0.90 respectively) and detected cardiac amyloidosis (AUC 0.79) and hypertrophic cardiomyopathy (AUC 0.89) on the domestic external validation site. Leveraging measurements across multiple heart beats, our model can more accurately identify subtle changes in LV geometry and its causal etiologies. Compared to human experts, EchoNet-LVH is fully automated, allowing for reproducible, precise measurements, and lays the foundation for precision diagnosis of cardiac hypertrophy. As a resource to promote further innovation, we also make publicly available a large dataset of 23,212 annotated echocardiogram videos.
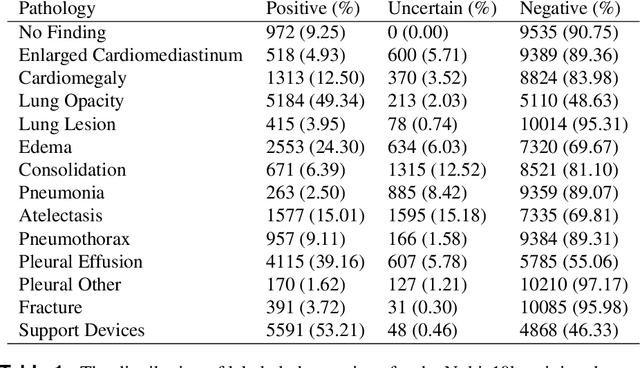
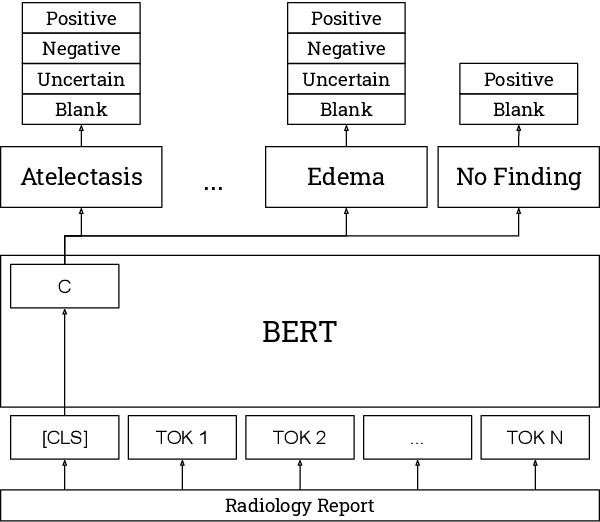
Structured dataset documentation: a datasheet for CheXpert
May 07, 2021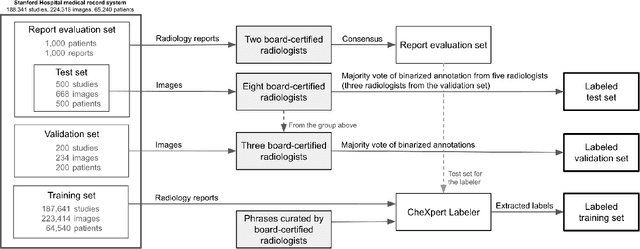
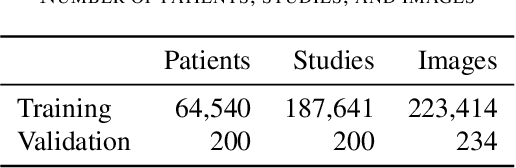
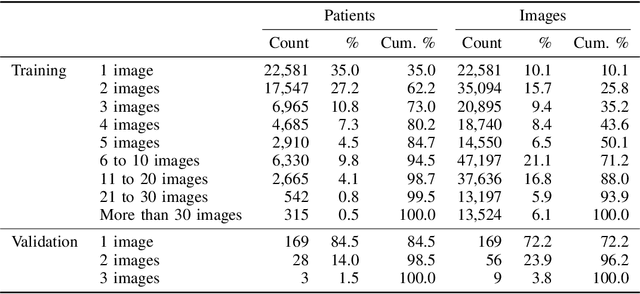

Billions of X-ray images are taken worldwide each year. Machine learning, and deep learning in particular, has shown potential to help radiologists triage and diagnose images. However, deep learning requires large datasets with reliable labels. The CheXpert dataset was created with the participation of board-certified radiologists, resulting in the strong ground truth needed to train deep learning networks. Following the structured format of Datasheets for Datasets, this paper expands on the original CheXpert paper and other sources to show the critical role played by radiologists in the creation of reliable labels and to describe the different aspects of the dataset composition in detail. Such structured documentation intends to increase the awareness in the machine learning and medical communities of the strengths, applications, and evolution of CheXpert, thereby advancing the field of medical image analysis. Another objective of this paper is to put forward this dataset datasheet as an example to the community of how to create detailed and structured descriptions of datasets. We believe that clearly documenting the creation process, the contents, and applications of datasets accelerates the creation of useful and reliable models.
