 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Cognitive Reasoners: Modular Reasoning with Brain-Like Specialization
Jun 16, 2025



Human intelligence emerges from the interaction of specialized brain networks, each dedicated to distinct cognitive functions such as language processing, logical reasoning, social understanding, and memory retrieval. Inspired by this biological observation, we introduce the Mixture of Cognitive Reasoners (MiCRo) architecture and training paradigm: a modular transformer-based language model with a training curriculum that encourages the emergence of functional specialization among different modules. Inspired by studies in neuroscience, we partition the layers of a pretrained transformer model into four expert modules, each corresponding to a well-studied cognitive brain network. Our Brain-Like model has three key benefits over the state of the art: First, the specialized experts are highly interpretable and functionally critical, where removing a module significantly impairs performance on domain-relevant benchmarks. Second, our model outperforms comparable baselines that lack specialization on seven reasoning benchmarks. And third, the model's behavior can be steered at inference time by selectively emphasizing certain expert modules (e.g., favoring social over logical reasoning), enabling fine-grained control over the style of its response. Our findings suggest that biologically inspired inductive biases involved in human cognition lead to significant modeling gains in interpretability, performance, and controllability.
Contour Integration Underlies Human-Like Vision
Apr 07, 2025



Despite the tremendous success of deep learning in computer vision, models still fall behind humans in generalizing to new input distributions. Existing benchmarks do not investigate the specific failure points of models by analyzing performance under many controlled conditions. Our study systematically dissects where and why models struggle with contour integration -- a hallmark of human vision -- by designing an experiment that tests object recognition under various levels of object fragmentation. Humans (n=50) perform at high accuracy, even with few object contours present. This is in contrast to models which exhibit substantially lower sensitivity to increasing object contours, with most of the over 1,000 models we tested barely performing above chance. Only at very large scales ($\sim5B$ training dataset size) do models begin to approach human performance. Importantly, humans exhibit an integration bias -- a preference towards recognizing objects made up of directional fragments over directionless fragments. We find that not only do models that share this property perform better at our task, but that this bias also increases with model training dataset size, and training models to exhibit contour integration leads to high shape bias. Taken together, our results suggest that contour integration is a hallmark of object vision that underlies object recognition performance, and may be a mechanism learned from data at scale.
From Language to Cognition: How LLMs Outgrow the Human Language Network
Mar 03, 2025Large language models (LLMs) exhibit remarkable similarity to neural activity in the human language network. However, the key properties of language shaping brain-like representations, and their evolution during training as a function of different tasks remain unclear. We here benchmark 34 training checkpoints spanning 300B tokens across 8 different model sizes to analyze how brain alignment relates to linguistic competence. Specifically, we find that brain alignment tracks the development of formal linguistic competence -- i.e., knowledge of linguistic rules -- more closely than functional linguistic competence. While functional competence, which involves world knowledge and reasoning, continues to develop throughout training, its relationship with brain alignment is weaker, suggesting that the human language network primarily encodes formal linguistic structure rather than broader cognitive functions. We further show that model size is not a reliable predictor of brain alignment when controlling for feature size and find that the correlation between next-word prediction, behavioral alignment and brain alignment fades once models surpass human language proficiency. Finally, using the largest set of rigorous neural language benchmarks to date, we show that language brain alignment benchmarks remain unsaturated, highlighting opportunities for improving future models. Taken together, our findings suggest that the human language network is best modeled by formal, rather than functional, aspects of language.
Scaling Laws for Task-Optimized Models of the Primate Visual Ventral Stream
Nov 08, 2024When trained on large-scale object classification datasets, certain artificial neural network models begin to approximate core object recognition (COR) behaviors and neural response patterns in the primate visual ventral stream (VVS). While recent machine learning advances suggest that scaling model size, dataset size, and compute resources improve task performance, the impact of scaling on brain alignment remains unclear. In this study, we explore scaling laws for modeling the primate VVS by systematically evaluating over 600 models trained under controlled conditions on benchmarks spanning V1, V2, V4, IT and COR behaviors. We observe that while behavioral alignment continues to scale with larger models, neural alignment saturates. This observation remains true across model architectures and training datasets, even though models with stronger inductive bias and datasets with higher-quality images are more compute-efficient. Increased scaling is especially beneficial for higher-level visual areas, where small models trained on few samples exhibit only poor alignment. Finally, we develop a scaling recipe, indicating that a greater proportion of compute should be allocated to data samples over model size. Our results suggest that while scaling alone might suffice for alignment with human core object recognition behavior, it will not yield improved models of the brain's visual ventral stream with current architectures and datasets, highlighting the need for novel strategies in building brain-like models.
The LLM Language Network: A Neuroscientific Approach for Identifying Causally Task-Relevant Units
Nov 04, 2024



