 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of projected stochastic natural gradient variational inference for various step size and sample or batch size schedules
Apr 01, 2026Stochastic natural gradient variational inference (NGVI) is a popular and efficient algorithm for Bayesian inference. Despite empirical success, the convergence of this method is still not fully understood. In this work, we define and study a projected stochastic NGVI when variational distributions form an exponential family. Stochasticity arises when either gradients are intractable expectations or large sums. We prove new non-asymptotic convergence results for combinations of constant or decreasing step sizes and constant or increasing sample/batch sizes. When all hyperparameters are fixed, NGVI is shown to converge geometrically to a neighborhood of the optimum, while we establish convergence to the optimum with rates of the form $\mathcal{O}\left(\frac{1}{T^ρ} \right)$, possibly with $ρ\geq 1$, for all other combinations of step size and sample/batch size schedules. These rates apply when the target posterior distribution is close in some sense to the considered exponential family. Our theoretical results extend existing NGVI and stochastic optimization results and provide more flexibility to adjust, in a principled way, step sizes and sample/batch sizes in order to meet speed, resources, or accuracy constraints.
From Inexact Gradients to Byzantine Robustness: Acceleration and Optimization under Similarity
Feb 03, 2026Standard federated learning algorithms are vulnerable to adversarial nodes, a.k.a. Byzantine failures. To solve this issue, robust distributed learning algorithms have been developed, which typically replace parameter averaging by robust aggregations. While generic conditions on these aggregations exist to guarantee the convergence of (Stochastic) Gradient Descent (SGD), the analyses remain rather ad-hoc. This hinders the development of more complex robust algorithms, such as accelerated ones. In this work, we show that Byzantine-robust distributed optimization can, under standard generic assumptions, be cast as a general optimization with inexact gradient oracles (with both additive and multiplicative error terms), an active field of research. This allows for instance to directly show that GD on top of standard robust aggregation procedures obtains optimal asymptotic error in the Byzantine setting. Going further, we propose two optimization schemes to speed up the convergence. The first one is a Nesterov-type accelerated scheme whose proof directly derives from accelerated inexact gradient results applied to our formulation. The second one hinges on Optimization under Similarity, in which the server leverages an auxiliary loss function that approximates the global loss. Both approaches allow to drastically reduce the communication complexity compared to previous methods, as we show theoretically and empirically.
Exponential Moving Average of Weights in Deep Learning: Dynamics and Benefits
Nov 27, 2024



Weight averaging of Stochastic Gradient Descent (SGD) iterates is a popular method for training deep learning models. While it is often used as part of complex training pipelines to improve generalization or serve as a `teacher' model, weight averaging lacks proper evaluation on its own. In this work, we present a systematic study of the Exponential Moving Average (EMA) of weights. We first explore the training dynamics of EMA, give guidelines for hyperparameter tuning, and highlight its good early performance, partly explaining its success as a teacher. We also observe that EMA requires less learning rate decay compared to SGD since averaging naturally reduces noise, introducing a form of implicit regularization. Through extensive experiments, we show that EMA solutions differ from last-iterate solutions. EMA models not only generalize better but also exhibit improved i) robustness to noisy labels, ii) prediction consistency, iii) calibration and iv) transfer learning. Therefore, we suggest that an EMA of weights is a simple yet effective plug-in to improve the performance of deep learning models.
* 27 pages, 9 figures. Accepted at TMLR, April 2024
Achieving Optimal Breakdown for Byzantine Robust Gossip
Oct 14, 2024



Distributed approaches have many computational benefits, but they are vulnerable to attacks from a subset of devices transmitting incorrect information. This paper investigates Byzantine-resilient algorithms in a decentralized setting, where devices communicate directly with one another. We investigate the notion of breakdown point, and show an upper bound on the number of adversaries that decentralized algorithms can tolerate. We introduce $\mathrm{CG}^+$, an algorithm at the intersection of $\mathrm{ClippedGossip}$ and $\mathrm{NNA}$, two popular approaches for robust decentralized learning. $\mathrm{CG}^+$ meets our upper bound, and thus obtains optimal robustness guarantees, whereas neither of the existing two does. We provide experimental evidence for this gap by presenting an attack tailored to sparse graphs which breaks $\mathrm{NNA}$ but against which $\mathrm{CG}^+$ is robust.
Byzantine-Robust Gossip: Insights from a Dual Approach
May 06, 2024



Distributed approaches have many computational benefits, but they are vulnerable to attacks from a subset of devices transmitting incorrect information. This paper investigates Byzantine-resilient algorithms in a decentralized setting, where devices communicate directly with one another. We leverage the so-called dual approach to design a general robust decentralized optimization method. We provide both global and local clipping rules in the special case of average consensus, with tight convergence guarantees. These clipping rules are practical, and yield results that finely characterize the impact of Byzantine nodes, highlighting for instance a qualitative difference in convergence between global and local clipping thresholds. Lastly, we demonstrate that they can serve as a basis for designing efficient attacks.