VisualCheXbert: Addressing the Discrepancy Between Radiology Report Labels and Image Labels
Mar 15, 2021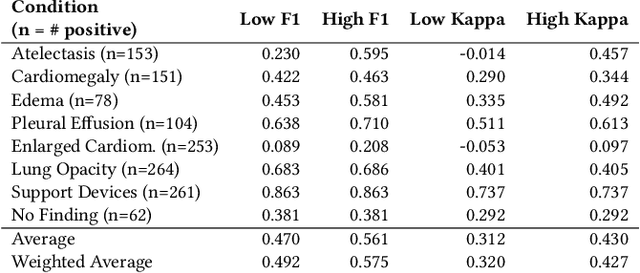
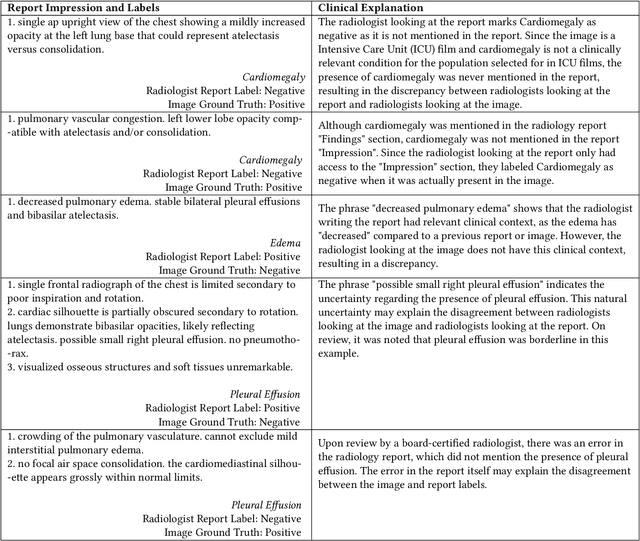
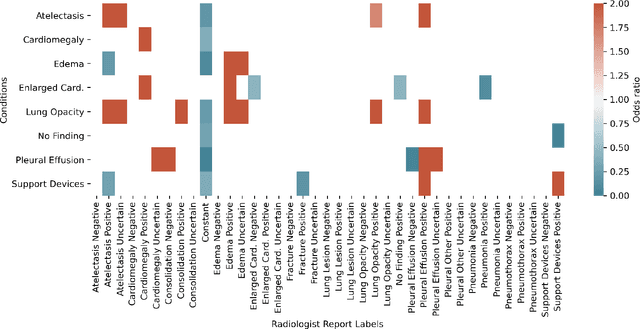
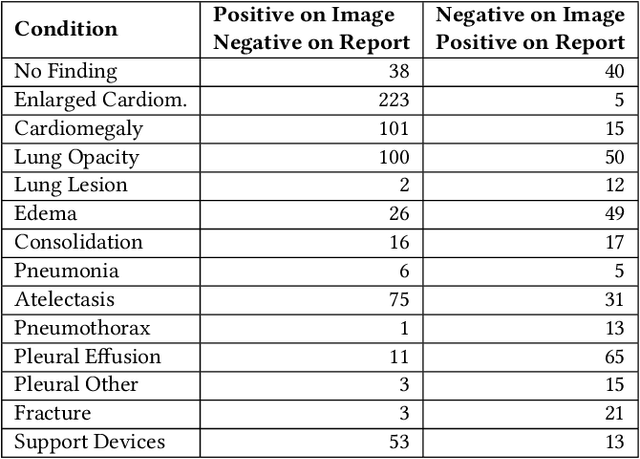
Automatic extraction of medical conditions from free-text radiology reports is critical for supervising computer vision models to interpret medical images. In this work, we show that radiologists labeling reports significantly disagree with radiologists labeling corresponding chest X-ray images, which reduces the quality of report labels as proxies for image labels. We develop and evaluate methods to produce labels from radiology reports that have better agreement with radiologists labeling images. Our best performing method, called VisualCheXbert, uses a biomedically-pretrained BERT model to directly map from a radiology report to the image labels, with a supervisory signal determined by a computer vision model trained to detect medical conditions from chest X-ray images. We find that VisualCheXbert outperforms an approach using an existing radiology report labeler by an average F1 score of 0.14 (95% CI 0.12, 0.17). We also find that VisualCheXbert better agrees with radiologists labeling chest X-ray images than do radiologists labeling the corresponding radiology reports by an average F1 score across several medical conditions of between 0.12 (95% CI 0.09, 0.15) and 0.21 (95% CI 0.18, 0.24).
CheXternal: Generalization of Deep Learning Models for Chest X-ray Interpretation to Photos of Chest X-rays and External Clinical Settings
