 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccuracy Boosters: Epoch-Driven Mixed-Mantissa Block Floating-Point for DNN Training
Nov 22, 2022



The unprecedented growth in DNN model complexity, size and the amount of training data have led to a commensurate increase in demand for computing and a search for minimal encoding. Recent research advocates Hybrid Block Floating-Point (HBFP) as a technique that minimizes silicon provisioning in accelerators by converting the majority of arithmetic operations in training to 8-bit fixed-point. In this paper, we perform a full-scale exploration of the HBFP design space including minimal mantissa encoding, varying block sizes, and mixed mantissa bit-width across layers and epochs. We propose Accuracy Boosters, an epoch-driven mixed-mantissa HBFP that uses 6-bit mantissa only in the last epoch and converts $99.7\%$ of all arithmetic operations in training to 4-bit mantissas. Accuracy Boosters enable reducing silicon provisioning for an HBFP training accelerator by $16.98\times$ as compared to FP32, while preserving or outperforming FP32 accuracy.
Modular Clinical Decision Support Networks (MoDN) -- Updatable, Interpretable, and Portable Predictions for Evolving Clinical Environments
Nov 12, 2022Data-driven Clinical Decision Support Systems (CDSS) have the potential to improve and standardise care with personalised probabilistic guidance. However, the size of data required necessitates collaborative learning from analogous CDSS's, which are often unsharable or imperfectly interoperable (IIO), meaning their feature sets are not perfectly overlapping. We propose Modular Clinical Decision Support Networks (MoDN) which allow flexible, privacy-preserving learning across IIO datasets, while providing interpretable, continuous predictive feedback to the clinician. MoDN is a novel decision tree composed of feature-specific neural network modules. It creates dynamic personalised representations of patients, and can make multiple predictions of diagnoses, updatable at each step of a consultation. The modular design allows it to compartmentalise training updates to specific features and collaboratively learn between IIO datasets without sharing any data.
FLamby: Datasets and Benchmarks for Cross-Silo Federated Learning in Realistic Healthcare Settings
Oct 10, 2022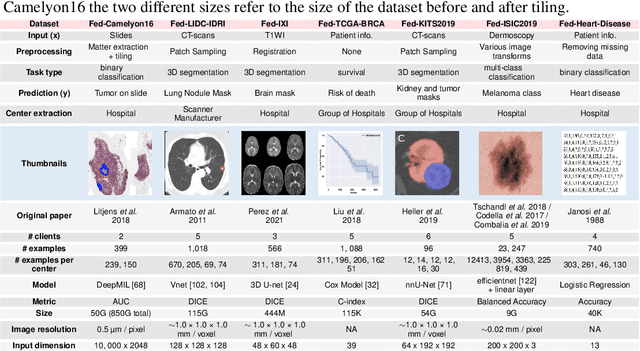
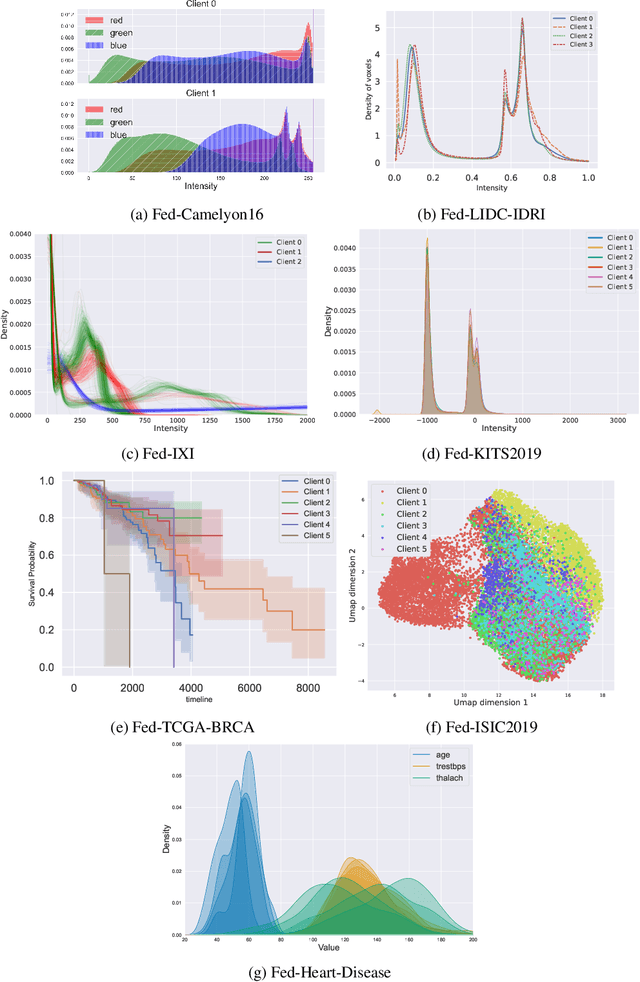
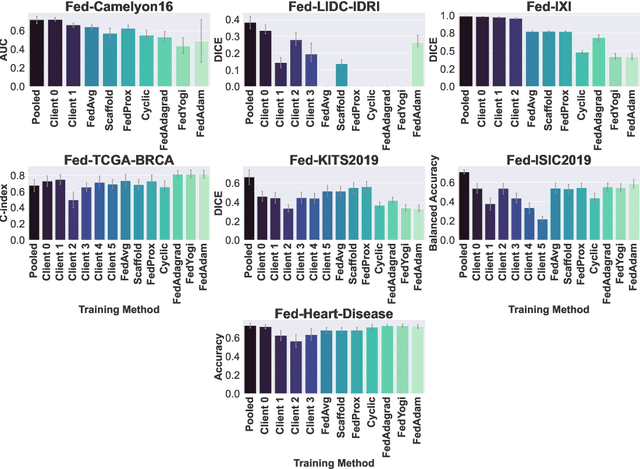

