 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistically Rewired Message-Passing Neural Networks
Oct 15, 2023Message-passing graph neural networks (MPNNs) emerged as powerful tools for processing graph-structured input. However, they operate on a fixed input graph structure, ignoring potential noise and missing information. Furthermore, their local aggregation mechanism can lead to problems such as over-squashing and limited expressive power in capturing relevant graph structures. Existing solutions to these challenges have primarily relied on heuristic methods, often disregarding the underlying data distribution. Hence, devising principled approaches for learning to infer graph structures relevant to the given prediction task remains an open challenge. In this work, leveraging recent progress in exact and differentiable $k$-subset sampling, we devise probabilistically rewired MPNNs (PR-MPNNs), which learn to add relevant edges while omitting less beneficial ones. For the first time, our theoretical analysis explores how PR-MPNNs enhance expressive power, and we identify precise conditions under which they outperform purely randomized approaches. Empirically, we demonstrate that our approach effectively mitigates issues like over-squashing and under-reaching. In addition, on established real-world datasets, our method exhibits competitive or superior predictive performance compared to traditional MPNN models and recent graph transformer architectures.
Approximate Answering of Graph Queries
Aug 12, 2023Knowledge graphs (KGs) are inherently incomplete because of incomplete world knowledge and bias in what is the input to the KG. Additionally, world knowledge constantly expands and evolves, making existing facts deprecated or introducing new ones. However, we would still want to be able to answer queries as if the graph were complete. In this chapter, we will give an overview of several methods which have been proposed to answer queries in such a setting. We will first provide an overview of the different query types which can be supported by these methods and datasets typically used for evaluation, as well as an insight into their limitations. Then, we give an overview of the different approaches and describe them in terms of expressiveness, supported graph types, and inference capabilities.
Learning Disentangled Discrete Representations
Jul 26, 2023



Recent successes in image generation, model-based reinforcement learning, and text-to-image generation have demonstrated the empirical advantages of discrete latent representations, although the reasons behind their benefits remain unclear. We explore the relationship between discrete latent spaces and disentangled representations by replacing the standard Gaussian variational autoencoder (VAE) with a tailored categorical variational autoencoder. We show that the underlying grid structure of categorical distributions mitigates the problem of rotational invariance associated with multivariate Gaussian distributions, acting as an efficient inductive prior for disentangled representations. We provide both analytical and empirical findings that demonstrate the advantages of discrete VAEs for learning disentangled representations. Furthermore, we introduce the first unsupervised model selection strategy that favors disentangled representations.
Efficient Learning of Discrete-Continuous Computation Graphs
Jul 26, 2023



Numerous models for supervised and reinforcement learning benefit from combinations of discrete and continuous model components. End-to-end learnable discrete-continuous models are compositional, tend to generalize better, and are more interpretable. A popular approach to building discrete-continuous computation graphs is that of integrating discrete probability distributions into neural networks using stochastic softmax tricks. Prior work has mainly focused on computation graphs with a single discrete component on each of the graph's execution paths. We analyze the behavior of more complex stochastic computations graphs with multiple sequential discrete components. We show that it is challenging to optimize the parameters of these models, mainly due to small gradients and local minima. We then propose two new strategies to overcome these challenges. First, we show that increasing the scale parameter of the Gumbel noise perturbations during training improves the learning behavior. Second, we propose dropout residual connections specifically tailored to stochastic, discrete-continuous computation graphs. With an extensive set of experiments, we show that we can train complex discrete-continuous models which one cannot train with standard stochastic softmax tricks. We also show that complex discrete-stochastic models generalize better than their continuous counterparts on several benchmark datasets.
