 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Fusion via Optimal Transport
Oct 12, 2019
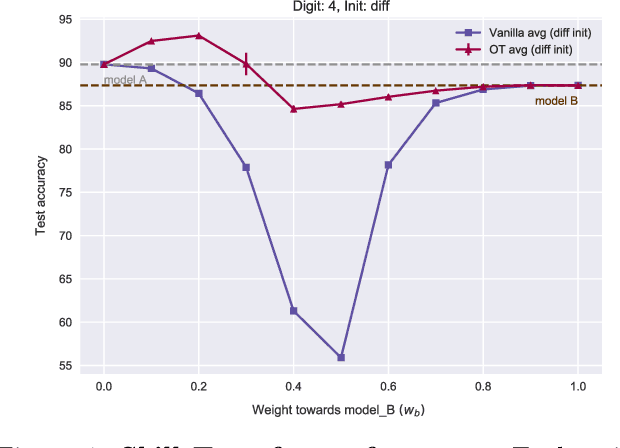

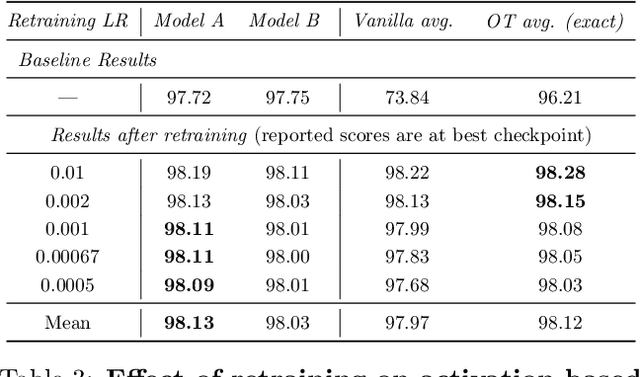
Combining different models is a widely used paradigm in machine learning applications. While the most common approach is to form an ensemble of models and average their individual predictions, this approach is often rendered infeasible by given resource constraints in terms of memory and computation, which grow linearly with the number of models. We present a layer-wise model fusion procedure for neural networks that utilizes optimal transport to (soft-) align neurons across the models before averaging their associated parameters. We discuss two main algorithms for fusing neural networks in this "one-shot" manner, without requiring any retraining. Finally, we illustrate on CIFAR10 and MNIST how this significantly outperforms vanilla averaging on convolutional networks, such as VGG11 and multi-layer perceptrons, and for transfer tasks even surpasses the performance of both original models.
Decentralized Deep Learning with Arbitrary Communication Compression
Jul 22, 2019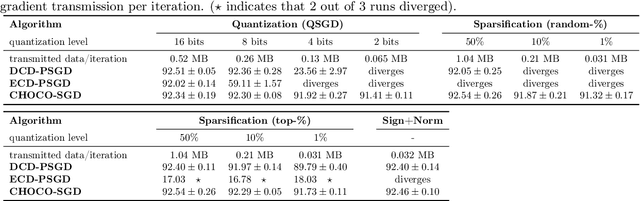
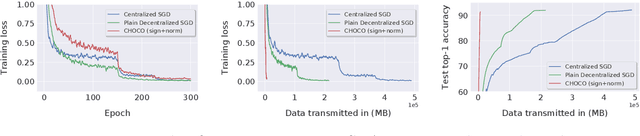
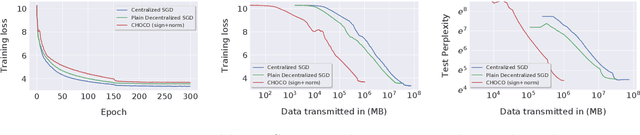

Decentralized training of deep learning models is a key element for enabling data privacy and on-device learning over networks, as well as for efficient scaling to large compute clusters. As current approaches suffer from limited bandwidth of the network, we propose the use of communication compression in the decentralized training context. We show that Choco-SGD $-$ recently introduced and analyzed for strongly-convex objectives only $-$ converges under arbitrary high compression ratio on general non-convex functions at the rate $O\bigl(1/\sqrt{nT}\bigr)$ where $T$ denotes the number of iterations and $n$ the number of workers. The algorithm achieves linear speedup in the number of workers and supports higher compression than previous state-of-the art methods. We demonstrate the practical performance of the algorithm in two key scenarios: the training of deep learning models (i) over distributed user devices, connected by a social network and (ii) in a datacenter (outperforming all-reduce time-wise).