Federated Learning (FL) is a novel approach enabling several clients holding sensitive data to collaboratively train machine learning models, without centralizing data. The cross-silo FL setting corresponds to the case of few ($2$--$50$) reliable clients, each holding medium to large datasets, and is typically found in applications such as healthcare, finance, or industry. While previous works have proposed representative datasets for cross-device FL, few realistic healthcare cross-silo FL datasets exist, thereby slowing algorithmic research in this critical application. In this work, we propose a novel cross-silo dataset suite focused on healthcare, FLamby (Federated Learning AMple Benchmark of Your cross-silo strategies), to bridge the gap between theory and practice of cross-silo FL. FLamby encompasses 7 healthcare datasets with natural splits, covering multiple tasks, modalities, and data volumes, each accompanied with baseline training code. As an illustration, we additionally benchmark standard FL algorithms on all datasets. Our flexible and modular suite allows researchers to easily download datasets, reproduce results and re-use the different components for their research. FLamby is available at~\url{www.github.com/owkin/flamby}.
Sharper Convergence Guarantees for Asynchronous SGD for Distributed and Federated Learning
Jun 16, 2022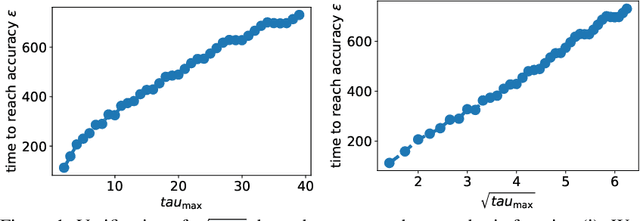
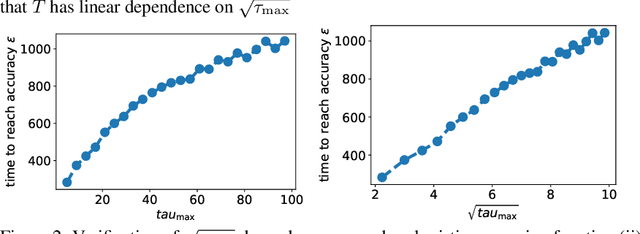
We study the asynchronous stochastic gradient descent algorithm for distributed training over $n$ workers which have varying computation and communication frequency over time. In this algorithm, workers compute stochastic gradients in parallel at their own pace and return those to the server without any synchronization. Existing convergence rates of this algorithm for non-convex smooth objectives depend on the maximum gradient delay $\tau_{\max}$ and show that an $\epsilon$-stationary point is reached after $\mathcal{O}\!\left(\sigma^2\epsilon^{-2}+ \tau_{\max}\epsilon^{-1}\right)$ iterations, where $\sigma$ denotes the variance of stochastic gradients. In this work (i) we obtain a tighter convergence rate of $\mathcal{O}\!\left(\sigma^2\epsilon^{-2}+ \sqrt{\tau_{\max}\tau_{avg}}\epsilon^{-1}\right)$ without any change in the algorithm where $\tau_{avg}$ is the average delay, which can be significantly smaller than $\tau_{\max}$. We also provide (ii) a simple delay-adaptive learning rate scheme, under which asynchronous SGD achieves a convergence rate of $\mathcal{O}\!\left(\sigma^2\epsilon^{-2}+ \tau_{avg}\epsilon^{-1}\right)$, and does not require any extra hyperparameter tuning nor extra communications. Our result allows to show for the first time that asynchronous SGD is always faster than mini-batch SGD. In addition, (iii) we consider the case of heterogeneous functions motivated by federated learning applications and improve the convergence rate by proving a weaker dependence on the maximum delay compared to prior works. In particular, we show that the heterogeneity term in convergence rate is only affected by the average delay within each worker.
