 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-specific experimental design for treatment effect estimation
Jun 08, 2023



Understanding causality should be a core requirement of any attempt to build real impact through AI. Due to the inherent unobservability of counterfactuals, large randomised trials (RCTs) are the standard for causal inference. But large experiments are generically expensive, and randomisation carries its own costs, e.g. when suboptimal decisions are trialed. Recent work has proposed more sample-efficient alternatives to RCTs, but these are not adaptable to the downstream application for which the causal effect is sought. In this work, we develop a task-specific approach to experimental design and derive sampling strategies customised to particular downstream applications. Across a range of important tasks, real-world datasets, and sample sizes, our method outperforms other benchmarks, e.g. requiring an order-of-magnitude less data to match RCT performance on targeted marketing tasks.
Learning to Noise: Application-Agnostic Data Sharing with Local Differential Privacy
Oct 23, 2020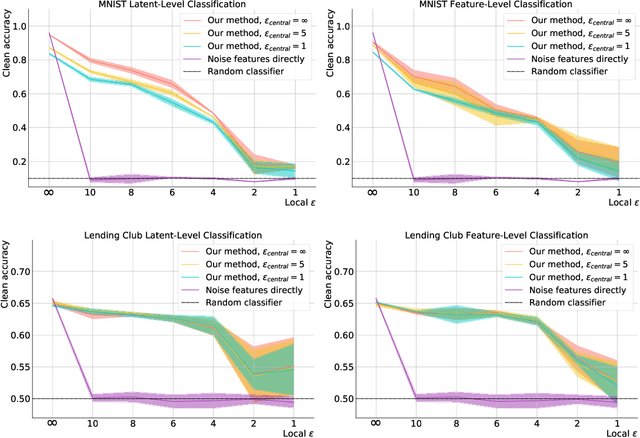
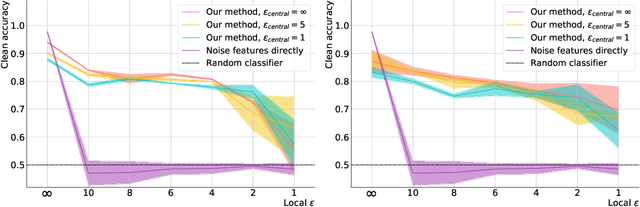
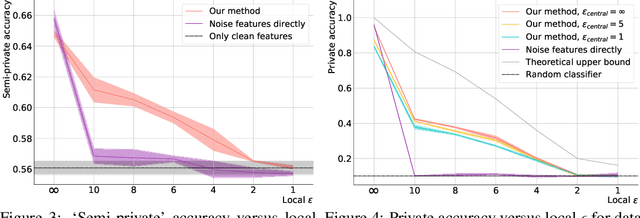
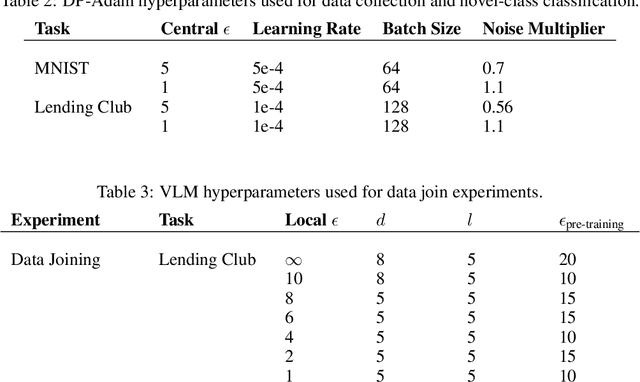
In recent years, the collection and sharing of individuals' private data has become commonplace in many industries. Local differential privacy (LDP) is a rigorous approach which uses a randomized algorithm to preserve privacy even from the database administrator, unlike the more standard central differential privacy. For LDP, when applying noise directly to high-dimensional data, the level of noise required all but entirely destroys data utility. In this paper we introduce a novel, application-agnostic privatization mechanism that leverages representation learning to overcome the prohibitive noise requirements of direct methods, while maintaining the strict guarantees of LDP. We further demonstrate that this privatization mechanism can be used to train machine learning algorithms across a range of applications, including private data collection, private novel-class classification, and the augmentation of clean datasets with additional privatized features. We achieve significant gains in performance on downstream classification tasks relative to benchmarks that noise the data directly, which are state-of-the-art in the context of application-agnostic LDP mechanisms for high-dimensional data.