LVM-Med: Learning Large-Scale Self-Supervised Vision Models for Medical Imaging via Second-order Graph Matching
Jul 09, 2023



Obtaining large pre-trained models that can be fine-tuned to new tasks with limited annotated samples has remained an open challenge for medical imaging data. While pre-trained deep networks on ImageNet and vision-language foundation models trained on web-scale data are prevailing approaches, their effectiveness on medical tasks is limited due to the significant domain shift between natural and medical images. To bridge this gap, we introduce LVM-Med, the first family of deep networks trained on large-scale medical datasets. We have collected approximately 1.3 million medical images from 55 publicly available datasets, covering a large number of organs and modalities such as CT, MRI, X-ray, and Ultrasound. We benchmark several state-of-the-art self-supervised algorithms on this dataset and propose a novel self-supervised contrastive learning algorithm using a graph-matching formulation. The proposed approach makes three contributions: (i) it integrates prior pair-wise image similarity metrics based on local and global information; (ii) it captures the structural constraints of feature embeddings through a loss function constructed via a combinatorial graph-matching objective; and (iii) it can be trained efficiently end-to-end using modern gradient-estimation techniques for black-box solvers. We thoroughly evaluate the proposed LVM-Med on 15 downstream medical tasks ranging from segmentation and classification to object detection, and both for the in and out-of-distribution settings. LVM-Med empirically outperforms a number of state-of-the-art supervised, self-supervised, and foundation models. For challenging tasks such as Brain Tumor Classification or Diabetic Retinopathy Grading, LVM-Med improves previous vision-language models trained on 1 billion masks by 6-7% while using only a ResNet-50.
Tractable Probabilistic Graph Representation Learning with Graph-Induced Sum-Product Networks
May 17, 2023We introduce Graph-Induced Sum-Product Networks (GSPNs), a new probabilistic framework for graph representation learning that can tractably answer probabilistic queries. Inspired by the computational trees induced by vertices in the context of message-passing neural networks, we build hierarchies of sum-product networks (SPNs) where the parameters of a parent SPN are learnable transformations of the a-posterior mixing probabilities of its children's sum units. Due to weight sharing and the tree-shaped computation graphs of GSPNs, we obtain the efficiency and efficacy of deep graph networks with the additional advantages of a purely probabilistic model. We show the model's competitiveness on scarce supervision scenarios, handling missing data, and graph classification in comparison to popular neural models. We complement the experiments with qualitative analyses on hyper-parameters and the model's ability to answer probabilistic queries.
Learning Neural PDE Solvers with Parameter-Guided Channel Attention
Apr 27, 2023Scientific Machine Learning (SciML) is concerned with the development of learned emulators of physical systems governed by partial differential equations (PDE). In application domains such as weather forecasting, molecular dynamics, and inverse design, ML-based surrogate models are increasingly used to augment or replace inefficient and often non-differentiable numerical simulation algorithms. While a number of ML-based methods for approximating the solutions of PDEs have been proposed in recent years, they typically do not adapt to the parameters of the PDEs, making it difficult to generalize to PDE parameters not seen during training. We propose a Channel Attention mechanism guided by PDE Parameter Embeddings (CAPE) component for neural surrogate models and a simple yet effective curriculum learning strategy. The CAPE module can be combined with neural PDE solvers allowing them to adapt to unseen PDE parameters. The curriculum learning strategy provides a seamless transition between teacher-forcing and fully auto-regressive training. We compare CAPE in conjunction with the curriculum learning strategy using a popular PDE benchmark and obtain consistent and significant improvements over the baseline models. The experiments also show several advantages of CAPE, such as its increased ability to generalize to unseen PDE parameters without large increases inference time and parameter count.
Learning Sparsity of Representations with Discrete Latent Variables
Apr 03, 2023Deep latent generative models have attracted increasing attention due to the capacity of combining the strengths of deep learning and probabilistic models in an elegant way. The data representations learned with the models are often continuous and dense. However in many applications, sparse representations are expected, such as learning sparse high dimensional embedding of data in an unsupervised setting, and learning multi-labels from thousands of candidate tags in a supervised setting. In some scenarios, there could be further restriction on degree of sparsity: the number of non-zero features of a representation cannot be larger than a pre-defined threshold $L_0$. In this paper we propose a sparse deep latent generative model SDLGM to explicitly model degree of sparsity and thus enable to learn the sparse structure of the data with the quantified sparsity constraint. The resulting sparsity of a representation is not fixed, but fits to the observation itself under the pre-defined restriction. In particular, we introduce to each observation $i$ an auxiliary random variable $L_i$, which models the sparsity of its representation. The sparse representations are then generated with a two-step sampling process via two Gumbel-Softmax distributions. For inference and learning, we develop an amortized variational method based on MC gradient estimator. The resulting sparse representations are differentiable with backpropagation. The experimental evaluation on multiple datasets for unsupervised and supervised learning problems shows the benefits of the proposed method.