Large language models (LLMs) exhibit remarkable capabilities on not just language tasks, but also various tasks that are not linguistic in nature, such as logical reasoning and social inference. In the human brain, neuroscience has identified a core language system that selectively and causally supports language processing. We here ask whether similar specialization for language emerges in LLMs. We identify language-selective units within 18 popular LLMs, using the same localization approach that is used in neuroscience. We then establish the causal role of these units by demonstrating that ablating LLM language-selective units -- but not random units -- leads to drastic deficits in language tasks. Correspondingly, language-selective LLM units are more aligned to brain recordings from the human language system than random units. Finally, we investigate whether our localization method extends to other cognitive domains: while we find specialized networks in some LLMs for reasoning and social capabilities, there are substantial differences among models. These findings provide functional and causal evidence for specialization in large language models, and highlight parallels with the functional organization in the brain.
Dreaming Out Loud: A Self-Synthesis Approach For Training Vision-Language Models With Developmentally Plausible Data
Oct 29, 2024



While today's large language models exhibit impressive abilities in generating human-like text, they require massive amounts of data during training. We here take inspiration from human cognitive development to train models in limited data conditions. Specifically we present a self-synthesis approach that iterates through four phases: Phase 1 sets up fundamental language abilities, training the model from scratch on a small corpus. Language is then associated with the visual environment in phase 2, integrating the model with a vision encoder to generate descriptive captions from labeled images. In the "self-synthesis" phase 3, the model generates captions for unlabeled images, that it then uses to further train its language component with a mix of synthetic, and previous real-world text. This phase is meant to expand the model's linguistic repertoire, similar to humans self-annotating new experiences. Finally, phase 4 develops advanced cognitive skills, by training the model on specific tasks such as visual question answering and reasoning. Our approach offers a proof of concept for training a multimodal model using a developmentally plausible amount of data.
TopoLM: brain-like spatio-functional organization in a topographic language model
Oct 15, 2024



Neurons in the brain are spatially organized such that neighbors on tissue often exhibit similar response profiles. In the human language system, experimental studies have observed clusters for syntactic and semantic categories, but the mechanisms underlying this functional organization remain unclear. Here, building on work from the vision literature, we develop TopoLM, a transformer language model with an explicit two-dimensional spatial representation of model units. By combining a next-token prediction objective with a spatial smoothness loss, representations in this model assemble into clusters that correspond to semantically interpretable groupings of text and closely match the functional organization in the brain's language system. TopoLM successfully predicts the emergence of the spatio-functional organization of a cortical language system as well as the organization of functional clusters selective for fine-grained linguistic features empirically observed in human cortex. Our results suggest that the functional organization of the human language system is driven by a unified spatial objective, and provide a functionally and spatially aligned model of language processing in the brain.
Brain-Like Language Processing via a Shallow Untrained Multihead Attention Network
Jun 21, 2024