Beyond spectral gap: The role of the topology in decentralized learning
Jun 07, 2022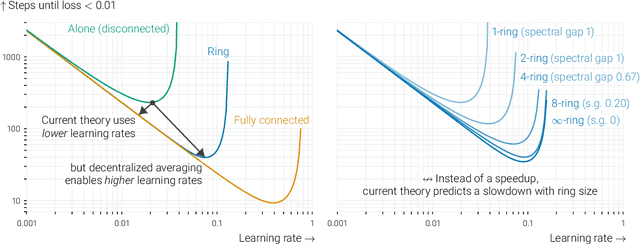
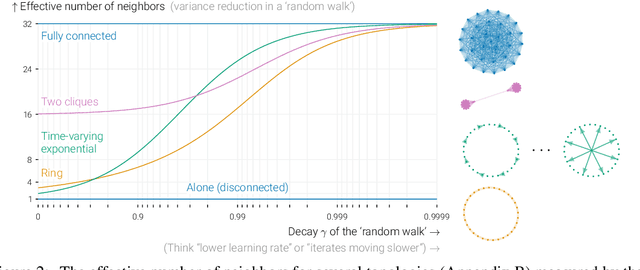

In data-parallel optimization of machine learning models, workers collaborate to improve their estimates of the model: more accurate gradients allow them to use larger learning rates and optimize faster. We consider the setting in which all workers sample from the same dataset, and communicate over a sparse graph (decentralized). In this setting, current theory fails to capture important aspects of real-world behavior. First, the 'spectral gap' of the communication graph is not predictive of its empirical performance in (deep) learning. Second, current theory does not explain that collaboration enables larger learning rates than training alone. In fact, it prescribes smaller learning rates, which further decrease as graphs become larger, failing to explain convergence in infinite graphs. This paper aims to paint an accurate picture of sparsely-connected distributed optimization when workers share the same data distribution. We quantify how the graph topology influences convergence in a quadratic toy problem and provide theoretical results for general smooth and (strongly) convex objectives. Our theory matches empirical observations in deep learning, and accurately describes the relative merits of different graph topologies.
