 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFishRoPE: Projective Rotary Position Embeddings for Omnidirectional Visual Perception
Apr 12, 2026Vision foundation models (VFMs) and Bird's Eye View (BEV) representation have advanced visual perception substantially, yet their internal spatial representations assume the rectilinear geometry of pinhole cameras. Fisheye cameras, widely deployed on production autonomous vehicles for their surround-view coverage, exhibit severe radial distortion that renders these representations geometrically inconsistent. At the same time, the scarcity of large-scale fisheye annotations makes retraining foundation models from scratch impractical. We present \ours, a lightweight framework that adapts frozen VFMs to fisheye geometry through two components: a frozen DINOv2 backbone with Low-Rank Adaptation (LoRA) that transfers rich self-supervised features to fisheye without task-specific pretraining, and Fisheye Rotary Position Embedding (FishRoPE), which reparameterizes the attention mechanism in the spherical coordinates of the fisheye projection so that both self-attention and cross-attention operate on angular separation rather than pixel distance. FishRoPE is architecture-agnostic, introduces negligible computational overhead, and naturally reduces to the standard formulation under pinhole geometry. We evaluate \ours on WoodScape 2D detection (54.3 mAP) and SynWoodScapes BEV segmentation (65.1 mIoU), where it achieves state-of-the-art results on both benchmarks.
VisualCheXbert: Addressing the Discrepancy Between Radiology Report Labels and Image Labels
Mar 15, 2021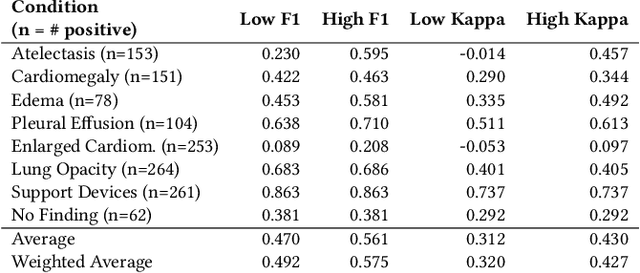
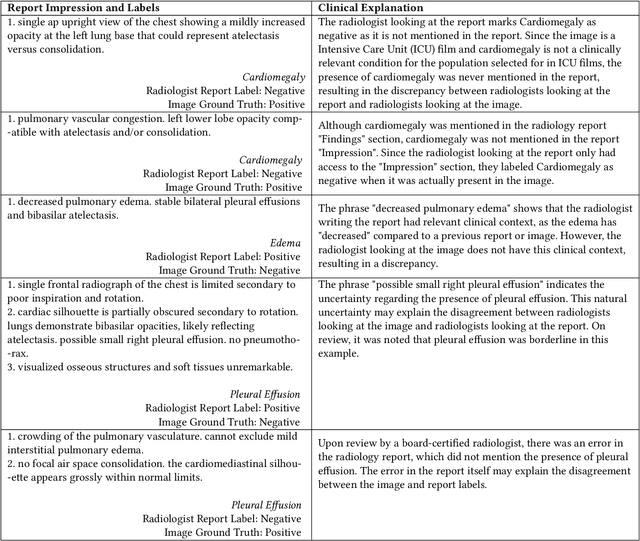
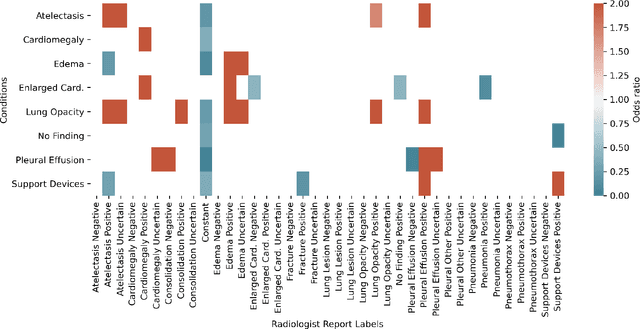
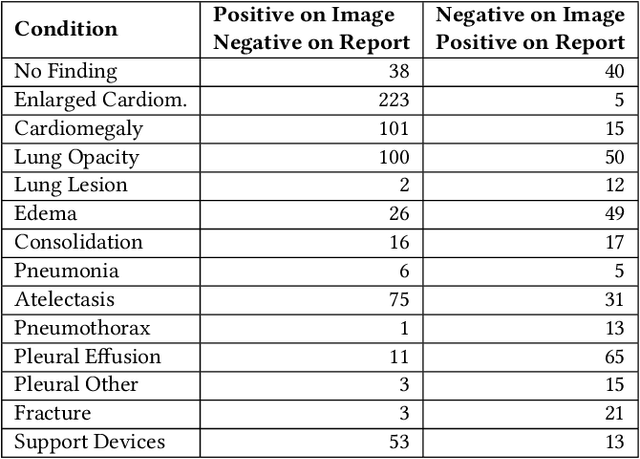
Automatic extraction of medical conditions from free-text radiology reports is critical for supervising computer vision models to interpret medical images. In this work, we show that radiologists labeling reports significantly disagree with radiologists labeling corresponding chest X-ray images, which reduces the quality of report labels as proxies for image labels. We develop and evaluate methods to produce labels from radiology reports that have better agreement with radiologists labeling images. Our best performing method, called VisualCheXbert, uses a biomedically-pretrained BERT model to directly map from a radiology report to the image labels, with a supervisory signal determined by a computer vision model trained to detect medical conditions from chest X-ray images. We find that VisualCheXbert outperforms an approach using an existing radiology report labeler by an average F1 score of 0.14 (95% CI 0.12, 0.17). We also find that VisualCheXbert better agrees with radiologists labeling chest X-ray images than do radiologists labeling the corresponding radiology reports by an average F1 score across several medical conditions of between 0.12 (95% CI 0.09, 0.15) and 0.21 (95% CI 0.18, 0.24).