Correlating Twitter Language with Community-Level Health Outcomes
Jun 24, 2019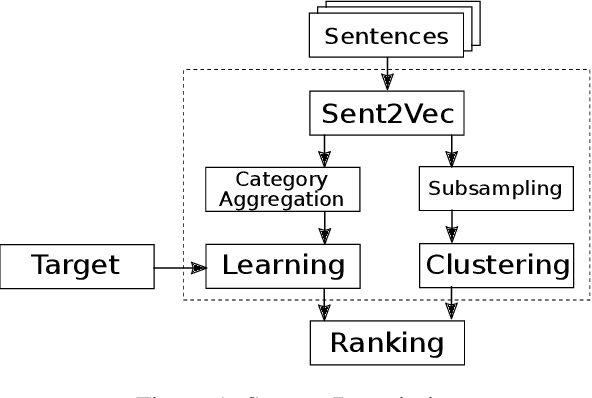
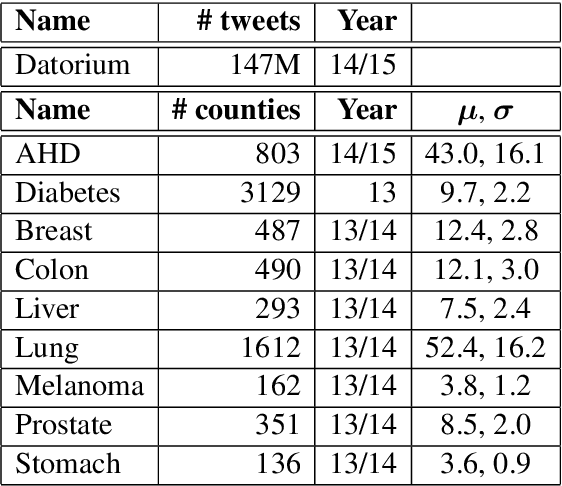
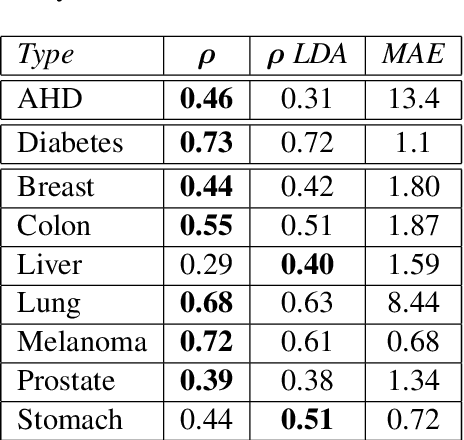
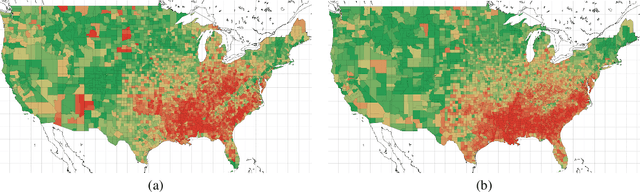
We study how language on social media is linked to diseases such as atherosclerotic heart disease (AHD), diabetes and various types of cancer. Our proposed model leverages state-of-the-art sentence embeddings, followed by a regression model and clustering, without the need of additional labelled data. It allows to predict community-level medical outcomes from language, and thereby potentially translate these to the individual level. The method is applicable to a wide range of target variables and allows us to discover known and potentially novel correlations of medical outcomes with life-style aspects and other socioeconomic risk factors.
