 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Image De-Identification Benchmark Challenge
Jul 31, 2025



The de-identification (deID) of protected health information (PHI) and personally identifiable information (PII) is a fundamental requirement for sharing medical images, particularly through public repositories, to ensure compliance with patient privacy laws. In addition, preservation of non-PHI metadata to inform and enable downstream development of imaging artificial intelligence (AI) is an important consideration in biomedical research. The goal of MIDI-B was to provide a standardized platform for benchmarking of DICOM image deID tools based on a set of rules conformant to the HIPAA Safe Harbor regulation, the DICOM Attribute Confidentiality Profiles, and best practices in preservation of research-critical metadata, as defined by The Cancer Imaging Archive (TCIA). The challenge employed a large, diverse, multi-center, and multi-modality set of real de-identified radiology images with synthetic PHI/PII inserted. The MIDI-B Challenge consisted of three phases: training, validation, and test. Eighty individuals registered for the challenge. In the training phase, we encouraged participants to tune their algorithms using their in-house or public data. The validation and test phases utilized the DICOM images containing synthetic identifiers (of 216 and 322 subjects, respectively). Ten teams successfully completed the test phase of the challenge. To measure success of a rule-based approach to image deID, scores were computed as the percentage of correct actions from the total number of required actions. The scores ranged from 97.91% to 99.93%. Participants employed a variety of open-source and proprietary tools with customized configurations, large language models, and optical character recognition (OCR). In this paper we provide a comprehensive report on the MIDI-B Challenge's design, implementation, results, and lessons learned.
Deep Learning Discovery of Demographic Biomarkers in Echocardiography
Jul 13, 2022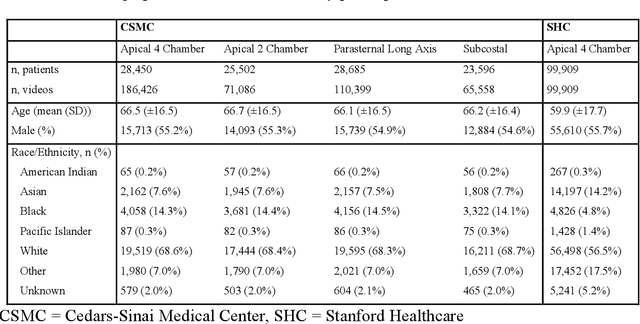
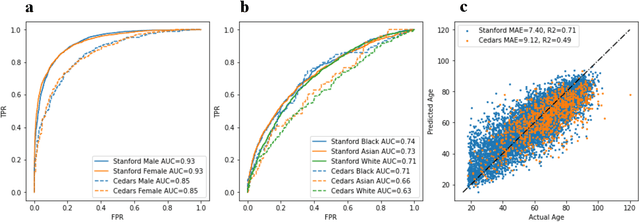
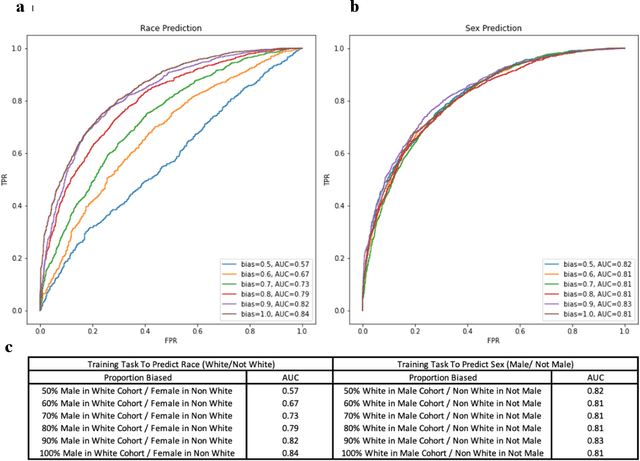
Deep learning has been shown to accurately assess 'hidden' phenotypes and predict biomarkers from medical imaging beyond traditional clinician interpretation of medical imaging. Given the black box nature of artificial intelligence (AI) models, caution should be exercised in applying models to healthcare as prediction tasks might be short-cut by differences in demographics across disease and patient populations. Using large echocardiography datasets from two healthcare systems, we test whether it is possible to predict age, race, and sex from cardiac ultrasound images using deep learning algorithms and assess the impact of varying confounding variables. We trained video-based convolutional neural networks to predict age, sex, and race. We found that deep learning models were able to identify age and sex, while unable to reliably predict race. Without considering confounding differences between categories, the AI model predicted sex with an AUC of 0.85 (95% CI 0.84 - 0.86), age with a mean absolute error of 9.12 years (95% CI 9.00 - 9.25), and race with AUCs ranging from 0.63 - 0.71. When predicting race, we show that tuning the proportion of a confounding variable (sex) in the training data significantly impacts model AUC (ranging from 0.57 to 0.84), while in training a sex prediction model, tuning a confounder (race) did not substantially change AUC (0.81 - 0.83). This suggests a significant proportion of the model's performance on predicting race could come from confounding features being detected by AI. Further work remains to identify the particular imaging features that associate with demographic information and to better understand the risks of demographic identification in medical AI as it pertains to potentially perpetuating bias and disparities.