Large Language Models (LLMs) have been shown to be effective models of the human language system, with some models predicting most explainable variance of brain activity in current datasets. Even in untrained models, the representations induced by architectural priors can exhibit reasonable alignment to brain data. In this work, we investigate the key architectural components driving the surprising alignment of untrained models. To estimate LLM-to-brain similarity, we first select language-selective units within an LLM, similar to how neuroscientists identify the language network in the human brain. We then benchmark the brain alignment of these LLM units across five different brain recording datasets. By isolating critical components of the Transformer architecture, we identify tokenization strategy and multihead attention as the two major components driving brain alignment. A simple form of recurrence further improves alignment. We further demonstrate this quantitative brain alignment of our model by reproducing landmark studies in the language neuroscience field, showing that localized model units -- just like language voxels measured empirically in the human brain -- discriminate more reliably between lexical than syntactic differences, and exhibit similar response profiles under the same experimental conditions. Finally, we demonstrate the utility of our model's representations for language modeling, achieving improved sample and parameter efficiency over comparable architectures. Our model's estimates of surprisal sets a new state-of-the-art in the behavioral alignment to human reading times. Taken together, we propose a highly brain- and behaviorally-aligned model that conceptualizes the human language system as an untrained shallow feature encoder, with structural priors, combined with a trained decoder to achieve efficient and performant language processing.
Instruction-tuning Aligns LLMs to the Human Brain
Dec 01, 2023



Instruction-tuning is a widely adopted method of finetuning that enables large language models (LLMs) to generate output that more closely resembles human responses to natural language queries, in many cases leading to human-level performance on diverse testbeds. However, it remains unclear whether instruction-tuning truly makes LLMs more similar to how humans process language. We investigate the effect of instruction-tuning on LLM-human similarity in two ways: (1) brain alignment, the similarity of LLM internal representations to neural activity in the human language system, and (2) behavioral alignment, the similarity of LLM and human behavior on a reading task. We assess 25 vanilla and instruction-tuned LLMs across three datasets involving humans reading naturalistic stories and sentences. We discover that instruction-tuning generally enhances brain alignment by an average of 6%, but does not have a similar effect on behavioral alignment. To identify the factors underlying LLM-brain alignment, we compute correlations between the brain alignment of LLMs and various model properties, such as model size, various problem-solving abilities, and performance on tasks requiring world knowledge spanning various domains. Notably, we find a strong positive correlation between brain alignment and model size (r = 0.95), as well as performance on tasks requiring world knowledge (r = 0.81). Our results demonstrate that instruction-tuning LLMs improves both world knowledge representations and brain alignment, suggesting that mechanisms that encode world knowledge in LLMs also improve representational alignment to the human brain.
ThreeDWorld: A Platform for Interactive Multi-Modal Physical Simulation
Jul 09, 2020
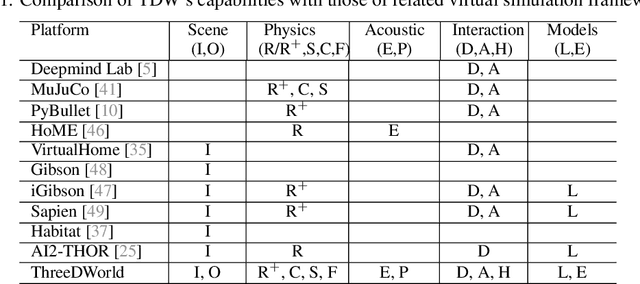

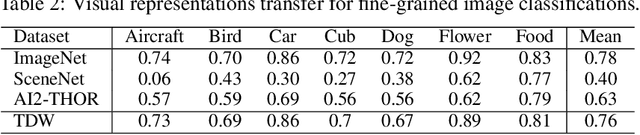
We introduce ThreeDWorld (TDW), a platform for interactive multi-modal physical simulation. With TDW, users can simulate high-fidelity sensory data and physical interactions between mobile agents and objects in a wide variety of rich 3D environments. TDW has several unique properties: 1) realtime near photo-realistic image rendering quality; 2) a library of objects and environments with materials for high-quality rendering, and routines enabling user customization of the asset library; 3) generative procedures for efficiently building classes of new environments 4) high-fidelity audio rendering; 5) believable and realistic physical interactions for a wide variety of material types, including cloths, liquid, and deformable objects; 6) a range of "avatar" types that serve as embodiments of AI agents, with the option for user avatar customization; and 7) support for human interactions with VR devices. TDW also provides a rich API enabling multiple agents to interact within a simulation and return a range of sensor and physics data representing the state of the world. We present initial experiments enabled by the platform around emerging research directions in computer vision, machine learning, and cognitive science, including multi-modal physical scene understanding, multi-agent interactions, models that "learn like a child", and attention studies in humans and neural networks. The simulation platform will be made publicly available.