 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs
Mar 30, 2024



We introduce QuaRot, a new Quantization scheme based on Rotations, which is able to quantize LLMs end-to-end, including all weights, activations, and KV cache in 4 bits. QuaRot rotates LLMs in a way that removes outliers from the hidden state without changing the output, making quantization easier. This computational invariance is applied to the hidden state (residual) of the LLM, as well as to the activations of the feed-forward components, aspects of the attention mechanism and to the KV cache. The result is a quantized model where all matrix multiplications are performed in 4-bits, without any channels identified for retention in higher precision. Our quantized LLaMa2-70B model has losses of at most 0.29 WikiText-2 perplexity and retains 99% of the zero-shot performance. Code is available at: https://github.com/spcl/QuaRot.
DenseFormer: Enhancing Information Flow in Transformers via Depth Weighted Averaging
Feb 04, 2024



The transformer architecture from Vaswani et al. (2017) is now ubiquitous across application domains, from natural language processing to speech processing and image understanding. We propose DenseFormer, a simple modification to the standard architecture that improves the perplexity of the model without increasing its size -- adding a few thousand parameters for large-scale models in the 100B parameters range. Our approach relies on an additional averaging step after each transformer block, which computes a weighted average of current and past representations -- we refer to this operation as Depth-Weighted-Average (DWA). The learned DWA weights exhibit coherent patterns of information flow, revealing the strong and structured reuse of activations from distant layers. Experiments demonstrate that DenseFormer is more data efficient, reaching the same perplexity of much deeper transformer models, and that for the same perplexity, these new models outperform transformer baselines in terms of memory efficiency and inference time.
Social Learning: Towards Collaborative Learning with Large Language Models
Dec 18, 2023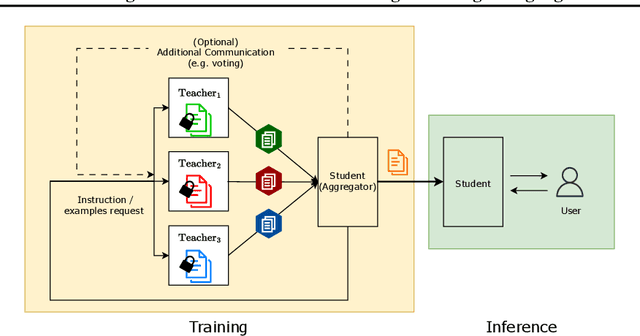
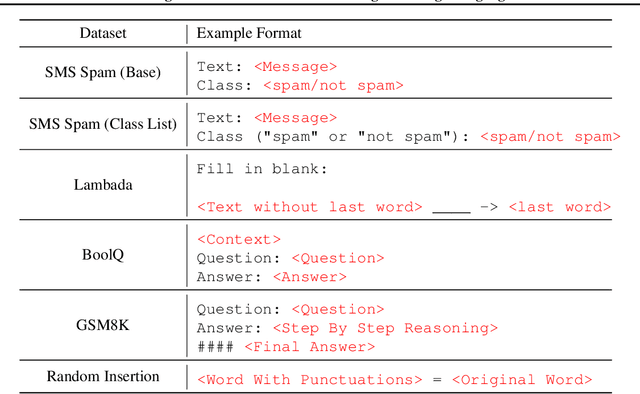

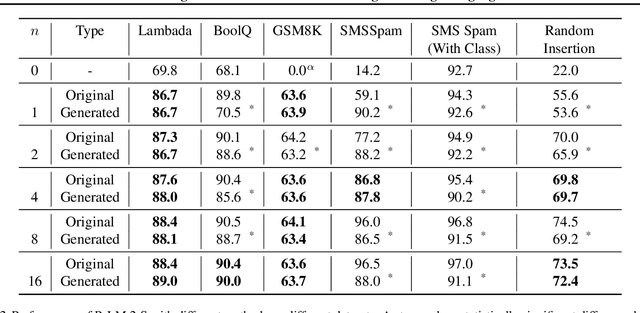
We introduce the framework of "social learning" in the context of large language models (LLMs), whereby models share knowledge with each other in a privacy-aware manner using natural language. We present and evaluate two approaches for knowledge transfer between LLMs. In the first scenario, we allow the model to generate abstract prompts aiming to teach the task. In our second approach, models transfer knowledge by generating synthetic examples. We evaluate these methods across diverse datasets and quantify memorization as a proxy for privacy loss. These techniques inspired by social learning yield promising results with low memorization of the original data. In particular, we show that performance using these methods is comparable to results with the use of original labels and prompts. Our work demonstrates the viability of social learning for LLMs, establishes baseline approaches and highlights several unexplored areas for future work.
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
Nov 27, 2023