State-Regularized Recurrent Neural Networks to Extract Automata and Explain Predictions
Dec 10, 2022Recurrent neural networks are a widely used class of neural architectures. They have, however, two shortcomings. First, they are often treated as black-box models and as such it is difficult to understand what exactly they learn as well as how they arrive at a particular prediction. Second, they tend to work poorly on sequences requiring long-term memorization, despite having this capacity in principle. We aim to address both shortcomings with a class of recurrent networks that use a stochastic state transition mechanism between cell applications. This mechanism, which we term state-regularization, makes RNNs transition between a finite set of learnable states. We evaluate state-regularized RNNs on (1) regular languages for the purpose of automata extraction; (2) non-regular languages such as balanced parentheses and palindromes where external memory is required; and (3) real-word sequence learning tasks for sentiment analysis, visual object recognition and text categorisation. We show that state-regularization (a) simplifies the extraction of finite state automata that display an RNN's state transition dynamic; (b) forces RNNs to operate more like automata with external memory and less like finite state machines, which potentiality leads to a more structural memory; (c) leads to better interpretability and explainability of RNNs by leveraging the probabilistic finite state transition mechanism over time steps.
Joint Multilingual Knowledge Graph Completion and Alignment
Oct 18, 2022
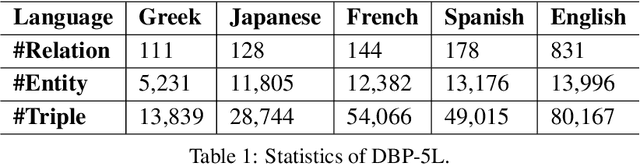
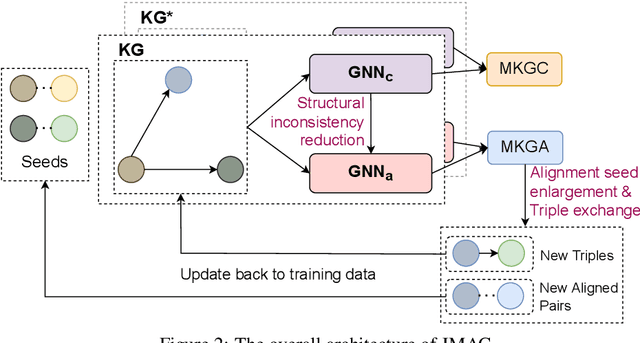
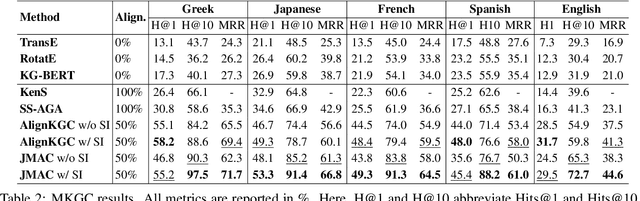
Knowledge graph (KG) alignment and completion are usually treated as two independent tasks. While recent work has leveraged entity and relation alignments from multiple KGs, such as alignments between multilingual KGs with common entities and relations, a deeper understanding of the ways in which multilingual KG completion (MKGC) can aid the creation of multilingual KG alignments (MKGA) is still limited. Motivated by the observation that structural inconsistencies -- the main challenge for MKGA models -- can be mitigated through KG completion methods, we propose a novel model for jointly completing and aligning knowledge graphs. The proposed model combines two components that jointly accomplish KG completion and alignment. These two components employ relation-aware graph neural networks that we propose to encode multi-hop neighborhood structures into entity and relation representations. Moreover, we also propose (i) a structural inconsistency reduction mechanism to incorporate information from the completion into the alignment component, and (ii) an alignment seed enlargement and triple transferring mechanism to enlarge alignment seeds and transfer triples during KGs alignment. Extensive experiments on a public multilingual benchmark show that our proposed model outperforms existing competitive baselines, obtaining new state-of-the-art results on both MKGC and MKGA tasks. We publicly release the implementation of our model at https://github.com/vinhsuhi/JMAC