Feb 21, 2021
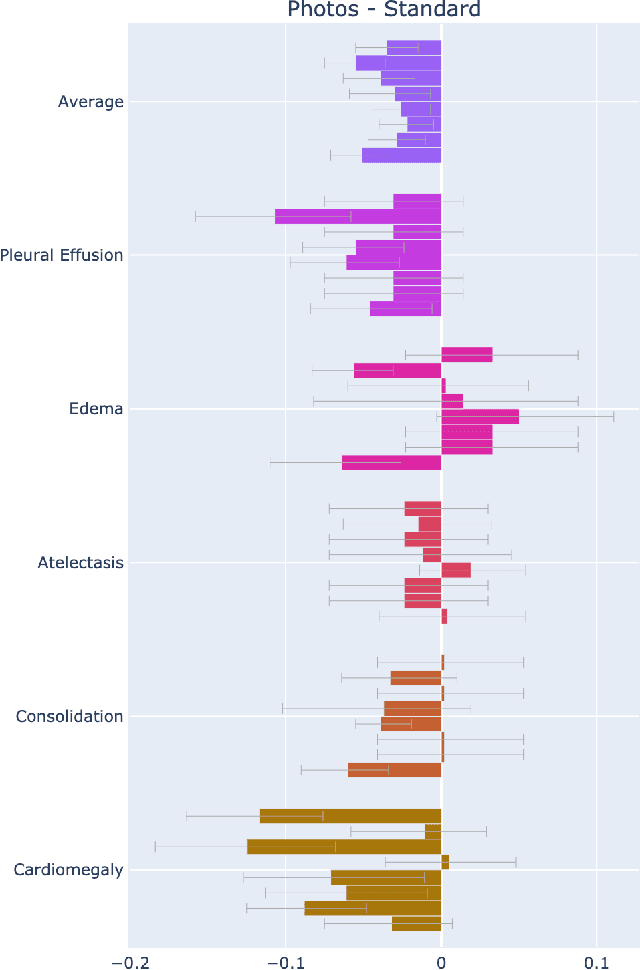

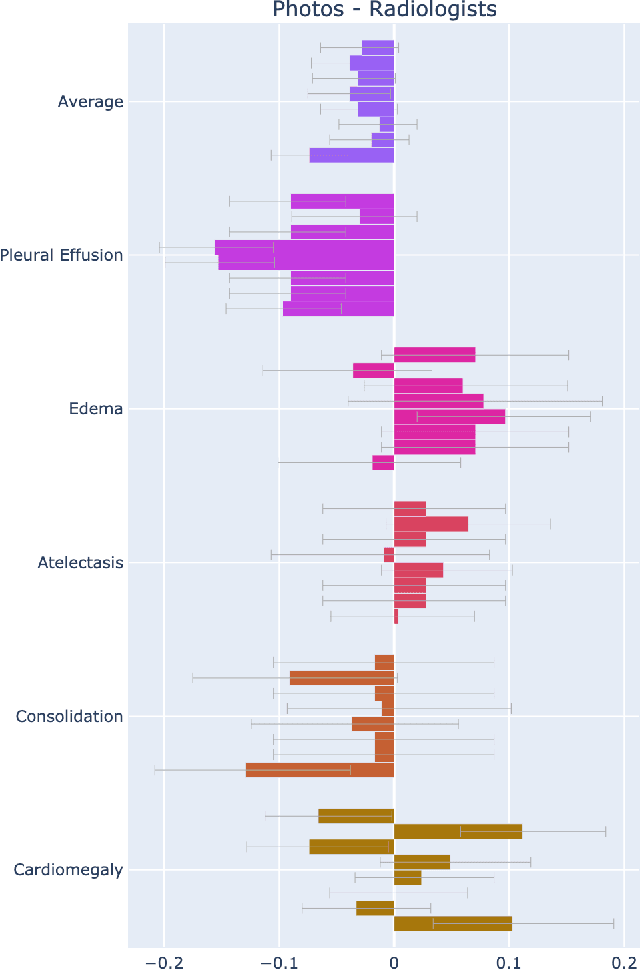
Recent advances in training deep learning models have demonstrated the potential to provide accurate chest X-ray interpretation and increase access to radiology expertise. However, poor generalization due to data distribution shifts in clinical settings is a key barrier to implementation. In this study, we measured the diagnostic performance for 8 different chest X-ray models when applied to (1) smartphone photos of chest X-rays and (2) external datasets without any finetuning. All models were developed by different groups and submitted to the CheXpert challenge, and re-applied to test datasets without further tuning. We found that (1) on photos of chest X-rays, all 8 models experienced a statistically significant drop in task performance, but only 3 performed significantly worse than radiologists on average, and (2) on the external set, none of the models performed statistically significantly worse than radiologists, and five models performed statistically significantly better than radiologists. Our results demonstrate that some chest X-ray models, under clinically relevant distribution shifts, were comparable to radiologists while other models were not. Future work should investigate aspects of model training procedures and dataset collection that influence generalization in the presence of data distribution shifts.
Gifsplanation via Latent Shift: A Simple Autoencoder Approach to Progressive Exaggeration on Chest X-rays