Explainability for fair machine learning
Oct 14, 2020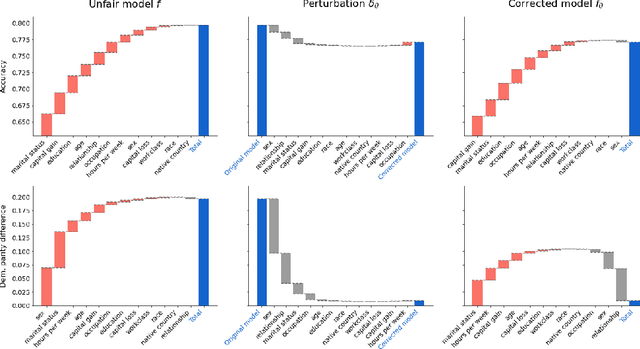
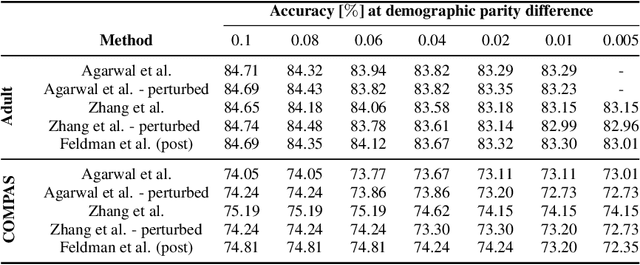
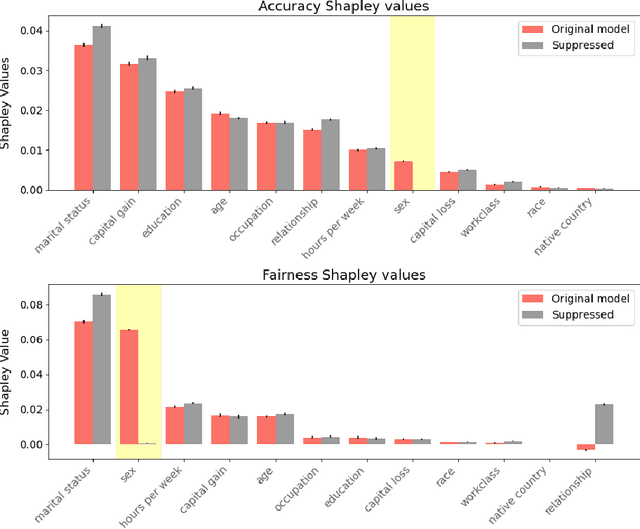
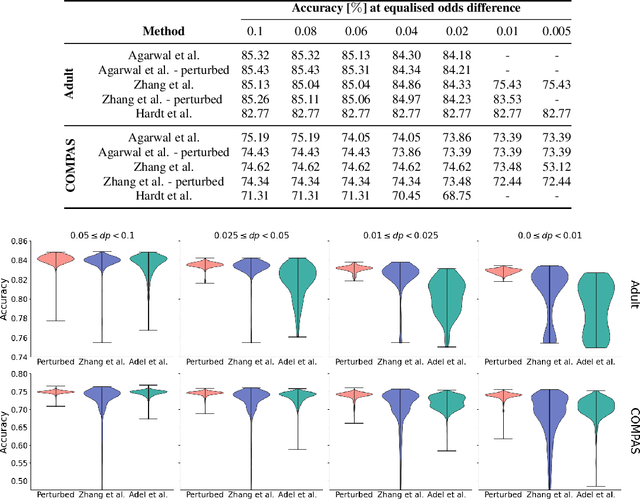
As the decisions made or influenced by machine learning models increasingly impact our lives, it is crucial to detect, understand, and mitigate unfairness. But even simply determining what "unfairness" should mean in a given context is non-trivial: there are many competing definitions, and choosing between them often requires a deep understanding of the underlying task. It is thus tempting to use model explainability to gain insights into model fairness, however existing explainability tools do not reliably indicate whether a model is indeed fair. In this work we present a new approach to explaining fairness in machine learning, based on the Shapley value paradigm. Our fairness explanations attribute a model's overall unfairness to individual input features, even in cases where the model does not operate on sensitive attributes directly. Moreover, motivated by the linearity of Shapley explainability, we propose a meta algorithm for applying existing training-time fairness interventions, wherein one trains a perturbation to the original model, rather than a new model entirely. By explaining the original model, the perturbation, and the fair-corrected model, we gain insight into the accuracy-fairness trade-off that is being made by the intervention. We further show that this meta algorithm enjoys both flexibility and stability benefits with no loss in performance.