The Relative Gaussian Mechanism and its Application to Private Gradient Descent
Aug 29, 2023
The Gaussian Mechanism (GM), which consists in adding Gaussian noise to a vector-valued query before releasing it, is a standard privacy protection mechanism. In particular, given that the query respects some L2 sensitivity property (the L2 distance between outputs on any two neighboring inputs is bounded), GM guarantees R\'enyi Differential Privacy (RDP). Unfortunately, precisely bounding the L2 sensitivity can be hard, thus leading to loose privacy bounds. In this work, we consider a Relative L2 sensitivity assumption, in which the bound on the distance between two query outputs may also depend on their norm. Leveraging this assumption, we introduce the Relative Gaussian Mechanism (RGM), in which the variance of the noise depends on the norm of the output. We prove tight bounds on the RDP parameters under relative L2 sensitivity, and characterize the privacy loss incurred by using output-dependent noise. In particular, we show that RGM naturally adapts to a latent variable that would control the norm of the output. Finally, we instantiate our framework to show tight guarantees for Private Gradient Descent, a problem that naturally fits our relative L2 sensitivity assumption.
Revisiting Gradient Clipping: Stochastic bias and tight convergence guarantees
May 02, 2023Gradient clipping is a popular modification to standard (stochastic) gradient descent, at every iteration limiting the gradient norm to a certain value $c >0$. It is widely used for example for stabilizing the training of deep learning models (Goodfellow et al., 2016), or for enforcing differential privacy (Abadi et al., 2016). Despite popularity and simplicity of the clipping mechanism, its convergence guarantees often require specific values of $c$ and strong noise assumptions. In this paper, we give convergence guarantees that show precise dependence on arbitrary clipping thresholds $c$ and show that our guarantees are tight with both deterministic and stochastic gradients. In particular, we show that (i) for deterministic gradient descent, the clipping threshold only affects the higher-order terms of convergence, (ii) in the stochastic setting convergence to the true optimum cannot be guaranteed under the standard noise assumption, even under arbitrary small step-sizes. We give matching upper and lower bounds for convergence of the gradient norm when running clipped SGD, and illustrate these results with experiments.
Beyond spectral gap : The role of the topology in decentralized learning
Jan 05, 2023In data-parallel optimization of machine learning models, workers collaborate to improve their estimates of the model: more accurate gradients allow them to use larger learning rates and optimize faster. In the decentralized setting, in which workers communicate over a sparse graph, current theory fails to capture important aspects of real-world behavior. First, the `spectral gap' of the communication graph is not predictive of its empirical performance in (deep) learning. Second, current theory does not explain that collaboration enables larger learning rates than training alone. In fact, it prescribes smaller learning rates, which further decrease as graphs become larger, failing to explain convergence dynamics in infinite graphs. This paper aims to paint an accurate picture of sparsely-connected distributed optimization. We quantify how the graph topology influences convergence in a quadratic toy problem and provide theoretical results for general smooth and (strongly) convex objectives. Our theory matches empirical observations in deep learning, and accurately describes the relative merits of different graph topologies. This paper is an extension of the conference paper by Vogels et. al. (2022). Code: https://github.com/epfml/topology-in-decentralized-learning.
Beyond spectral gap: The role of the topology in decentralized learning
Jun 07, 2022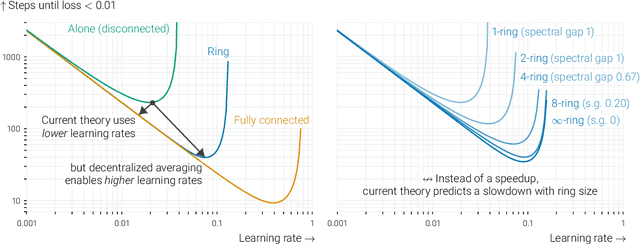
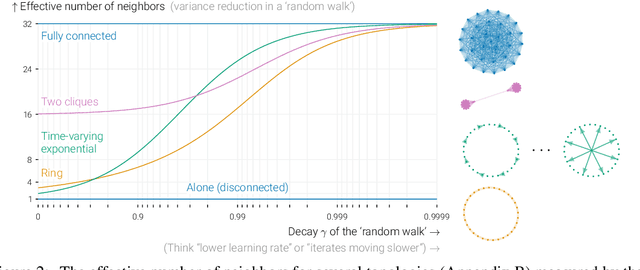

In data-parallel optimization of machine learning models, workers collaborate to improve their estimates of the model: more accurate gradients allow them to use larger learning rates and optimize faster. We consider the setting in which all workers sample from the same dataset, and communicate over a sparse graph (decentralized). In this setting, current theory fails to capture important aspects of real-world behavior. First, the 'spectral gap' of the communication graph is not predictive of its empirical performance in (deep) learning. Second, current theory does not explain that collaboration enables larger learning rates than training alone. In fact, it prescribes smaller learning rates, which further decrease as graphs become larger, failing to explain convergence in infinite graphs. This paper aims to paint an accurate picture of sparsely-connected distributed optimization when workers share the same data distribution. We quantify how the graph topology influences convergence in a quadratic toy problem and provide theoretical results for general smooth and (strongly) convex objectives. Our theory matches empirical observations in deep learning, and accurately describes the relative merits of different graph topologies.