Feb 18, 2021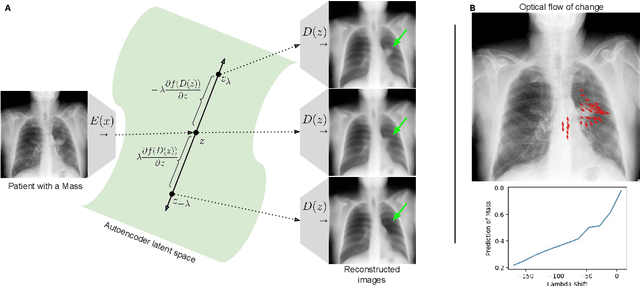
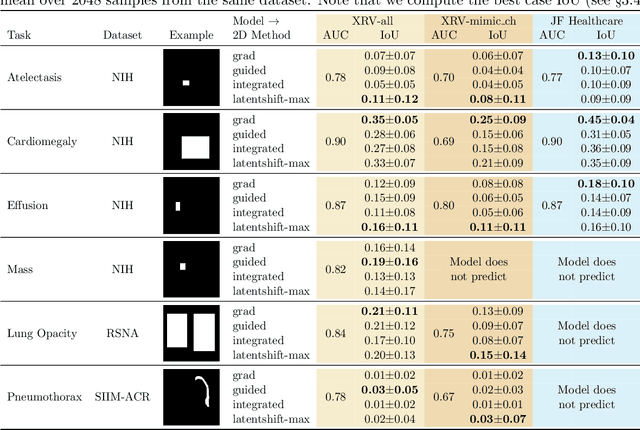
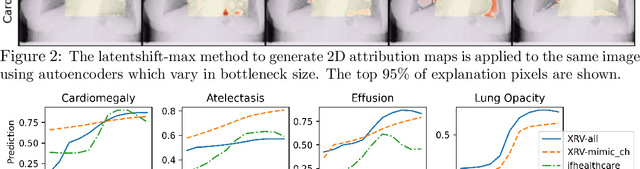

Motivation: Traditional image attribution methods struggle to satisfactorily explain predictions of neural networks. Prediction explanation is important, especially in the medical imaging, for avoiding the unintended consequences of deploying AI systems when false positive predictions can impact patient care. Thus, there is a pressing need to develop improved models for model explainability and introspection. Specific Problem: A new approach is to transform input images to increase or decrease features which cause the prediction. However, current approaches are difficult to implement as they are monolithic or rely on GANs. These hurdles prevent wide adoption. Our approach: Given an arbitrary classifier, we propose a simple autoencoder and gradient update (Latent Shift) that can transform the latent representation of an input image to exaggerate or curtail the features used for prediction. We use this method to study chest X-ray classifiers and evaluate their performance. We conduct a reader study with two radiologists assessing 240 chest X-ray predictions to identify which ones are false positives (half are) using traditional attribution maps or our proposed method. Results: We found low overlap with ground truth pathology masks for models with reasonably high accuracy. However, the results from our reader study indicate that these models are generally looking at the correct features. We also