Human-interpretable model explainability on high-dimensional data
Oct 14, 2020
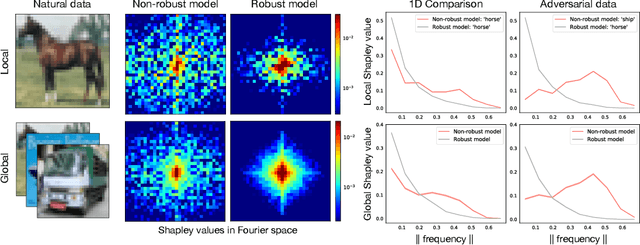
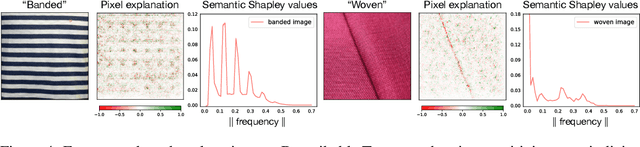
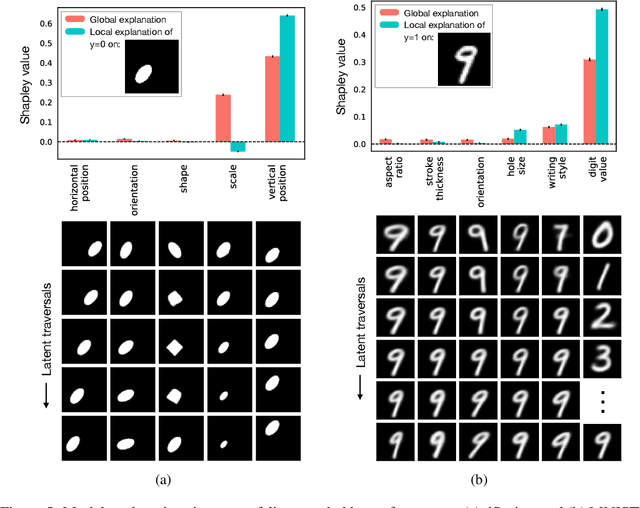
The importance of explainability in machine learning continues to grow, as both neural-network architectures and the data they model become increasingly complex. Unique challenges arise when a model's input features become high dimensional: on one hand, principled model-agnostic approaches to explainability become too computationally expensive; on the other, more efficient explainability algorithms lack natural interpretations for general users. In this work, we introduce a framework for human-interpretable explainability on high-dimensional data, consisting of two modules. First, we apply a semantically meaningful latent representation, both to reduce the raw dimensionality of the data, and to ensure its human interpretability. These latent features can be learnt, e.g. explicitly as disentangled representations or implicitly through image-to-image translation, or they can be based on any computable quantities the user chooses. Second, we adapt the Shapley paradigm for model-agnostic explainability to operate on these latent features. This leads to interpretable model explanations that are both theoretically controlled and computationally tractable. We benchmark our approach on synthetic data and demonstrate its effectiveness on several image-classification tasks.
