 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThen and Now: Quantifying the Longitudinal Validity of Self-Disclosed Depression Diagnoses
Jun 22, 2022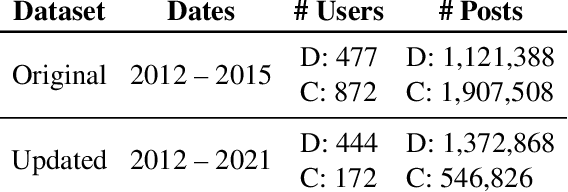
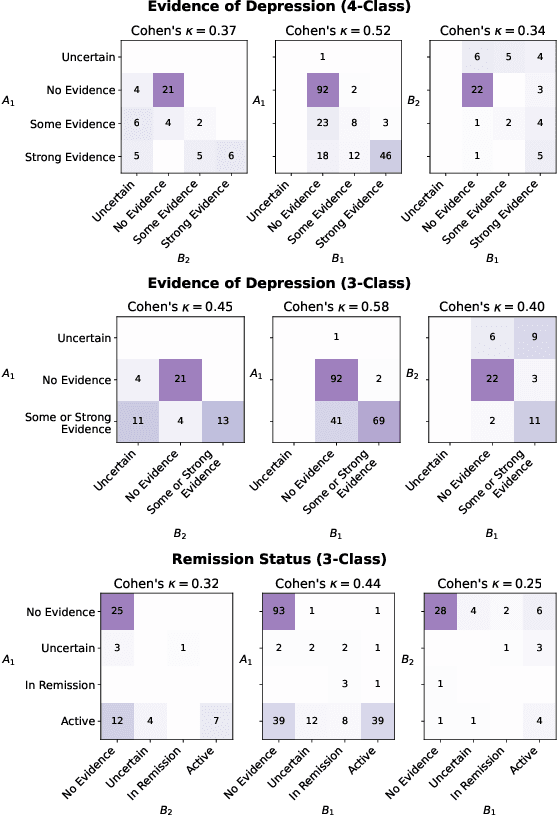
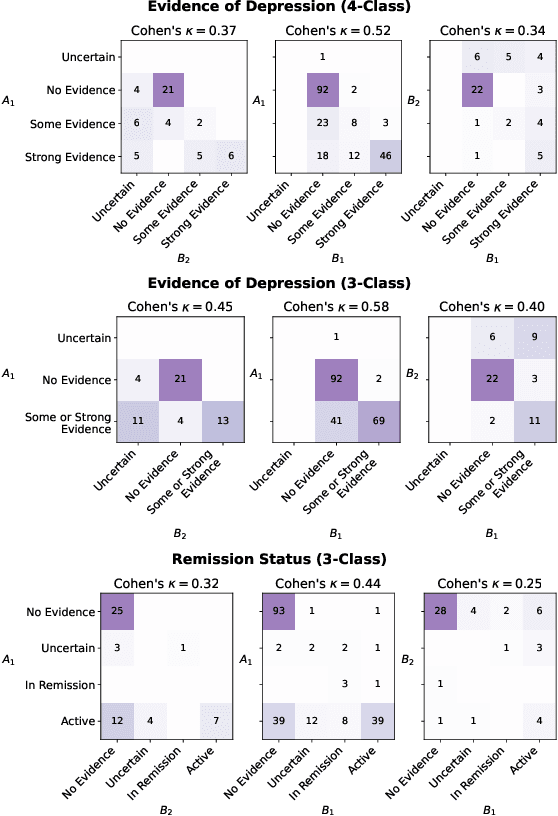
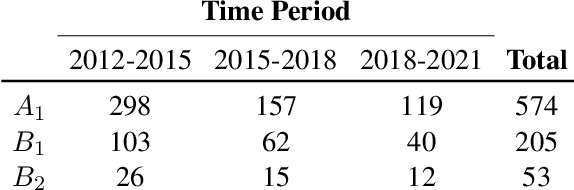
Self-disclosed mental health diagnoses, which serve as ground truth annotations of mental health status in the absence of clinical measures, underpin the conclusions behind most computational studies of mental health language from the last decade. However, psychiatric conditions are dynamic; a prior depression diagnosis may no longer be indicative of an individual's mental health, either due to treatment or other mitigating factors. We ask: to what extent are self-disclosures of mental health diagnoses actually relevant over time? We analyze recent activity from individuals who disclosed a depression diagnosis on social media over five years ago and, in turn, acquire a new understanding of how presentations of mental health status on social media manifest longitudinally. We also provide expanded evidence for the presence of personality-related biases in datasets curated using self-disclosed diagnoses. Our findings motivate three practical recommendations for improving mental health datasets curated using self-disclosed diagnoses: 1) Annotate diagnosis dates and psychiatric comorbidities; 2) Sample control groups using propensity score matching; 3) Identify and remove spurious correlations introduced by selection bias.