found that the Latent Shift explanation allows a user to have more confidence in true positive predictions compared to traditional approaches (0.15$\pm$0.95 in a 5 point scale with p=0.01) with only a small increase in false positive predictions (0.04$\pm$1.06 with p=0.57). Accompanying webpage: https://mlmed.org/gifsplanation Source code: https://github.com/mlmed/gifsplanation
CheXphoto: 10,000+ Smartphone Photos and Synthetic Photographic Transformations of Chest X-rays for Benchmarking Deep Learning Robustness
Jul 13, 2020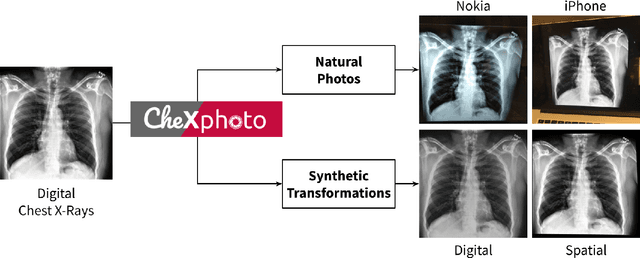
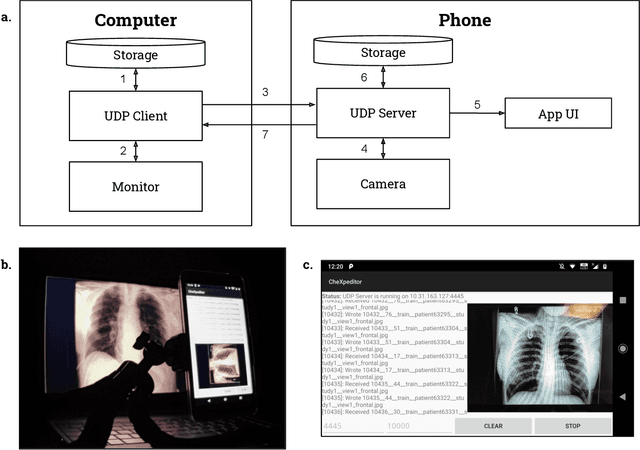
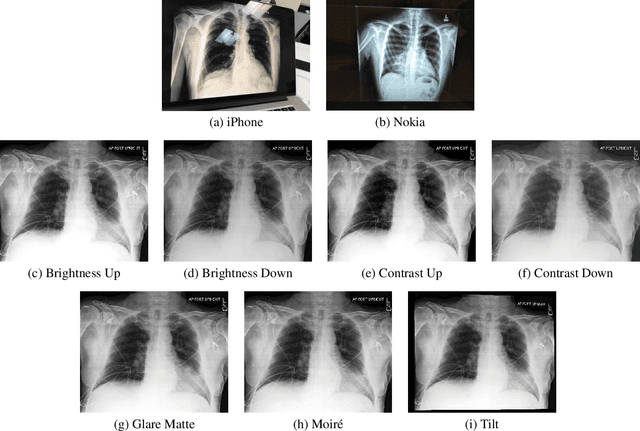
Clinical deployment of deep learning algorithms for chest x-ray interpretation requires a solution that can integrate into the vast spectrum of clinical workflows across the world. An appealing solution to scaled deployment is to leverage the existing ubiquity of smartphones: in several parts of the world, clinicians and radiologists capture photos of chest x-rays to share with other experts or clinicians via smartphone using messaging services like WhatsApp. However, the application of chest x-ray algorithms to photos of chest x-rays requires reliable classification in the presence of smartphone photo artifacts such as screen glare and poor viewing angle not typically encountered on digital x-rays used to train machine learning models. We introduce CheXphoto, a dataset of smartphone photos and synthetic photographic transformations of chest x-rays sampled from the CheXpert dataset. To generate CheXphoto