Learning Deep-Latent Hierarchies by Stacking Wasserstein Autoencoders
Oct 07, 2020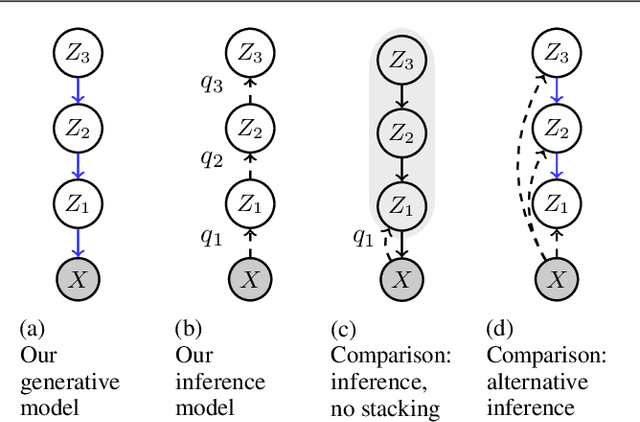



Probabilistic models with hierarchical-latent-variable structures provide state-of-the-art results amongst non-autoregressive, unsupervised density-based models. However, the most common approach to training such models based on Variational Autoencoders (VAEs) often fails to leverage deep-latent hierarchies; successful approaches require complex inference and optimisation schemes. Optimal Transport is an alternative, non-likelihood-based framework for training generative models with appealing theoretical properties, in principle allowing easier training convergence between distributions. In this work we propose a novel approach to training models with deep-latent hierarchies based on Optimal Transport, without the need for highly bespoke models and inference networks. We show that our method enables the generative model to fully leverage its deep-latent hierarchy, avoiding the well known "latent variable collapse" issue of VAEs; therefore, providing qualitatively better sample generations as well as more interpretable latent representation than the original Wasserstein Autoencoder with Maximum Mean Discrepancy divergence.
Learning disentangled representations with the Wasserstein Autoencoder
Oct 07, 2020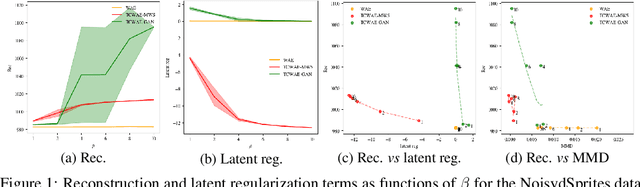
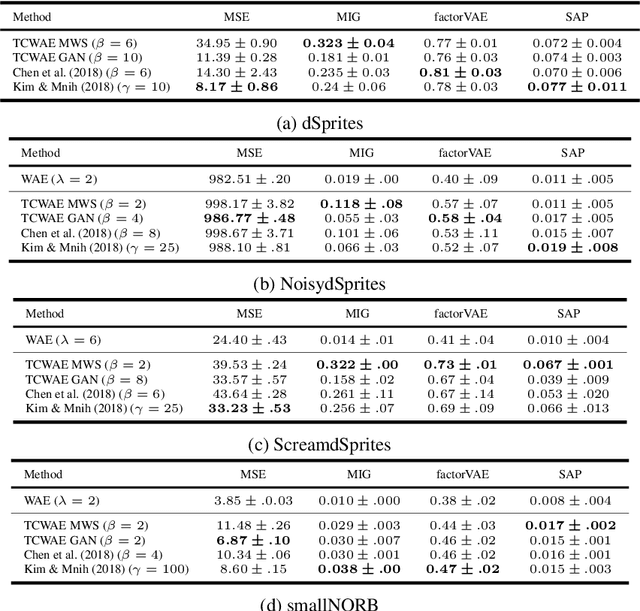

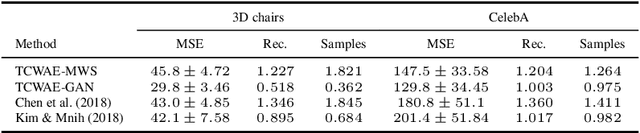
Disentangled representation learning has undoubtedly benefited from objective function surgery. However, a delicate balancing act of tuning is still required in order to trade off reconstruction fidelity versus disentanglement. Building on previous successes of penalizing the total correlation in the latent variables, we propose TCWAE (Total Correlation Wasserstein Autoencoder). Working in the WAE paradigm naturally enables the separation of the total-correlation term, thus providing disentanglement control over the learned representation, while offering more flexibility in the choice of reconstruction cost. We propose two variants using different KL estimators and perform extensive quantitative comparisons on data sets with known generative factors, showing competitive results relative to state-of-the-art techniques. We further study the trade off between disentanglement and reconstruction on more-difficult data sets with unknown generative factors, where the flexibility of the WAE paradigm in the reconstruction term improves reconstructions.
