 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Family of LLMs Liberated from Static Vocabularies
Mar 16, 2026Tokenization is a central component of natural language processing in current large language models (LLMs), enabling models to convert raw text into processable units. Although learned tokenizers are widely adopted, they exhibit notable limitations, including their large, fixed vocabulary sizes and poor adaptability to new domains or languages. We present a family of models with up to 70 billion parameters based on the hierarchical autoregressive transformer (HAT) architecture. In HAT, an encoder transformer aggregates bytes into word embeddings and then feeds them to the backbone, a classical autoregressive transformer. The outputs of the backbone are then cross-attended by the decoder and converted back into bytes. We show that we can reuse available pre-trained models by converting the Llama 3.1 8B and 70B models into the HAT architecture: Llama-3.1-8B-TFree-HAT and Llama-3.1-70B-TFree-HAT are byte-level models whose encoder and decoder are trained from scratch, but where we adapt the pre-trained Llama backbone, i.e., the transformer blocks with the embedding matrix and head removed, to handle word embeddings instead of the original tokens. We also provide a 7B HAT model, Llama-TFree-HAT-Pretrained, trained entirely from scratch on nearly 4 trillion words. The HAT architecture improves text compression by reducing the number of required sequence positions and enhances robustness to intra-word variations, e.g., spelling differences. Through pre-training, as well as subsequent supervised fine-tuning and direct preference optimization in English and German, we show strong proficiency in both languages, improving on the original Llama 3.1 in most benchmarks. We release our models (including 200 pre-training checkpoints) on Hugging Face.
AgentQuest: A Modular Benchmark Framework to Measure Progress and Improve LLM Agents
Apr 09, 2024The advances made by Large Language Models (LLMs) have led to the pursuit of LLM agents that can solve intricate, multi-step reasoning tasks. As with any research pursuit, benchmarking and evaluation are key corner stones to efficient and reliable progress. However, existing benchmarks are often narrow and simply compute overall task success. To face these issues, we propose AgentQuest -- a framework where (i) both benchmarks and metrics are modular and easily extensible through well documented and easy-to-use APIs; (ii) we offer two new evaluation metrics that can reliably track LLM agent progress while solving a task. We exemplify the utility of the metrics on two use cases wherein we identify common failure points and refine the agent architecture to obtain a significant performance increase. Together with the research community, we hope to extend AgentQuest further and therefore we make it available under https://github.com/nec-research/agentquest.
Efficient Learning of Discrete-Continuous Computation Graphs
Jul 26, 2023



Numerous models for supervised and reinforcement learning benefit from combinations of discrete and continuous model components. End-to-end learnable discrete-continuous models are compositional, tend to generalize better, and are more interpretable. A popular approach to building discrete-continuous computation graphs is that of integrating discrete probability distributions into neural networks using stochastic softmax tricks. Prior work has mainly focused on computation graphs with a single discrete component on each of the graph's execution paths. We analyze the behavior of more complex stochastic computations graphs with multiple sequential discrete components. We show that it is challenging to optimize the parameters of these models, mainly due to small gradients and local minima. We then propose two new strategies to overcome these challenges. First, we show that increasing the scale parameter of the Gumbel noise perturbations during training improves the learning behavior. Second, we propose dropout residual connections specifically tailored to stochastic, discrete-continuous computation graphs. With an extensive set of experiments, we show that we can train complex discrete-continuous models which one cannot train with standard stochastic softmax tricks. We also show that complex discrete-stochastic models generalize better than their continuous counterparts on several benchmark datasets.
Learning Disentangled Discrete Representations
Jul 26, 2023



Recent successes in image generation, model-based reinforcement learning, and text-to-image generation have demonstrated the empirical advantages of discrete latent representations, although the reasons behind their benefits remain unclear. We explore the relationship between discrete latent spaces and disentangled representations by replacing the standard Gaussian variational autoencoder (VAE) with a tailored categorical variational autoencoder. We show that the underlying grid structure of categorical distributions mitigates the problem of rotational invariance associated with multivariate Gaussian distributions, acting as an efficient inductive prior for disentangled representations. We provide both analytical and empirical findings that demonstrate the advantages of discrete VAEs for learning disentangled representations. Furthermore, we introduce the first unsupervised model selection strategy that favors disentangled representations.
Neural Architecture Performance Prediction Using Graph Neural Networks
Oct 19, 2020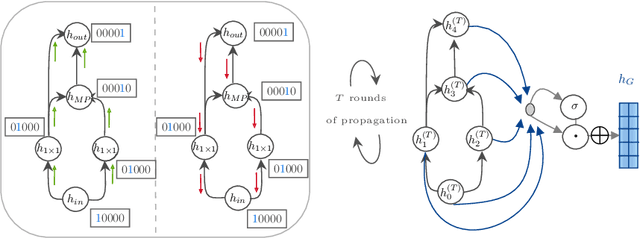