A Continuized View on Nesterov Acceleration for Stochastic Gradient Descent and Randomized Gossip
Jun 10, 2021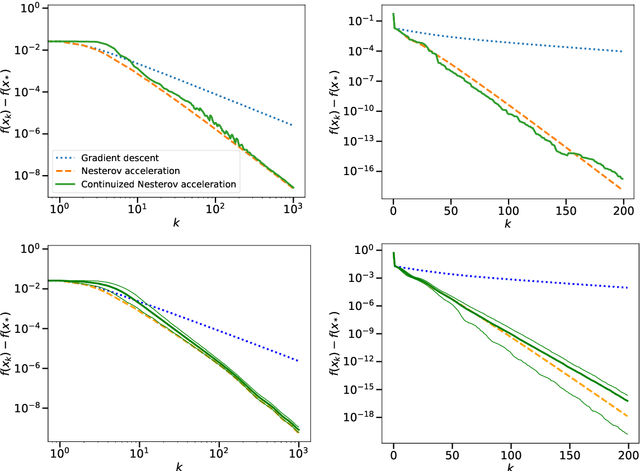
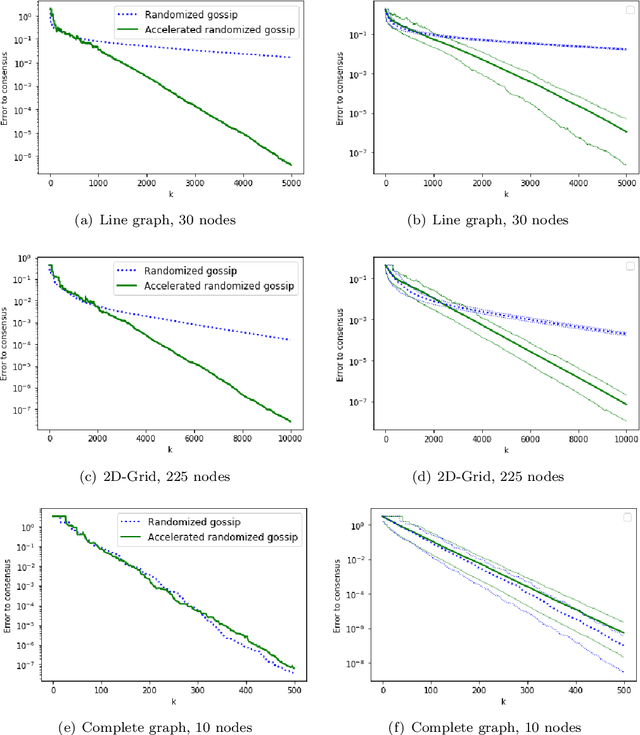
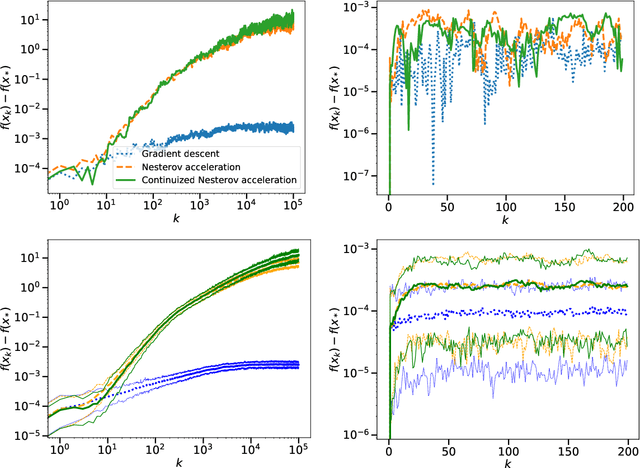
We introduce the continuized Nesterov acceleration, a close variant of Nesterov acceleration whose variables are indexed by a continuous time parameter. The two variables continuously mix following a linear ordinary differential equation and take gradient steps at random times. This continuized variant benefits from the best of the continuous and the discrete frameworks: as a continuous process, one can use differential calculus to analyze convergence and obtain analytical expressions for the parameters; and a discretization of the continuized process can be computed exactly with convergence rates similar to those of Nesterov original acceleration. We show that the discretization has the same structure as Nesterov acceleration, but with random parameters. We provide continuized Nesterov acceleration under deterministic as well as stochastic gradients, with either additive or multiplicative noise. Finally, using our continuized framework and expressing the gossip averaging problem as the stochastic minimization of a certain energy function, we provide the first rigorous acceleration of asynchronous gossip algorithms.