 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Counterfactuals on Reading Chest X-rays
Apr 02, 2023

This study evaluates the effect of counterfactual explanations on the interpretation of chest X-rays. We conduct a reader study with two radiologists assessing 240 chest X-ray predictions to rate their confidence that the model's prediction is correct using a 5 point scale. Half of the predictions are false positives. Each prediction is explained twice, once using traditional attribution methods and once with a counterfactual explanation. The overall results indicate that counterfactual explanations allow a radiologist to have more confidence in true positive predictions compared to traditional approaches (0.15$\pm$0.95 with p=0.01) with only a small increase in false positive predictions (0.04$\pm$1.06 with p=0.57). We observe the specific prediction tasks of Mass and Atelectasis appear to benefit the most compared to other tasks.
Gifsplanation via Latent Shift: A Simple Autoencoder Approach to Progressive Exaggeration on Chest X-rays
Feb 18, 2021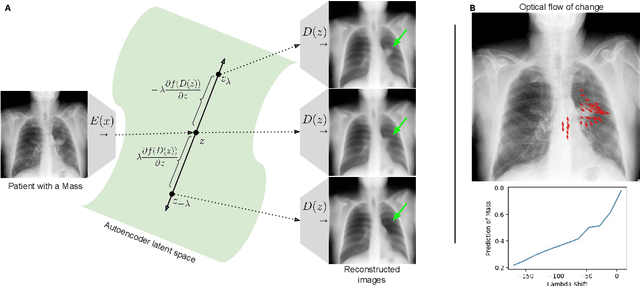
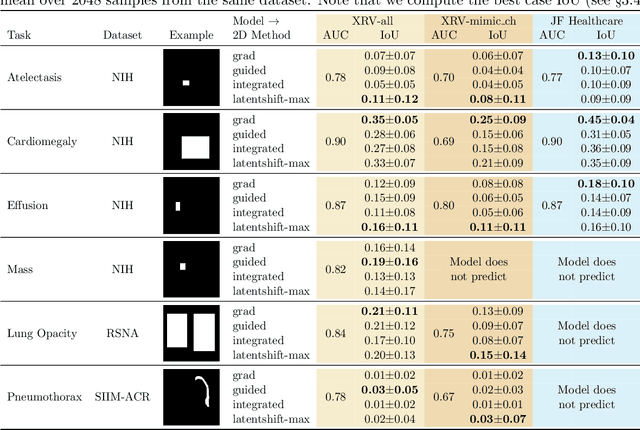
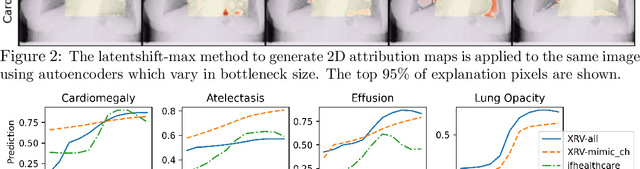

Motivation: Traditional image attribution methods struggle to satisfactorily explain predictions of neural networks. Prediction explanation is important, especially in the medical imaging, for avoiding the unintended consequences of deploying AI systems when false positive predictions can impact patient care. Thus, there is a pressing need to develop improved models for model explainability and introspection. Specific Problem: A new approach is to transform input images to increase or decrease features which cause the prediction. However, current approaches are difficult to implement as they are monolithic or rely on GANs. These hurdles prevent wide adoption. Our approach: Given an arbitrary classifier, we propose a simple autoencoder and gradient update (Latent Shift) that can transform the latent representation of an input image to exaggerate or curtail the features used for prediction. We use this method to study chest X-ray classifiers and evaluate their performance. We conduct a reader study with two radiologists assessing 240 chest X-ray predictions to identify which ones are false positives (half are) using traditional attribution maps or our proposed method. Results: We found low overlap with ground truth pathology masks for models with reasonably high accuracy. However, the results from our reader study indicate that these models are generally looking at the correct features. We also found that the Latent Shift explanation allows a user to have more confidence in true positive predictions compared to traditional approaches (0.15$\pm$0.95 in a 5 point scale with p=0.01) with only a small increase in false positive predictions (0.04$\pm$1.06 with p=0.57). Accompanying webpage: https://mlmed.org/gifsplanation Source code: https://github.com/mlmed/gifsplanation
RPNet: an End-to-End Network for Relative Camera Pose Estimation
Sep 22, 2018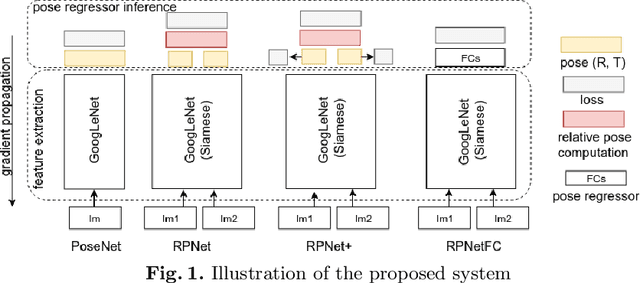