PowerSGD: Practical Low-Rank Gradient Compression for Distributed Optimization
May 31, 2019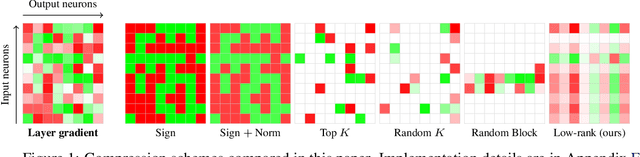

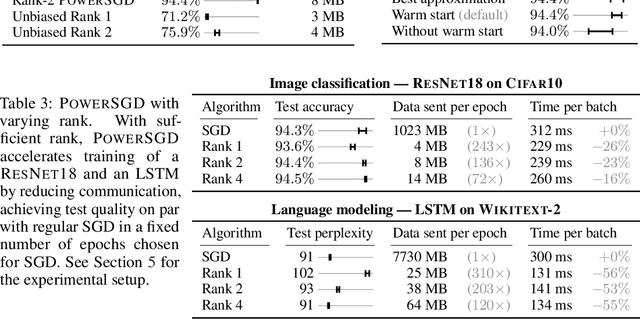
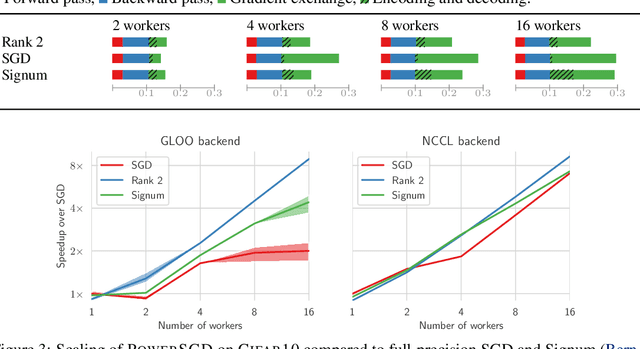
We study gradient compression methods to alleviate the communication bottleneck in data-parallel distributed optimization. Despite the significant attention received, current compression schemes either do not scale well or fail to achieve the target test accuracy. We propose a new low-rank gradient compressor based on power iteration that can i) compress gradients rapidly, ii) efficiently aggregate the compressed gradients using all-reduce, and iii) achieve test performance on par with SGD. The proposed algorithm is the only method evaluated that achieves consistent wall-clock speedups when benchmarked against regular SGD with an optimized communication backend. We demonstrate reduced training times for convolutional networks as well as LSTMs on common datasets. Our code is available at https://github.com/epfml/powersgd.
On Linear Learning with Manycore Processors
May 03, 2019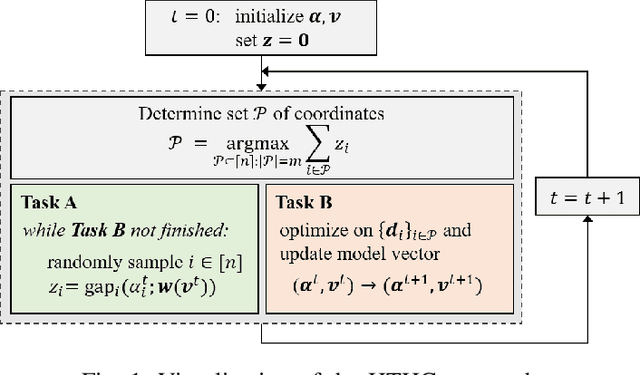
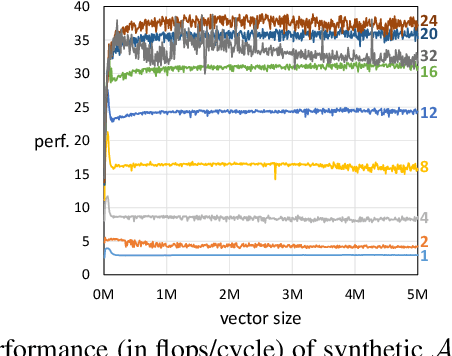
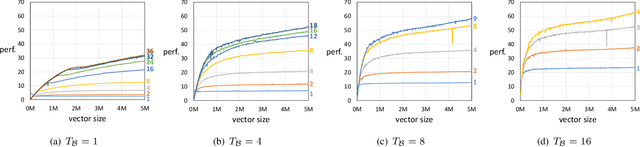
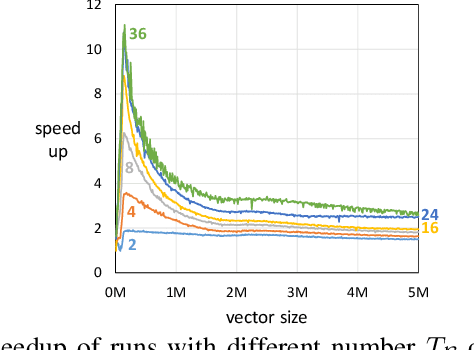