What Makes Data-to-Text Generation Hard for Pretrained Language Models?
May 23, 2022


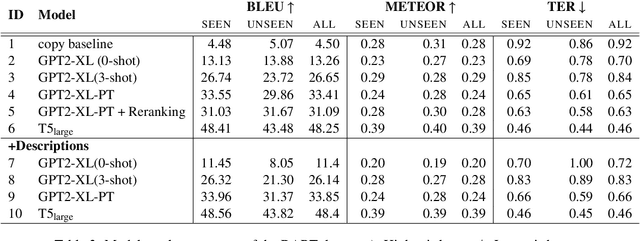
Expressing natural language descriptions of structured facts or relations -- data-to-text generation (D2T) -- increases the accessibility of structured knowledge repositories. Previous work shows that pre-trained language models(PLMs) perform remarkably well on this task after fine-tuning on a significant amount of task-specific training data. On the other hand, while auto-regressive PLMs can generalize from a few task examples, their efficacy at D2T is largely unexplored. Furthermore, we have an incomplete understanding of the limits of PLMs on D2T. In this work, we conduct an empirical study of both fine-tuned and auto-regressive PLMs on the DART multi-domain D2T dataset. We consider their performance as a function of the amount of task-specific data and how these data are incorporated into the models: zero and few-shot learning, and fine-tuning of model weights. In addition, we probe the limits of PLMs by measuring performance on subsets of the evaluation data: novel predicates and abstractive test examples. To improve the performance on these subsets, we investigate two techniques: providing predicate descriptions in the context and re-ranking generated candidates by information reflected in the source. Finally, we conduct a human evaluation of model errors and show that D2T generation tasks would benefit from datasets with more careful manual curation.
Enriching Unsupervised User Embedding via Medical Concepts
Mar 29, 2022
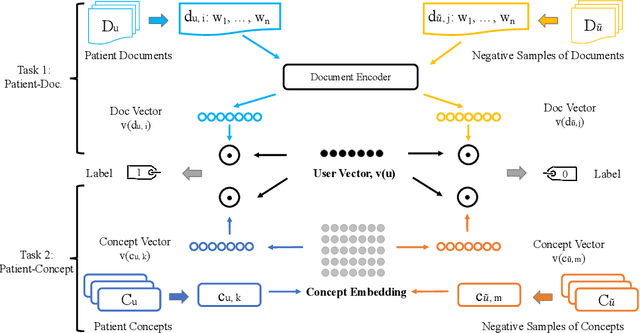
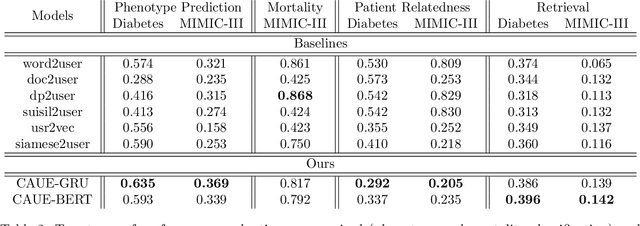
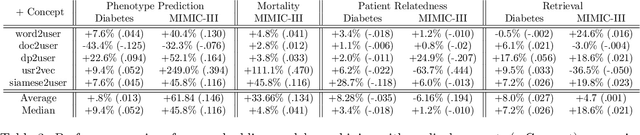
Clinical notes in Electronic Health Records (EHR) present rich documented information of patients to inference phenotype for disease diagnosis and study patient characteristics for cohort selection. Unsupervised user embedding aims to encode patients into fixed-length vectors without human supervisions. Medical concepts extracted from the clinical notes contain rich connections between patients and their clinical categories. However, existing unsupervised approaches of user embeddings from clinical notes do not explicitly incorporate medical concepts. In this study, we propose a concept-aware unsupervised user embedding that jointly leverages text documents and medical concepts from two clinical corpora, MIMIC-III and Diabetes. We evaluate user embeddings on both extrinsic and intrinsic tasks, including phenotype classification, in-hospital mortality prediction, patient retrieval, and patient relatedness. Experiments on the two clinical corpora show our approach exceeds unsupervised baselines, and incorporating medical concepts can significantly improve the baseline performance.