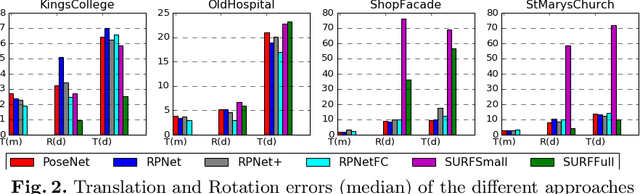
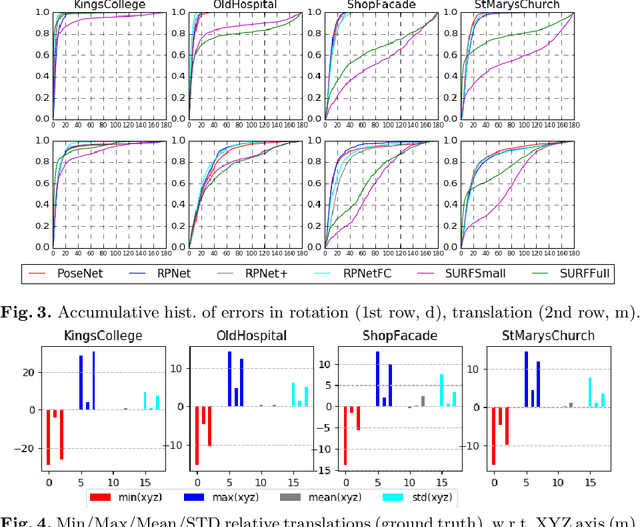
This paper addresses the task of relative camera pose estimation from raw image pixels, by means of deep neural networks. The proposed RPNet network takes pairs of images as input and directly infers the relative poses, without the need of camera intrinsic/extrinsic. While state-of-the-art systems based on SIFT + RANSAC, are able to recover the translation vector only up to scale, RPNet is trained to produce the full translation vector, in an end-to-end way. Experimental results on the Cambridge Landmark dataset show very promising results regarding the recovery of the full translation vector. They also show that RPNet produces more accurate and more stable results than traditional approaches, especially for hard images (repetitive textures, textureless images, etc). To the best of our knowledge, RPNet is the first attempt to recover full translation vectors in relative pose estimation.
TS-Net: Combining modality specific and common features for multimodal patch matching
Jun 05, 2018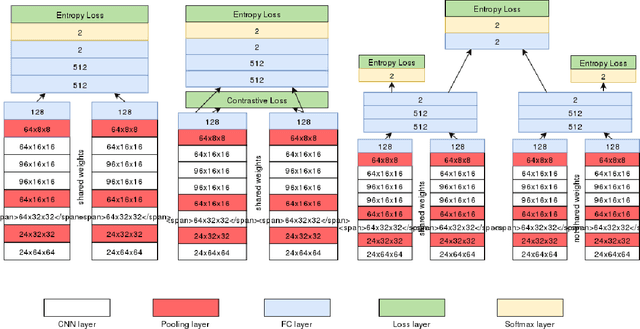
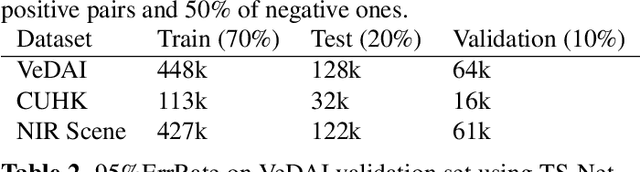

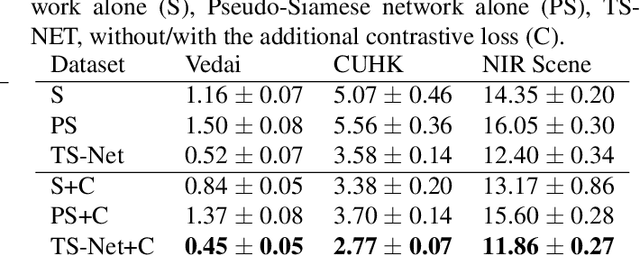
Multimodal patch matching addresses the problem of finding the correspondences between image patches from two different modalities, e.g. RGB vs sketch or RGB vs near-infrared. The comparison of patches of different modalities can be done by discovering the information common to both modalities (Siamese like approaches) or the modality-specific information (Pseudo-Siamese like approaches). We observed that none of these two scenarios is optimal. This motivates us to propose a three-stream architecture, dubbed as TS-Net, combining the benefits of the two. In addition, we show that adding extra constraints in the intermediate layers of such networks further boosts the performance. Experimentations on three multimodal datasets show significant performance gains in comparison with Siamese and Pseudo-Siamese networks.