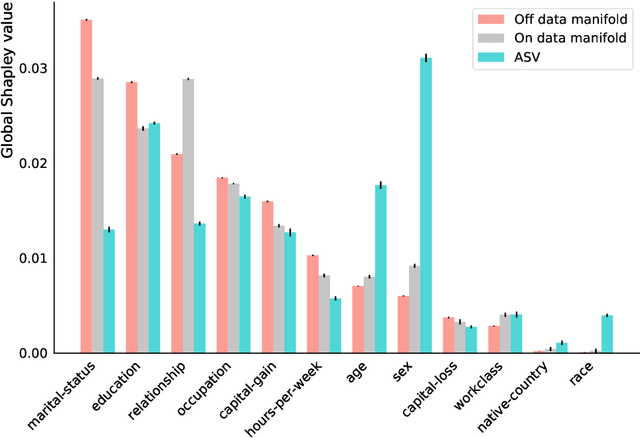
Shapley-based explainability on the data manifold
Jun 01, 2020

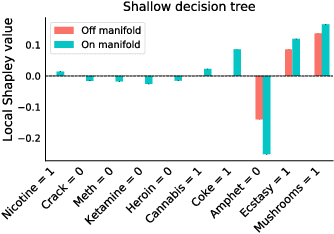
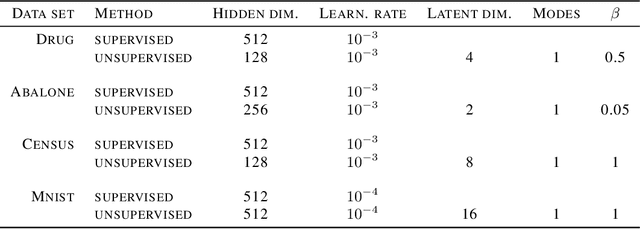
Explainability in machine learning is crucial for iterative model development, compliance with regulation, and providing operational nuance to model predictions. Shapley values provide a general framework for explainability by attributing a model's output prediction to its input features in a mathematically principled and model-agnostic way. However, practical implementations of the Shapley framework make an untenable assumption: that the model's input features are uncorrelated. In this work, we articulate the dangers of this assumption and introduce two solutions for computing Shapley explanations that respect the data manifold. One solution, based on generative modelling, provides flexible access to on-manifold data imputations, while the other directly learns the Shapley value function in a supervised way, providing performance and stability at the cost of flexibility. While the commonly used ``off-manifold'' Shapley values can (i) break symmetries in the data, (ii) give rise to misleading wrong-sign explanations, and (iii) lead to uninterpretable explanations in high-dimensional data, our approach to on-manifold explainability demonstrably overcomes each of these problems.
Asymmetric Shapley values: incorporating causal knowledge into model-agnostic explainability
Oct 14, 2019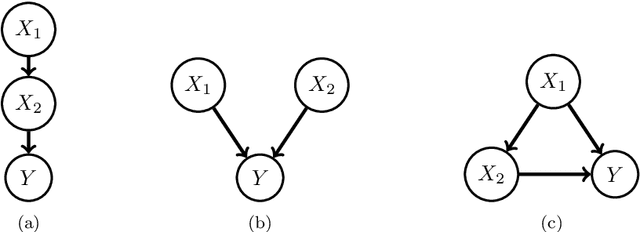
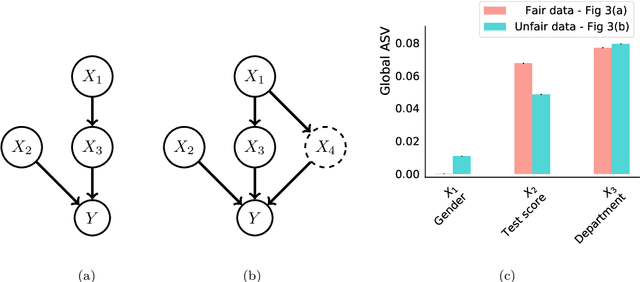
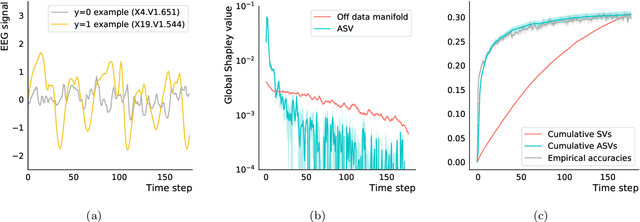
Explaining AI systems is fundamental both to the development of high performing models and to the trust placed in them by their users. A general framework for explaining any AI model is provided by the Shapley values that attribute the prediction output to the various model inputs ("features") in a principled and model-agnostic way. The outstanding strength of Shapley values is their combined generality and rigorous foundation: they can be used to explain any AI system, and one always understands their values as the unique attribution method satisfying a set of mathematical axioms. However, as a framework, Shapley values are too restrictive in one significant regard: they ignore all causal structure in the data. We introduce a less-restrictive framework for model-agnostic explainability: "Asymmetric" Shapley values. Asymmetric Shapley values (ASVs) are rigorously founded on a set of axioms, applicable to any AI system, and can flexibly incorporate any causal knowledge known a-priori to be respected by the data. We show through explicit, realistic examples that the ASV framework can be used to (i) improve model explanations by incorporating causal information, (ii) provide an unambiguous test for unfair discrimination based on simple policy articulations, (iii) enable sequentially incremental explanations in time-series models, and (iv) support feature-selection studies without the need for model retraining.