High-Throughput Precision Phenotyping of Left Ventricular Hypertrophy with Cardiovascular Deep Learning
Jun 23, 2021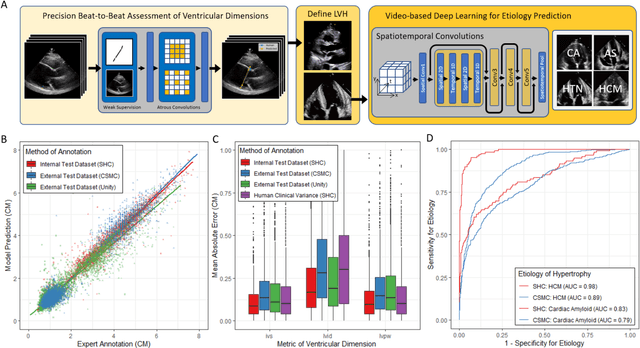
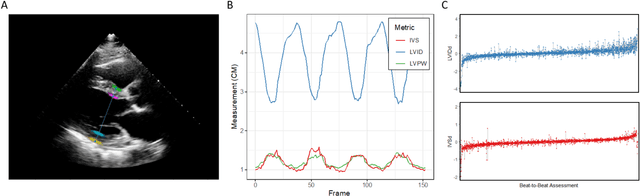
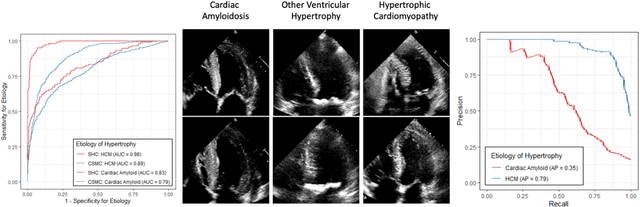
Left ventricular hypertrophy (LVH) results from chronic remodeling caused by a broad range of systemic and cardiovascular disease including hypertension, aortic stenosis, hypertrophic cardiomyopathy, and cardiac amyloidosis. Early detection and characterization of LVH can significantly impact patient care but is limited by under-recognition of hypertrophy, measurement error and variability, and difficulty differentiating etiologies of LVH. To overcome this challenge, we present EchoNet-LVH - a deep learning workflow that automatically quantifies ventricular hypertrophy with precision equal to human experts and predicts etiology of LVH. Trained on 28,201 echocardiogram videos, our model accurately measures intraventricular wall thickness (mean absolute error [MAE] 1.4mm, 95% CI 1.2-1.5mm), left ventricular diameter (MAE 2.4mm, 95% CI 2.2-2.6mm), and posterior wall thickness (MAE 1.2mm, 95% CI 1.1-1.3mm) and classifies cardiac amyloidosis (area under the curve of 0.83) and hypertrophic cardiomyopathy (AUC 0.98) from other etiologies of LVH. In external datasets from independent domestic and international healthcare systems, EchoNet-LVH accurately quantified ventricular parameters (R2 of 0.96 and 0.90 respectively) and detected cardiac amyloidosis (AUC 0.79) and hypertrophic cardiomyopathy (AUC 0.89) on the domestic external validation site. Leveraging measurements across multiple heart beats, our model can more accurately identify subtle changes in LV geometry and its causal etiologies. Compared to human experts, EchoNet-LVH is fully automated, allowing for reproducible, precise measurements, and lays the foundation for precision diagnosis of cardiac hypertrophy. As a resource to promote further innovation, we also make publicly available a large dataset of 23,212 annotated echocardiogram videos.