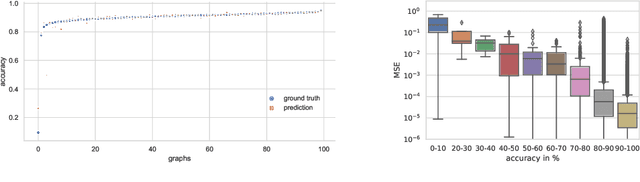
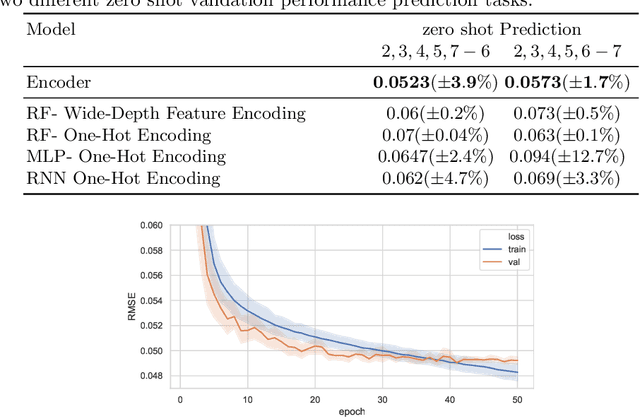
In computer vision research, the process of automating architecture engineering, Neural Architecture Search (NAS), has gained substantial interest. Due to the high computational costs, most recent approaches to NAS as well as the few available benchmarks only provide limited search spaces. In this paper we propose a surrogate model for neural architecture performance prediction built upon Graph Neural Networks (GNN). We demonstrate the effectiveness of this surrogate model on neural architecture performance prediction for structurally unknown architectures (i.e. zero shot prediction) by evaluating the GNN on several experiments on the NAS-Bench-101 dataset.
Smooth Variational Graph Embeddings for Efficient Neural Architecture Search
Oct 09, 2020
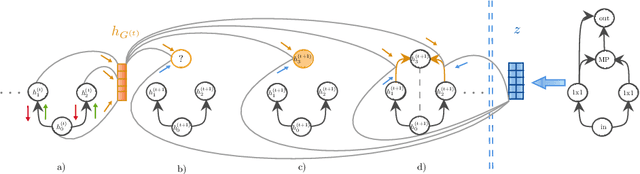
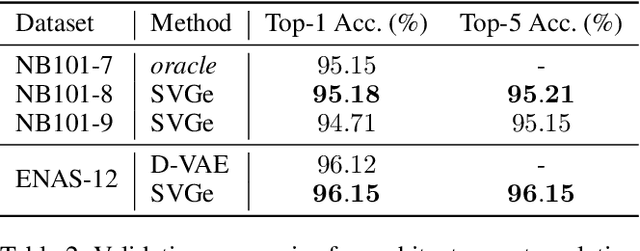
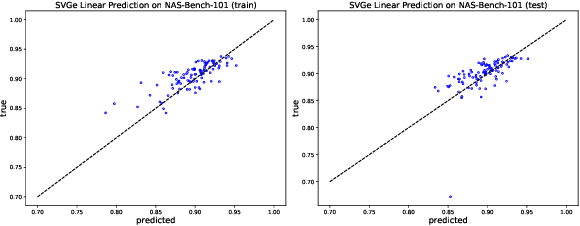
In this paper, we propose an approach to neural architecture search (NAS) based on graph embeddings. NAS has been addressed previously using discrete, sampling based methods, which are computationally expensive as well as differentiable approaches, which come at lower costs but enforce stronger constraints on the search space. The proposed approach leverages advantages from both sides by building a smooth variational neural architecture embedding space in which we evaluate a structural subset of architectures at training time using the predicted performance while it allows to extrapolate from this subspace at inference time. We evaluate the proposed approach in the context of two common search spaces, the graph structure defined by the ENAS approach and the NAS-Bench-101 search space, and improve over the state of the art in both.
A Variational-Sequential Graph Autoencoder for Neural Architecture Performance Prediction
Dec 11, 2019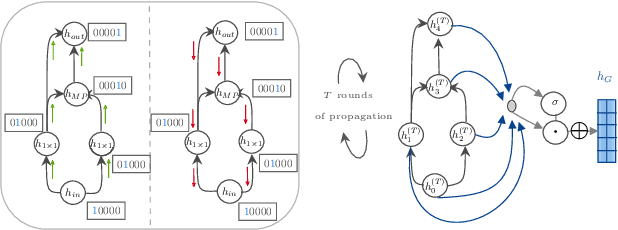

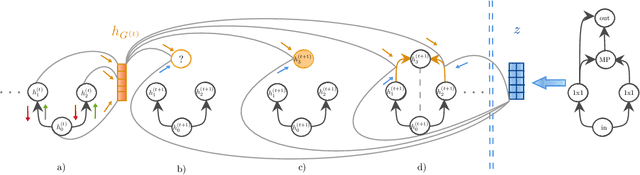

In computer vision research, the process of automating architecture engineering, Neural Architecture Search (NAS), has gained substantial interest. In the past, NAS was hardly accessible to researchers without access to large-scale compute systems, due to very long compute times for the recurrent search and evaluation of new candidate architectures. The NAS-Bench-101 dataset facilitates a paradigm change towards classical methods such as supervised learning to evaluate neural architectures. In this paper, we propose a graph encoder built upon Graph Neural Networks (GNN). We demonstrate the effectiveness of the proposed encoder on NAS performance prediction for seen architecture types as well an unseen ones (i.e., zero shot prediction). We also provide a new variational-sequential graph autoencoder (VS-GAE) based on the proposed graph encoder. The VS-GAE is specialized on encoding and decoding graphs of varying length utilizing GNNs. Experiments on different sampling methods show that the embedding space learned by our VS-GAE increases the stability on the accuracy prediction task.