Parenting: Safe Reinforcement Learning from Human Input
Feb 18, 2019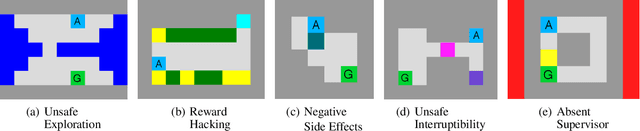
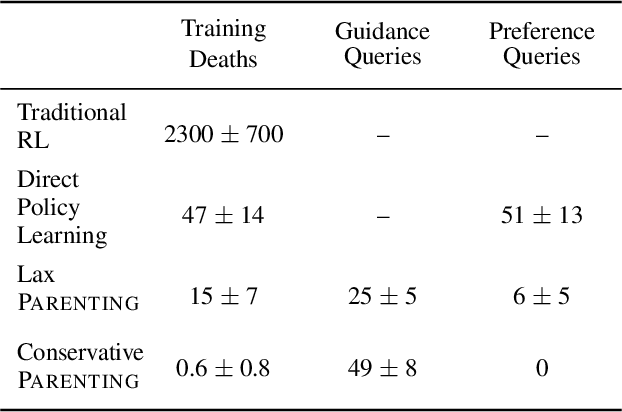
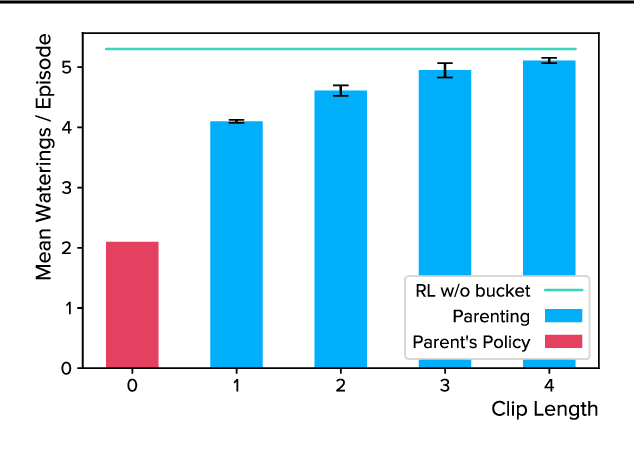
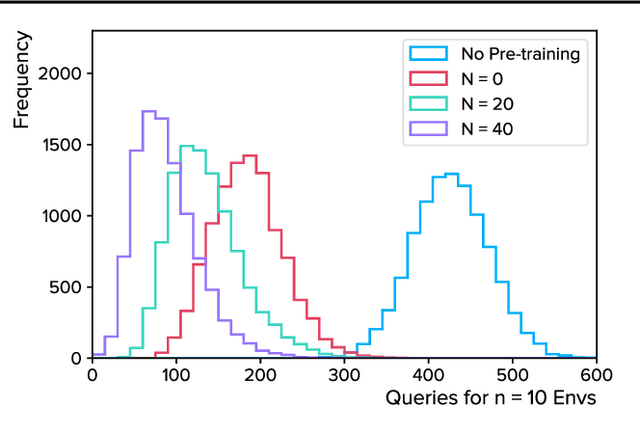
Autonomous agents trained via reinforcement learning present numerous safety concerns: reward hacking, negative side effects, and unsafe exploration, among others. In the context of near-future autonomous agents, operating in environments where humans understand the existing dangers, human involvement in the learning process has proved a promising approach to AI Safety. Here we demonstrate that a precise framework for learning from human input, loosely inspired by the way humans parent children, solves a broad class of safety problems in this context. We show that our Parenting algorithm solves these problems in the relevant AI Safety gridworlds of Leike et al. (2017), that an agent can learn to outperform its parent as it "matures", and that policies learnt through Parenting are generalisable to new environments.