we (1) automatically and manually captured photos of digital x-rays under different settings, including various lighting conditions and locations, and, (2) generated synthetic transformations of digital x-rays targeted to make them look like photos of digital x-rays and x-ray films. We release this dataset as a resource for testing and improving the robustness of deep learning algorithms for automated chest x-ray interpretation on smartphone photos of chest x-rays.
CheXbert: Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT
Apr 30, 2020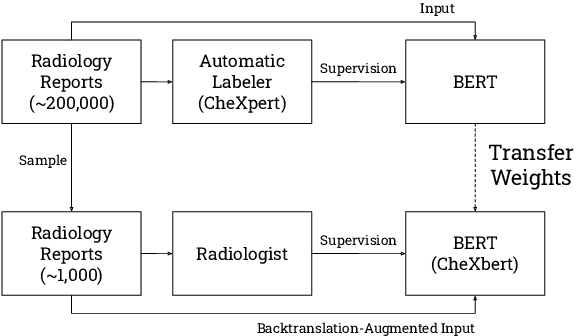
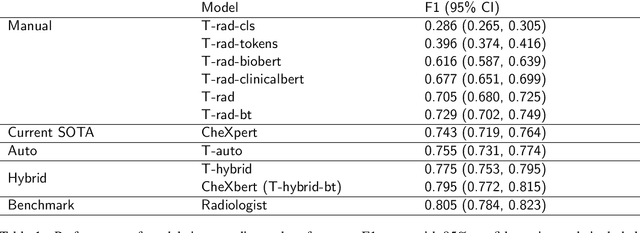
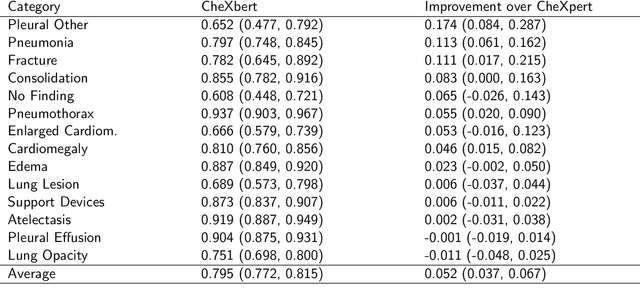
The extraction of labels from radiology text reports enables large-scale training of medical imaging models. Existing approaches to report labeling typically rely either on sophisticated feature engineering based on medical domain knowledge or manual annotations by experts. In this work, we introduce a BERT-based approach to medical image report labeling that exploits both the scale of available rule-based systems and the quality of expert annotations. We demonstrate superior performance of a biomedically pretrained BERT model first trained on annotations of a rule-based labeler and then finetuned on a small set of expert annotations augmented with automated backtranslation. We find that our final model, CheXbert, is able to outperform the previous best rules-based labeler with statistical significance, setting a new SOTA for report labeling on one of the largest datasets of chest x-rays.