Large language models (LLMs) can potentially democratize access to medical knowledge. While many efforts have been made to harness and improve LLMs' medical knowledge and reasoning capacities, the resulting models are either closed-source (e.g., PaLM, GPT-4) or limited in scale (<= 13B parameters), which restricts their abilities. In this work, we improve access to large-scale medical LLMs by releasing MEDITRON: a suite of open-source LLMs with 7B and 70B parameters adapted to the medical domain. MEDITRON builds on Llama-2 (through our adaptation of Nvidia's Megatron-LM distributed trainer), and extends pretraining on a comprehensively curated medical corpus, including selected PubMed articles, abstracts, and internationally-recognized medical guidelines. Evaluations using four major medical benchmarks show significant performance gains over several state-of-the-art baselines before and after task-specific finetuning. Overall, MEDITRON achieves a 6% absolute performance gain over the best public baseline in its parameter class and 3% over the strongest baseline we finetuned from Llama-2. Compared to closed-source LLMs, MEDITRON-70B outperforms GPT-3.5 and Med-PaLM and is within 5% of GPT-4 and 10% of Med-PaLM-2. We release our code for curating the medical pretraining corpus and the MEDITRON model weights to drive open-source development of more capable medical LLMs.
CoTFormer: More Tokens With Attention Make Up For Less Depth
Oct 16, 2023



The race to continually develop ever larger and deeper foundational models is underway. However, techniques like the Chain-of-Thought (CoT) method continue to play a pivotal role in achieving optimal downstream performance. In this work, we establish an approximate parallel between using chain-of-thought and employing a deeper transformer. Building on this insight, we introduce CoTFormer, a transformer variant that employs an implicit CoT-like mechanism to achieve capacity comparable to a deeper model. Our empirical findings demonstrate the effectiveness of CoTFormers, as they significantly outperform larger standard transformers.
Landmark Attention: Random-Access Infinite Context Length for Transformers
May 25, 2023



While transformers have shown remarkable success in natural language processing, their attention mechanism's large memory requirements have limited their ability to handle longer contexts. Prior approaches, such as recurrent memory or retrieval-based augmentation, have either compromised the random-access flexibility of attention (i.e., the capability to select any token in the entire context) or relied on separate mechanisms for relevant context retrieval, which may not be compatible with the model's attention. In this paper, we present a novel approach that allows access to the complete context while retaining random-access flexibility, closely resembling running attention on the entire context. Our method uses a landmark token to represent each block of the input and trains the attention to use it for selecting relevant blocks, enabling retrieval of blocks directly through the attention mechanism instead of by relying on a separate mechanism. Our approach seamlessly integrates with specialized data structures and the system's memory hierarchy, enabling processing of arbitrarily long context lengths. We demonstrate that our method can obtain comparable performance with Transformer-XL while significantly reducing the number of retrieved tokens in each step. Finally, we show that fine-tuning LLaMA 7B with our method successfully extends its context length capacity up to 32k tokens, allowing for inference at the context lengths of GPT-4.
Learning Translation Quality Evaluation on Low Resource Languages from Large Language Models
Feb 07, 2023