A new generation of manycore processors is on the rise that offers dozens and more cores on a chip and, in a sense, fuses host processor and accelerator. In this paper we target the efficient training of generalized linear models on these machines. We propose a novel approach for achieving parallelism which we call Heterogeneous Tasks on Homogeneous Cores (HTHC). It divides the problem into multiple fundamentally different tasks, which themselves are parallelized. For evaluation, we design a detailed, architecture-cognizant implementation of our scheme on a recent 72-core Knights Landing processor that is adaptive to the cache, memory, and core structure. Experiments for Lasso and SVM with different data sets show a speedup of typically an order of magnitude compared to straightforward parallel implementations in C++.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Better Word Embeddings by Disentangling Contextual n-Gram Information
Apr 10, 2019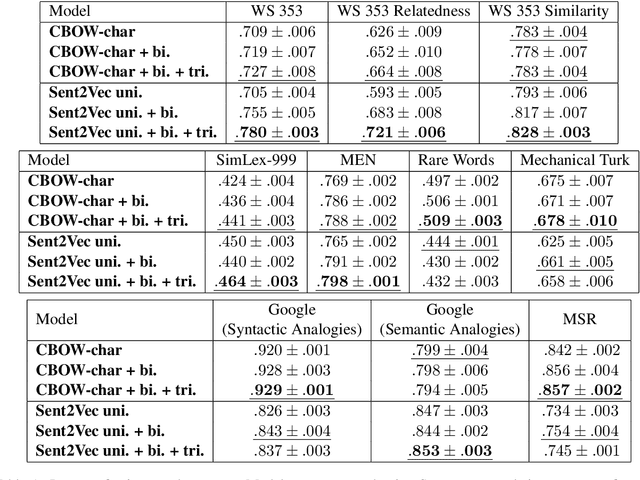
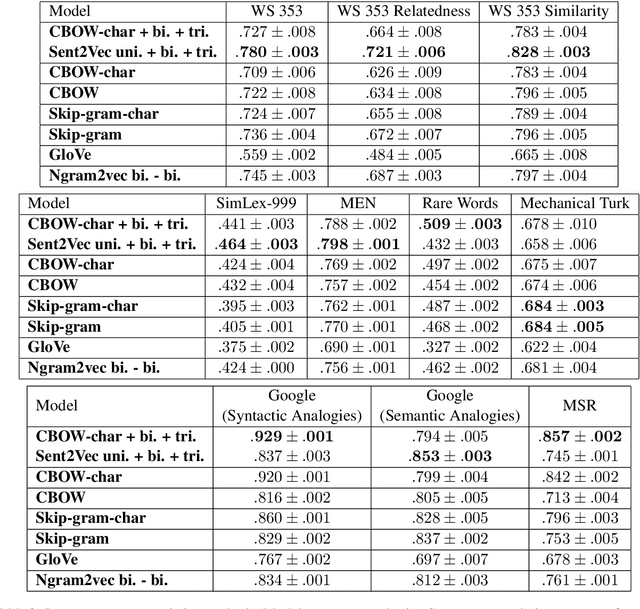
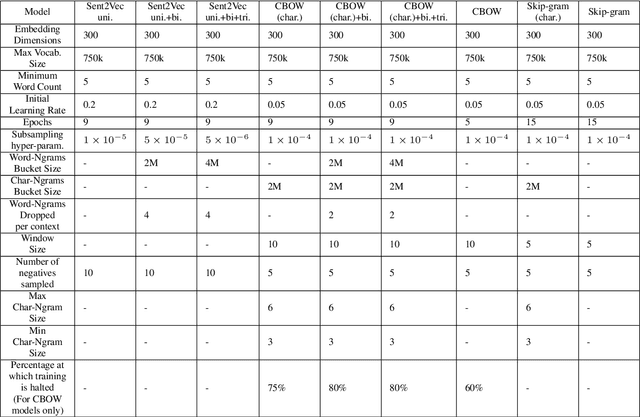
Pre-trained word vectors are ubiquitous in Natural Language Processing applications. In this paper, we show how training word embeddings jointly with bigram and even trigram embeddings, results in improved unigram embeddings. We claim that training word embeddings along with higher n-gram embeddings helps in the removal of the contextual information from the unigrams, resulting in better stand-alone word embeddings. We empirically show the validity of our hypothesis by outperforming other competing word representation models by a significant margin on a wide variety of tasks. We make our models publicly available.