On Avoiding Local Minima Using Gradient Descent With Large Learning Rates
May 30, 2022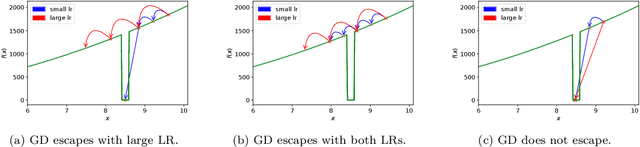
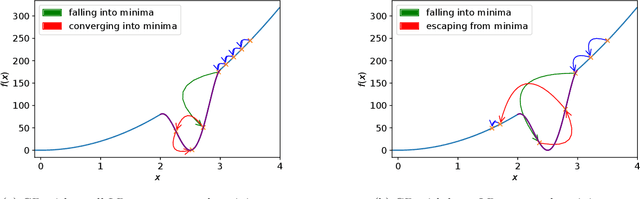
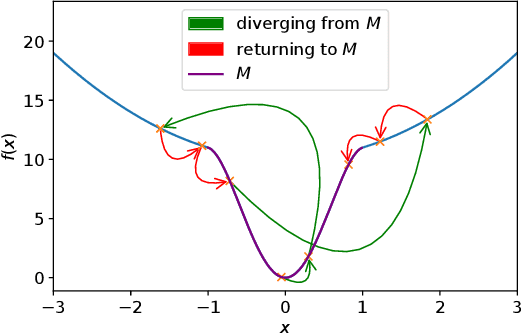
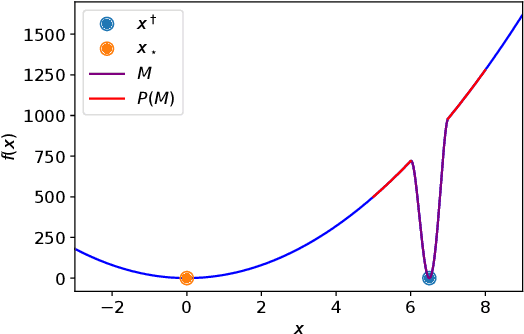
It has been widely observed in training of neural networks that when applying gradient descent (GD), a large step size is essential for obtaining superior models. However, the effect of large step sizes on the success of GD is not well understood theoretically. We argue that a complete understanding of the mechanics leading to GD's success may indeed require considering effects of using a large step size. To support this claim, we prove on a certain class of functions that GD with large step size follows a different trajectory than GD with a small step size, leading to convergence to the global minimum. We also demonstrate the difference in trajectories for small and large learning rates when GD is applied on a neural network, observing effects of an escape from a local minimum with a large step size, which shows this behavior is indeed relevant in practice. Finally, through a novel set of experiments, we show even though stochastic noise is beneficial, it is not enough to explain success of SGD and a large learning rate is essential for obtaining the best performance even in stochastic settings.
SKILL: Structured Knowledge Infusion for Large Language Models
May 17, 2022
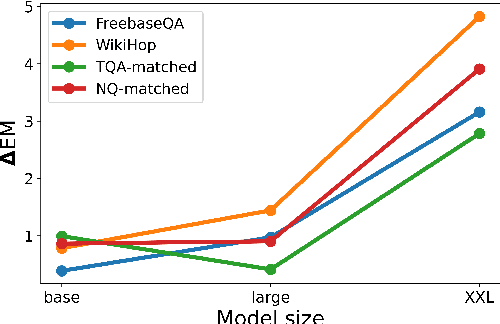
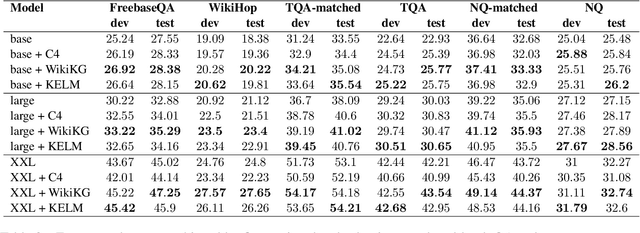
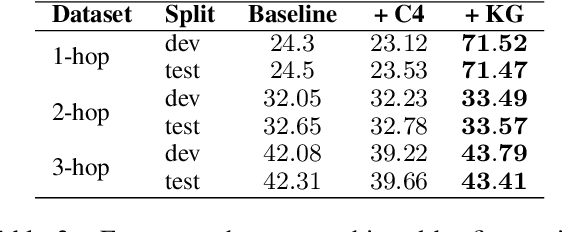
Large language models (LLMs) have demonstrated human-level performance on a vast spectrum of natural language tasks. However, it is largely unexplored whether they can better internalize knowledge from a structured data, such as a knowledge graph, or from text. In this work, we propose a method to infuse structured knowledge into LLMs, by directly training T5 models on factual triples of knowledge graphs (KGs). We show that models pre-trained on Wikidata KG with our method outperform the T5 baselines on FreebaseQA and WikiHop, as well as the Wikidata-answerable subset of TriviaQA and NaturalQuestions. The models pre-trained on factual triples compare competitively with the ones on natural language sentences that contain the same knowledge. Trained on a smaller size KG, WikiMovies, we saw 3x improvement of exact match score on MetaQA task compared to T5 baseline. The proposed method has an advantage that no alignment between the knowledge graph and text corpus is required in curating training data. This makes our method particularly useful when working with industry-scale knowledge graphs.