Invariant-equivariant representation learning for multi-class data
Feb 08, 2019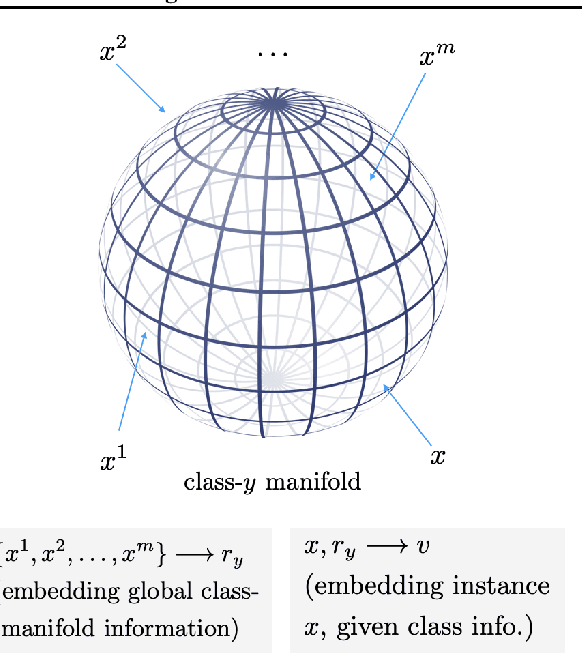
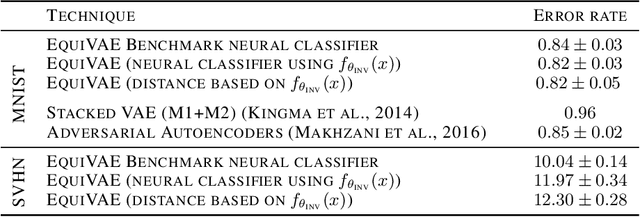
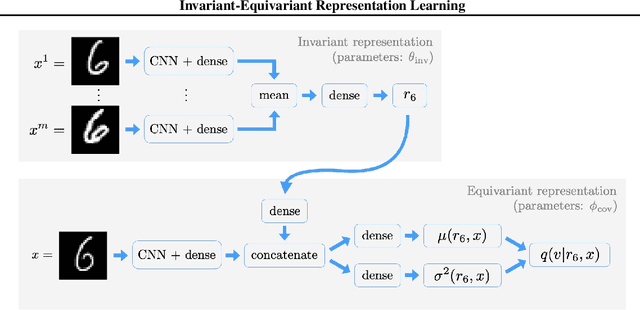
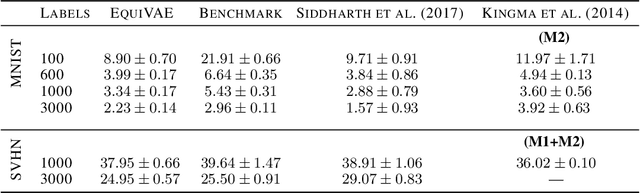
Representations learnt through deep neural networks tend to be highly informative, but opaque in terms of what information they learn to encode. We introduce an approach to probabilistic modelling that learns to represent data with two separate deep representations: an invariant representation that encodes the information of the class from which the data belongs, and an equivariant representation that encodes the symmetry transformation defining the particular data point within the class manifold (equivariant in the sense that the representation varies naturally with symmetry transformations). This approach is based primarily on the strategic routing of data through the two latent variables, and thus is conceptually transparent, easy to implement, and in-principle generally applicable to any data comprised of discrete classes of continuous distributions (e.g. objects in images, topics in language, individuals in behavioural data). We demonstrate qualitatively compelling representation learning and competitive quantitative performance, in both supervised and semi-supervised settings, versus comparable modelling approaches in the literature with little fine tuning.