Crosslingual Document Embedding as Reduced-Rank Ridge Regression
Apr 08, 2019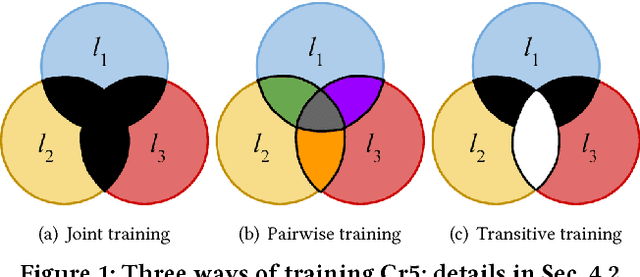
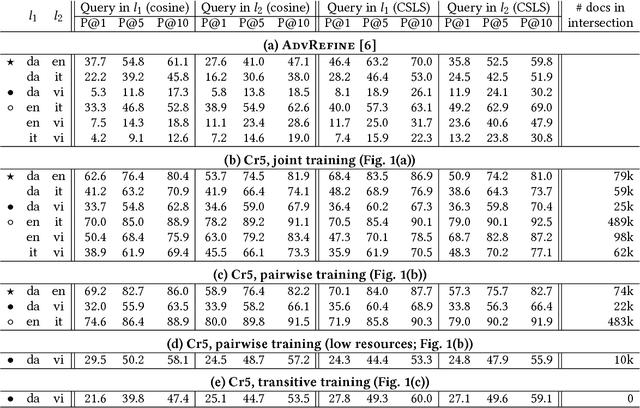
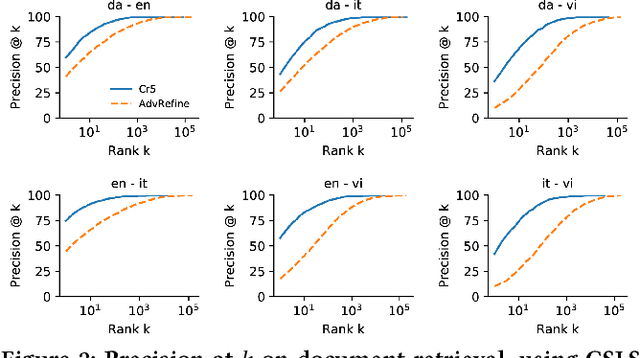

There has recently been much interest in extending vector-based word representations to multiple languages, such that words can be compared across languages. In this paper, we shift the focus from words to documents and introduce a method for embedding documents written in any language into a single, language-independent vector space. For training, our approach leverages a multilingual corpus where the same concept is covered in multiple languages (but not necessarily via exact translations), such as Wikipedia. Our method, Cr5 (Crosslingual reduced-rank ridge regression), starts by training a ridge-regression-based classifier that uses language-specific bag-of-word features in order to predict the concept that a given document is about. We show that, when constraining the learned weight matrix to be of low rank, it can be factored to obtain the desired mappings from language-specific bags-of-words to language-independent embeddings. As opposed to most prior methods, which use pretrained monolingual word vectors, postprocess them to make them crosslingual, and finally average word vectors to obtain document vectors, Cr5 is trained end-to-end and is thus natively crosslingual as well as document-level. Moreover, since our algorithm uses the singular value decomposition as its core operation, it is highly scalable. Experiments show that our method achieves state-of-the-art performance on a crosslingual document retrieval task. Finally, although not trained for embedding sentences and words, it also achieves competitive performance on crosslingual sentence and word retrieval tasks.
Overcoming Multi-Model Forgetting
Mar 02, 2019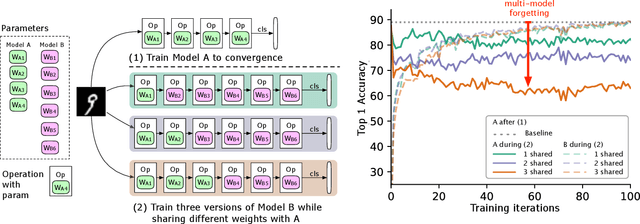
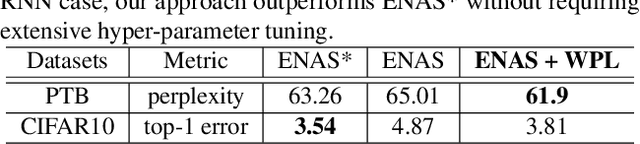
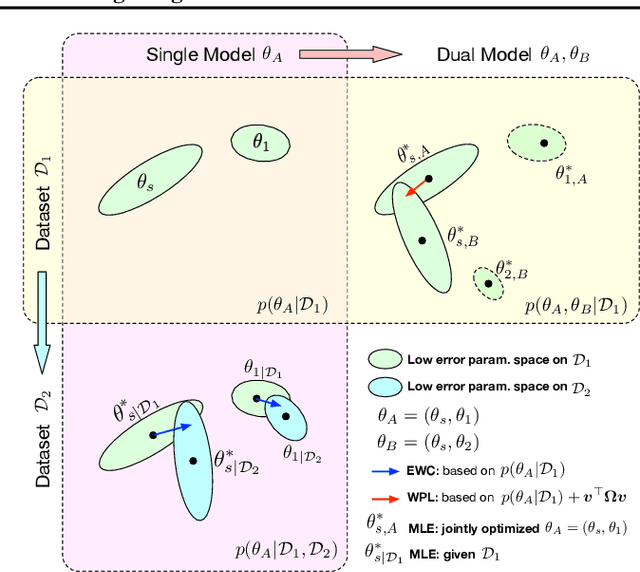
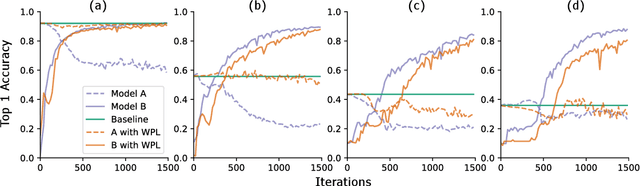