Learned metrics such as BLEURT have in recent years become widely employed to evaluate the quality of machine translation systems. Training such metrics requires data which can be expensive and difficult to acquire, particularly for lower-resource languages. We show how knowledge can be distilled from Large Language Models (LLMs) to improve upon such learned metrics without requiring human annotators, by creating synthetic datasets which can be mixed into existing datasets, requiring only a corpus of text in the target language. We show that the performance of a BLEURT-like model on lower resource languages can be improved in this way.
On Avoiding Local Minima Using Gradient Descent With Large Learning Rates
May 30, 2022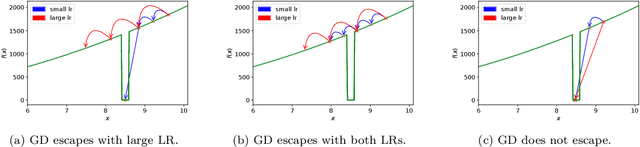
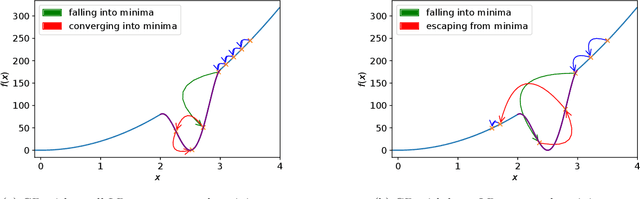
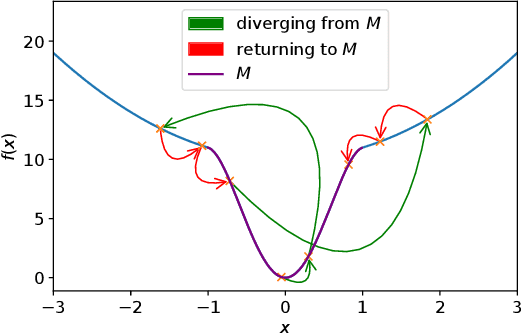
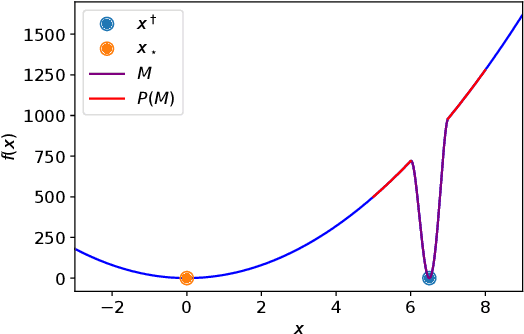
It has been widely observed in training of neural networks that when applying gradient descent (GD), a large step size is essential for obtaining superior models. However, the effect of large step sizes on the success of GD is not well understood theoretically. We argue that a complete understanding of the mechanics leading to GD's success may indeed require considering effects of using a large step size. To support this claim, we prove on a certain class of functions that GD with large step size follows a different trajectory than GD with a small step size, leading to convergence to the global minimum. We also demonstrate the difference in trajectories for small and large learning rates when GD is applied on a neural network, observing effects of an escape from a local minimum with a large step size, which shows this behavior is indeed relevant in practice. Finally, through a novel set of experiments, we show even though stochastic noise is beneficial, it is not enough to explain success of SGD and a large learning rate is essential for obtaining the best performance even in stochastic settings.
Characterizing & Finding Good Data Orderings for Fast Convergence of Sequential Gradient Methods
Feb 03, 2022
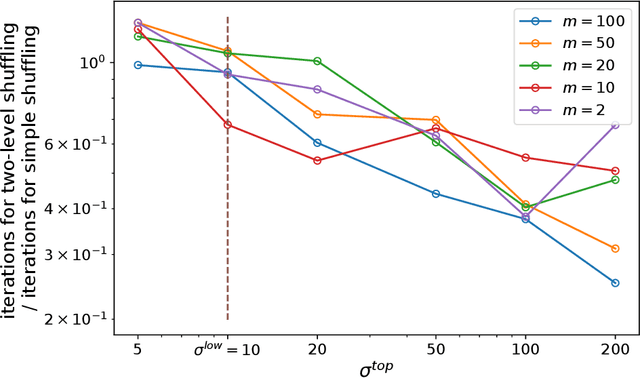
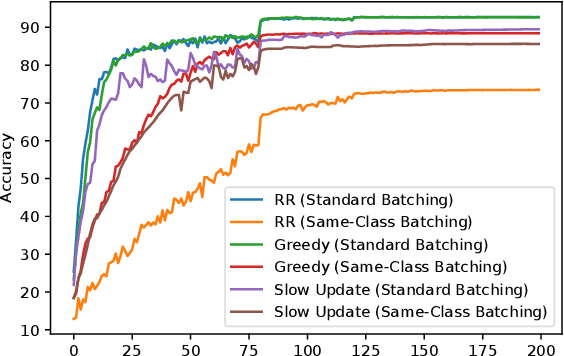
While SGD, which samples from the data with replacement is widely studied in theory, a variant called Random Reshuffling (RR) is more common in practice. RR iterates through random permutations of the dataset and has been shown to converge faster than SGD. When the order is chosen deterministically, a variant called incremental gradient descent (IG), the existing convergence bounds show improvement over SGD but are worse than RR. However, these bounds do not differentiate between a good and a bad ordering and hold for the worst choice of order. Meanwhile, in some cases, choosing the right order when using IG can lead to convergence faster than RR. In this work, we quantify the effect of order on convergence speed, obtaining convergence bounds based on the chosen sequence of permutations while also recovering previous results for RR. In addition, we show benefits of using structured shuffling when various levels of abstractions (e.g. tasks, classes, augmentations, etc.) exists in the dataset in theory and in practice. Finally, relying on our measure, we develop a greedy algorithm for choosing good orders during training, achieving superior performance (by more than 14 percent in accuracy) over RR.
Simultaneous Training of Partially Masked Neural Networks
Jun 16, 2021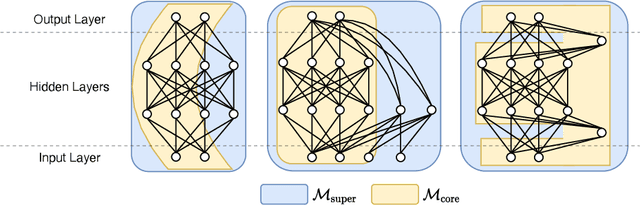


For deploying deep learning models to lower end devices, it is necessary to train less resource-demanding variants of state-of-the-art architectures. This does not eliminate the need for more expensive models as they have a higher performance. In order to avoid training two separate models, we show that it is possible to train neural networks in such a way that a predefined 'core' subnetwork can be split-off from the trained full network with remarkable good performance. We extend on prior methods that focused only on core networks of smaller width, while we focus on supporting arbitrary core network architectures. Our proposed training scheme switches consecutively between optimizing only the core part of the network and the full one. The accuracy of the full model remains comparable, while the core network achieves better performance than when it is trained in isolation. In particular, we show that training a Transformer with a low-rank core gives a low-rank model with superior performance than when training the low-rank model alone. We analyze our training scheme theoretically, and show its convergence under assumptions that are either standard or practically justified. Moreover, we show that the developed theoretical framework allows analyzing many other partial training schemes for neural networks.