 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContour Integration Underlies Human-Like Vision
Apr 07, 2025



Despite the tremendous success of deep learning in computer vision, models still fall behind humans in generalizing to new input distributions. Existing benchmarks do not investigate the specific failure points of models by analyzing performance under many controlled conditions. Our study systematically dissects where and why models struggle with contour integration -- a hallmark of human vision -- by designing an experiment that tests object recognition under various levels of object fragmentation. Humans (n=50) perform at high accuracy, even with few object contours present. This is in contrast to models which exhibit substantially lower sensitivity to increasing object contours, with most of the over 1,000 models we tested barely performing above chance. Only at very large scales ($\sim5B$ training dataset size) do models begin to approach human performance. Importantly, humans exhibit an integration bias -- a preference towards recognizing objects made up of directional fragments over directionless fragments. We find that not only do models that share this property perform better at our task, but that this bias also increases with model training dataset size, and training models to exhibit contour integration leads to high shape bias. Taken together, our results suggest that contour integration is a hallmark of object vision that underlies object recognition performance, and may be a mechanism learned from data at scale.
Latent Noise Segmentation: How Neural Noise Leads to the Emergence of Segmentation and Grouping
Sep 28, 2023



Deep Neural Networks (DNNs) that achieve human-level performance in general tasks like object segmentation typically require supervised labels. In contrast, humans are able to perform these tasks effortlessly without supervision. To accomplish this, the human visual system makes use of perceptual grouping. Understanding how perceptual grouping arises in an unsupervised manner is critical for improving both models of the visual system, and computer vision models. In this work, we propose a counterintuitive approach to unsupervised perceptual grouping and segmentation: that they arise because of neural noise, rather than in spite of it. We (1) mathematically demonstrate that under realistic assumptions, neural noise can be used to separate objects from each other, and (2) show that adding noise in a DNN enables the network to segment images even though it was never trained on any segmentation labels. Interestingly, we find that (3) segmenting objects using noise results in segmentation performance that aligns with the perceptual grouping phenomena observed in humans. We introduce the Good Gestalt (GG) datasets -- six datasets designed to specifically test perceptual grouping, and show that our DNN models reproduce many important phenomena in human perception, such as illusory contours, closure, continuity, proximity, and occlusion. Finally, we (4) demonstrate the ecological plausibility of the method by analyzing the sensitivity of the DNN to different magnitudes of noise. We find that some model variants consistently succeed with remarkably low levels of neural noise ($\sigma<0.001$), and surprisingly, that segmenting this way requires as few as a handful of samples. Together, our results suggest a novel unsupervised segmentation method requiring few assumptions, a new explanation for the formation of perceptual grouping, and a potential benefit of neural noise in the visual system.
Frequency-Based Vulnerability Analysis of Deep Learning Models against Image Corruptions
Jun 12, 2023Deep learning models often face challenges when handling real-world image corruptions. In response, researchers have developed image corruption datasets to evaluate the performance of deep neural networks in handling such corruptions. However, these datasets have a significant limitation: they do not account for all corruptions encountered in real-life scenarios. To address this gap, we present MUFIA (Multiplicative Filter Attack), an algorithm designed to identify the specific types of corruptions that can cause models to fail. Our algorithm identifies the combination of image frequency components that render a model susceptible to misclassification while preserving the semantic similarity to the original image. We find that even state-of-the-art models trained to be robust against known common corruptions struggle against the low visibility-based corruptions crafted by MUFIA. This highlights the need for more comprehensive approaches to enhance model robustness against a wider range of real-world image corruptions.
A comment on Guo et al. [arXiv:2206.11228]
Aug 02, 2022In a recent article, Guo et al. [arXiv:2206.11228] report that adversarially trained neural representations in deep networks may already be as robust as corresponding primate IT neural representations. While we find the paper's primary experiment illuminating, we have doubts about the interpretation and phrasing of the results presented in the paper.
Empirical Advocacy of Bio-inspired Models for Robust Image Recognition
May 18, 2022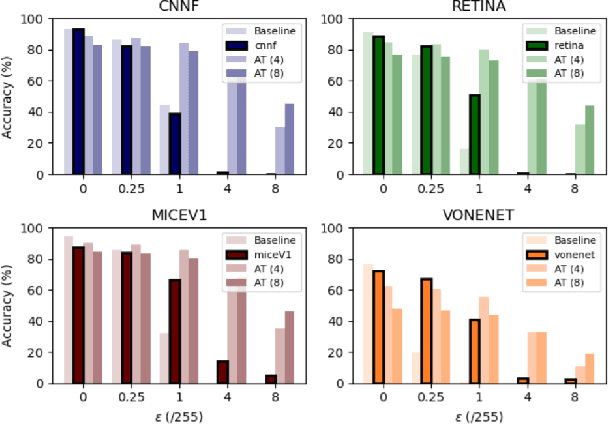
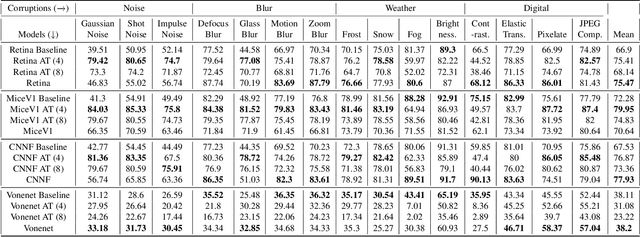
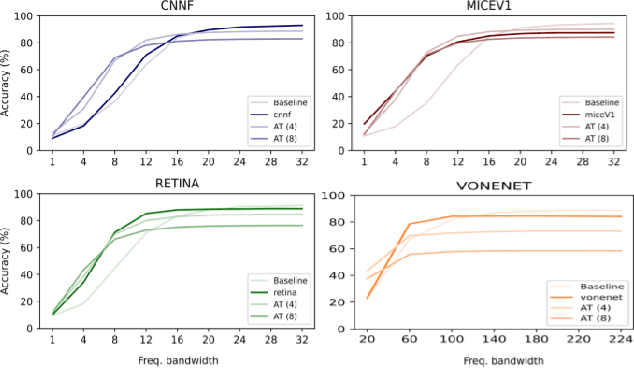
Deep convolutional neural networks (DCNNs) have revolutionized computer vision and are often advocated as good models of the human visual system. However, there are currently many shortcomings of DCNNs, which preclude them as a model of human vision. There are continuous attempts to use features of the human visual system to improve the robustness of neural networks to data perturbations. We provide a detailed analysis of such bio-inspired models and their properties. To this end, we benchmark the robustness of several bio-inspired models against their most comparable baseline DCNN models. We find that bio-inspired models tend to be adversarially robust without requiring any special data augmentation. Additionally, we find that bio-inspired models beat adversarially trained models in the presence of more real-world common corruptions. Interestingly, we also find that bio-inspired models tend to use both low and mid-frequency information, in contrast to other DCNN models. We find that this mix of frequency information makes them robust to both adversarial perturbations and common corruptions.