Everything Is All It Takes: A Multipronged Strategy for Zero-Shot Cross-Lingual Information Extraction
Sep 14, 2021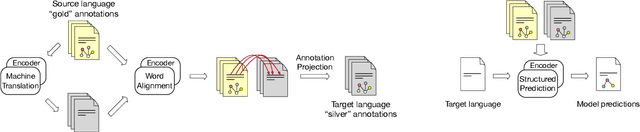

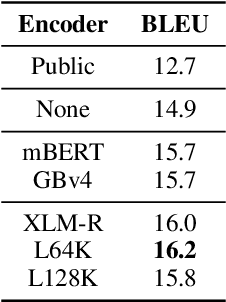
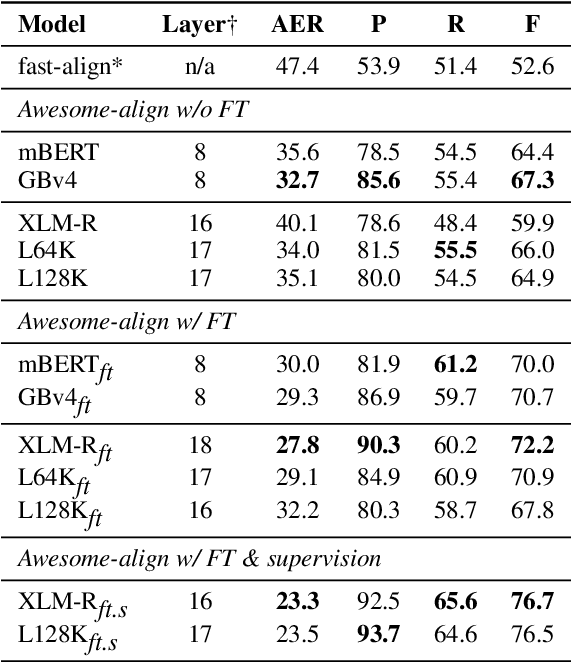
Zero-shot cross-lingual information extraction (IE) describes the construction of an IE model for some target language, given existing annotations exclusively in some other language, typically English. While the advance of pretrained multilingual encoders suggests an easy optimism of "train on English, run on any language", we find through a thorough exploration and extension of techniques that a combination of approaches, both new and old, leads to better performance than any one cross-lingual strategy in particular. We explore techniques including data projection and self-training, and how different pretrained encoders impact them. We use English-to-Arabic IE as our initial example, demonstrating strong performance in this setting for event extraction, named entity recognition, part-of-speech tagging, and dependency parsing. We then apply data projection and self-training to three tasks across eight target languages. Because no single set of techniques performs the best across all tasks, we encourage practitioners to explore various configurations of the techniques described in this work when seeking to improve on zero-shot training.
