 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtmospheric Transport Modeling of CO$_2$ with Neural Networks
Aug 20, 2024Accurately describing the distribution of CO$_2$ in the atmosphere with atmospheric tracer transport models is essential for greenhouse gas monitoring and verification support systems to aid implementation of international climate agreements. Large deep neural networks are poised to revolutionize weather prediction, which requires 3D modeling of the atmosphere. While similar in this regard, atmospheric transport modeling is subject to new challenges. Both, stable predictions for longer time horizons and mass conservation throughout need to be achieved, while IO plays a larger role compared to computational costs. In this study we explore four different deep neural networks (UNet, GraphCast, Spherical Fourier Neural Operator and SwinTransformer) which have proven as state-of-the-art in weather prediction to assess their usefulness for atmospheric tracer transport modeling. For this, we assemble the CarbonBench dataset, a systematic benchmark tailored for machine learning emulators of Eulerian atmospheric transport. Through architectural adjustments, we decouple the performance of our emulators from the distribution shift caused by a steady rise in atmospheric CO$_2$. More specifically, we center CO$_2$ input fields to zero mean and then use an explicit flux scheme and a mass fixer to assure mass balance. This design enables stable and mass conserving transport for over 6 months with all four neural network architectures. In our study, the SwinTransformer displays particularly strong emulation skill (90-day $R^2 > 0.99$), with physically plausible emulation even for forward runs of multiple years. This work paves the way forward towards high resolution forward and inverse modeling of inert trace gases with neural networks.
Comparing Data-Driven and Mechanistic Models for Predicting Phenology in Deciduous Broadleaf Forests
Jan 08, 2024Understanding the future climate is crucial for informed policy decisions on climate change prevention and mitigation. Earth system models play an important role in predicting future climate, requiring accurate representation of complex sub-processes that span multiple time scales and spatial scales. One such process that links seasonal and interannual climate variability to cyclical biological events is tree phenology in deciduous broadleaf forests. Phenological dates, such as the start and end of the growing season, are critical for understanding the exchange of carbon and water between the biosphere and the atmosphere. Mechanistic prediction of these dates is challenging. Hybrid modelling, which integrates data-driven approaches into complex models, offers a solution. In this work, as a first step towards this goal, train a deep neural network to predict a phenological index from meteorological time series. We find that this approach outperforms traditional process-based models. This highlights the potential of data-driven methods to improve climate predictions. We also analyze which variables and aspects of the time series influence the predicted onset of the season, in order to gain a better understanding of the advantages and limitations of our model.
Learning Disentangled Discrete Representations
Jul 26, 2023



Recent successes in image generation, model-based reinforcement learning, and text-to-image generation have demonstrated the empirical advantages of discrete latent representations, although the reasons behind their benefits remain unclear. We explore the relationship between discrete latent spaces and disentangled representations by replacing the standard Gaussian variational autoencoder (VAE) with a tailored categorical variational autoencoder. We show that the underlying grid structure of categorical distributions mitigates the problem of rotational invariance associated with multivariate Gaussian distributions, acting as an efficient inductive prior for disentangled representations. We provide both analytical and empirical findings that demonstrate the advantages of discrete VAEs for learning disentangled representations. Furthermore, we introduce the first unsupervised model selection strategy that favors disentangled representations.
Towards Learning an Unbiased Classifier from Biased Data via Conditional Adversarial Debiasing
Mar 10, 2021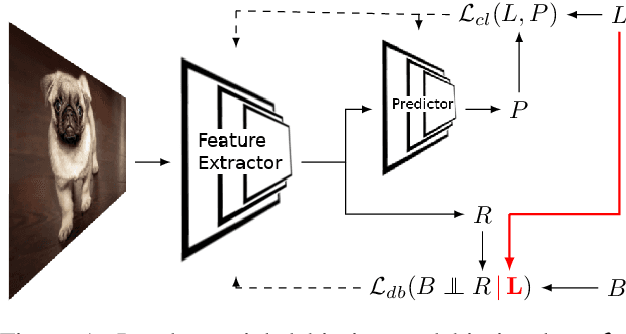
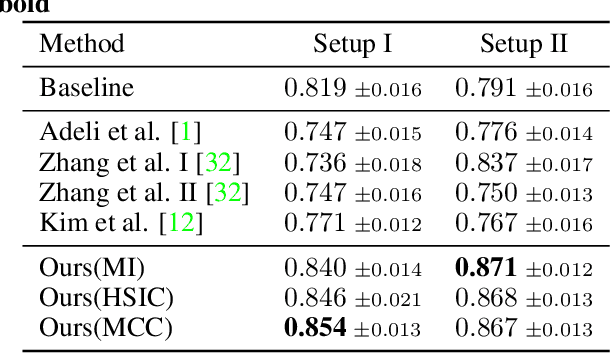
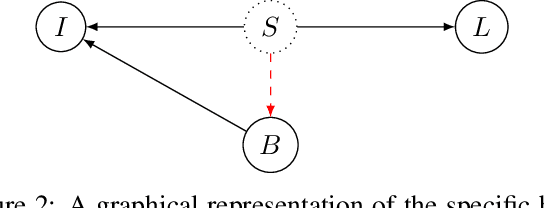
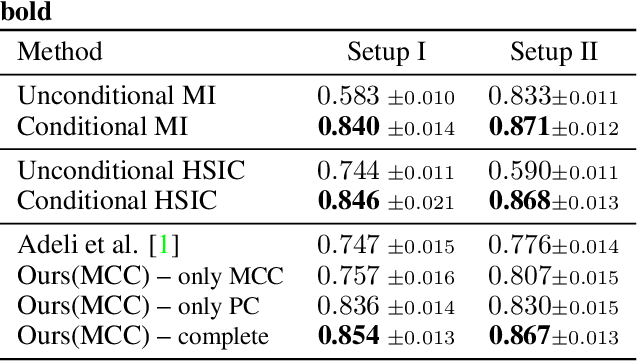
Bias in classifiers is a severe issue of modern deep learning methods, especially for their application in safety- and security-critical areas. Often, the bias of a classifier is a direct consequence of a bias in the training dataset, frequently caused by the co-occurrence of relevant features and irrelevant ones. To mitigate this issue, we require learning algorithms that prevent the propagation of bias from the dataset into the classifier. We present a novel adversarial debiasing method, which addresses a feature that is spuriously connected to the labels of training images but statistically independent of the labels for test images. Thus, the automatic identification of relevant features during training is perturbed by irrelevant features. This is the case in a wide range of bias-related problems for many computer vision tasks, such as automatic skin cancer detection or driver assistance. We argue by a mathematical proof that our approach is superior to existing techniques for the abovementioned bias. Our experiments show that our approach performs better than state-of-the-art techniques on a well-known benchmark dataset with real-world images of cats and dogs.