Data-heterogeneity-aware Mixing for Decentralized Learning
Apr 13, 2022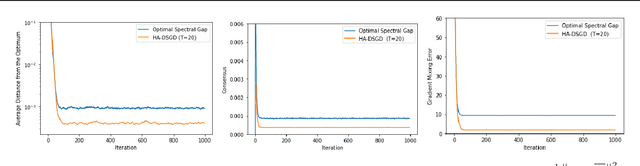
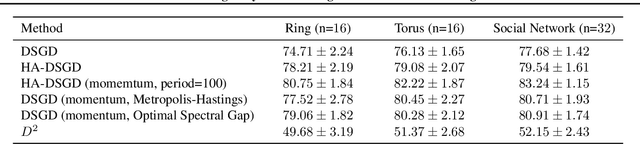
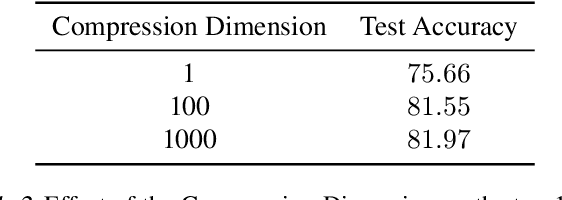
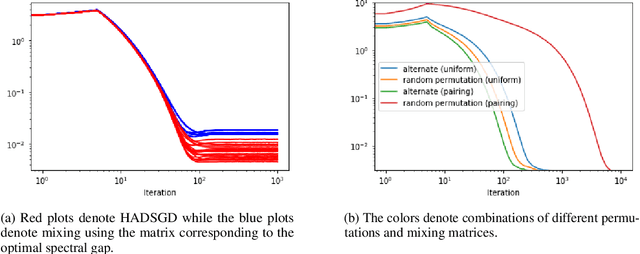
Decentralized learning provides an effective framework to train machine learning models with data distributed over arbitrary communication graphs. However, most existing approaches toward decentralized learning disregard the interaction between data heterogeneity and graph topology. In this paper, we characterize the dependence of convergence on the relationship between the mixing weights of the graph and the data heterogeneity across nodes. We propose a metric that quantifies the ability of a graph to mix the current gradients. We further prove that the metric controls the convergence rate, particularly in settings where the heterogeneity across nodes dominates the stochasticity between updates for a given node. Motivated by our analysis, we propose an approach that periodically and efficiently optimizes the metric using standard convex constrained optimization and sketching techniques. Through comprehensive experiments on standard computer vision and NLP benchmarks, we show that our approach leads to improvement in test performance for a wide range of tasks.
Improving Generalization via Uncertainty Driven Perturbations
Feb 28, 2022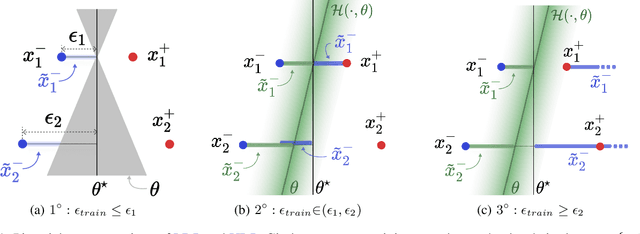
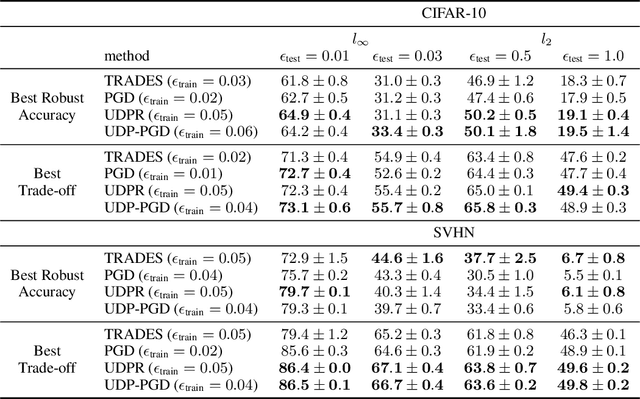
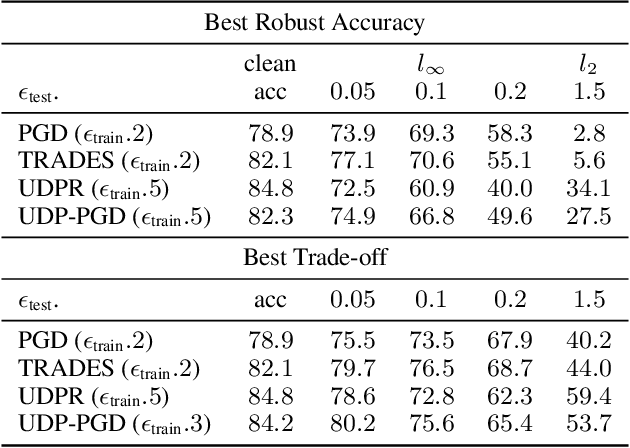
Recently Shah et al., 2020 pointed out the pitfalls of the simplicity bias - the tendency of gradient-based algorithms to learn simple models - which include the model's high sensitivity to small input perturbations, as well as sub-optimal margins. In particular, while Stochastic Gradient Descent yields max-margin boundary on linear models, such guarantee does not extend to non-linear models. To mitigate the simplicity bias, we consider uncertainty-driven perturbations (UDP) of the training data points, obtained iteratively by following the direction that maximizes the model's estimated uncertainty. The uncertainty estimate does not rely on the input's label and it is highest at the decision boundary, and - unlike loss-driven perturbations - it allows for using a larger range of values for the perturbation magnitude. Furthermore, as real-world datasets have non-isotropic distances between data points of different classes, the above property is particularly appealing for increasing the margin of the decision boundary, which in turn improves the model's generalization. We show that UDP is guaranteed to achieve the maximum margin decision boundary on linear models and that it notably increases it on challenging simulated datasets. For nonlinear models, we show empirically that UDP reduces the simplicity bias and learns more exhaustive features. Interestingly, it also achieves competitive loss-based robustness and generalization trade-off on several datasets.
Agree to Disagree: Diversity through Disagreement for Better Transferability
Feb 09, 2022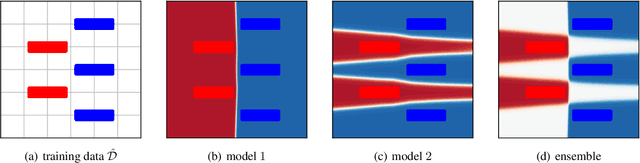

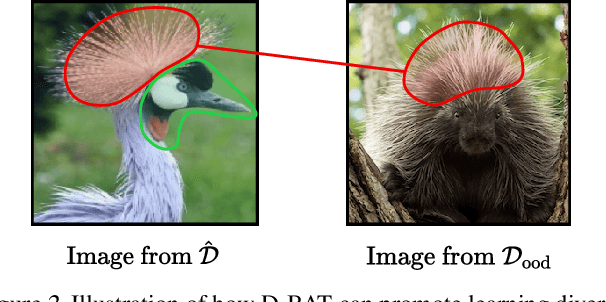

Gradient-based learning algorithms have an implicit simplicity bias which in effect can limit the diversity of predictors being sampled by the learning procedure. This behavior can hinder the transferability of trained models by (i) favoring the learning of simpler but spurious features -- present in the training data but absent from the test data -- and (ii) by only leveraging a small subset of predictive features. Such an effect is especially magnified when the test distribution does not exactly match the train distribution -- referred to as the Out of Distribution (OOD) generalization problem. However, given only the training data, it is not always possible to apriori assess if a given feature is spurious or transferable. Instead, we advocate for learning an ensemble of models which capture a diverse set of predictive features. Towards this, we propose a new algorithm D-BAT (Diversity-By-disAgreement Training), which enforces agreement among the models on the training data, but disagreement on the OOD data. We show how D-BAT naturally emerges from the notion of generalized discrepancy, as well as demonstrate in multiple experiments how the proposed method can mitigate shortcut-learning, enhance uncertainty and OOD detection, as well as improve transferability.