We identify a phenomenon, which we refer to as multi-model forgetting, that occurs when sequentially training multiple deep networks with partially-shared parameters; the performance of previously-trained models degrades as one optimizes a subsequent one, due to the overwriting of shared parameters. To overcome this, we introduce a statistically-justified weight plasticity loss that regularizes the learning of a model's shared parameters according to their importance for the previous models, and demonstrate its effectiveness when training two models sequentially and for neural architecture search. Adding weight plasticity in neural architecture search preserves the best models to the end of the search and yields improved results in both natural language processing and computer vision tasks.
Structure Tree-LSTM: Structure-aware Attentional Document Encoders
Feb 26, 2019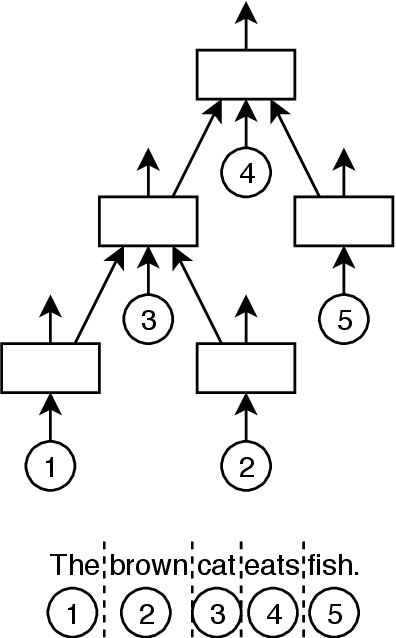

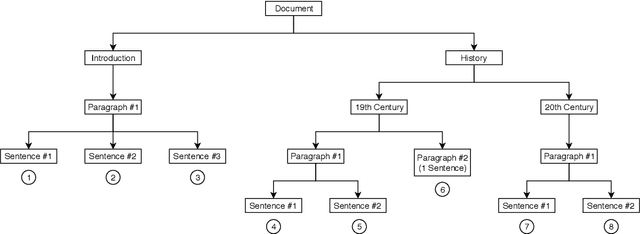
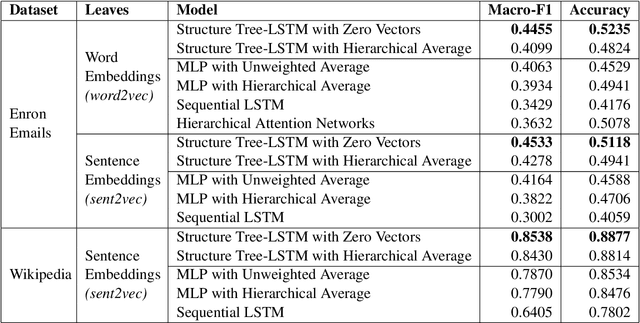
We propose a method to create document representations that reflect their internal structure. We modify Tree-LSTMs to hierarchically merge basic elements like words and sentences into blocks of increasing complexity. Our Structure Tree-LSTM implements a hierarchical attention mechanism over individual components and combinations thereof. We thus emphasize the usefulness of Tree-LSTMs for texts larger than a sentence. We show that structure-aware encoders can be used to improve the performance of document classification. We demonstrate that our method is resilient to changes to the basic building blocks, as it performs well with both sentence and word embeddings. The Structure Tree-LSTM outperforms all the baselines on two datasets when structural clues like sections are available, but also in the presence of mere paragraphs. On a third dataset from the medical domain, our model achieves competitive performance with the state of the art. This result shows the Structure Tree-LSTM can leverage dependency relations other than text structure, such as a set of reports on the same patient.