Learning to Look Inside: Augmenting Token-Based Encoders with Character-Level Information
Aug 01, 2021
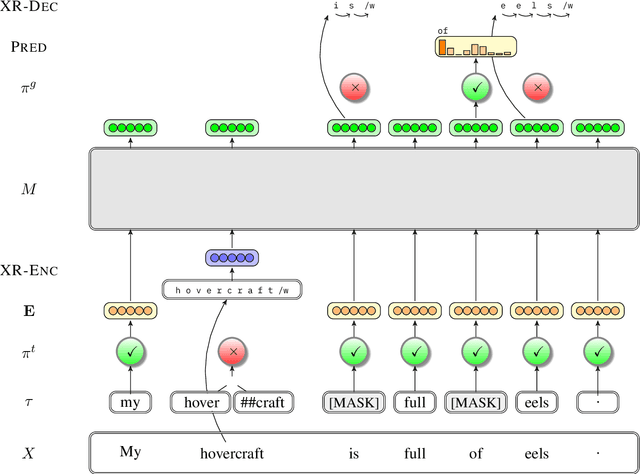

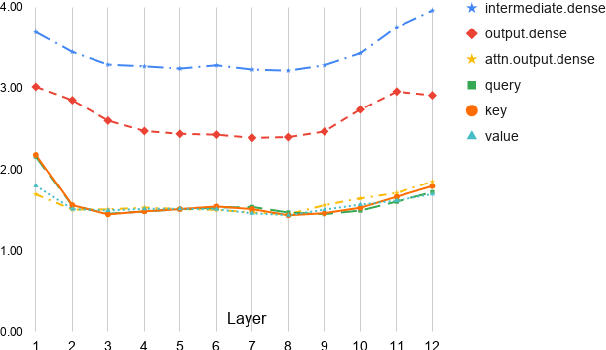
Commonly-used transformer language models depend on a tokenization schema which sets an unchangeable subword vocabulary prior to pre-training, destined to be applied to all downstream tasks regardless of domain shift, novel word formations, or other sources of vocabulary mismatch. Recent work has shown that "token-free" models can be trained directly on characters or bytes, but training these models from scratch requires substantial computational resources, and this implies discarding the many domain-specific models that were trained on tokens. In this paper, we present XRayEmb, a method for retrofitting existing token-based models with character-level information. XRayEmb is composed of a character-level "encoder" that computes vector representations of character sequences, and a generative component that decodes from the internal representation to a character sequence. We show that incorporating XRayEmb's learned vectors into sequences of pre-trained token embeddings helps performance on both autoregressive and masked pre-trained transformer architectures and on both sequence-level and sequence tagging tasks, particularly on non-standard English text.
Improving Zero-Shot Multi-Lingual Entity Linking
Apr 16, 2021
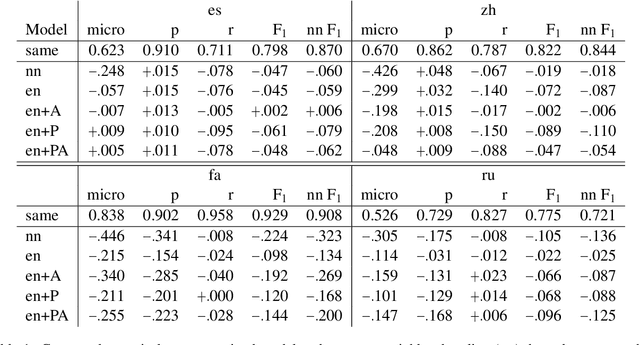
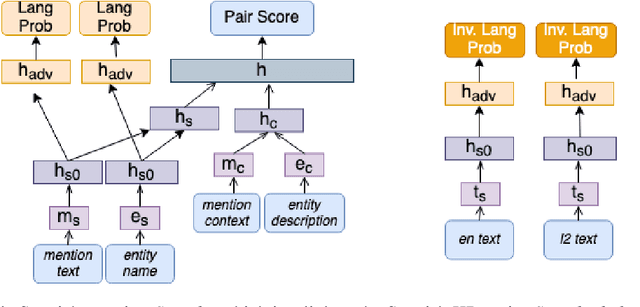
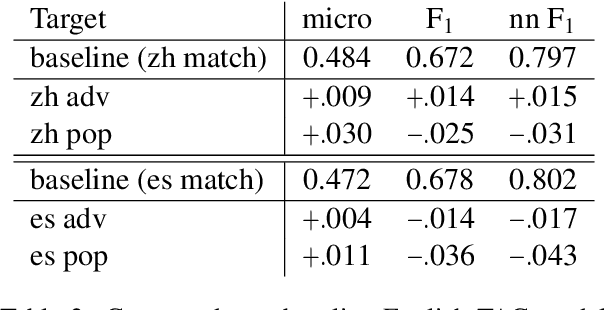
Entity linking -- the task of identifying references in free text to relevant knowledge base representations -- often focuses on single languages. We consider multilingual entity linking, where a single model is trained to link references to same-language knowledge bases in several languages. We propose a neural ranker architecture, which leverages multilingual transformer representations of text to be easily applied to a multilingual setting. We then explore how a neural ranker trained in one language (e.g. English) transfers to an unseen language (e.g. Chinese), and find that while there is a consistent but not large drop in performance. How can this drop in performance be alleviated? We explore adding an adversarial objective to force our model to learn language-invariant representations. We find that using this approach improves recall in several datasets, often matching the in-language performance, thus alleviating some of the performance loss occurring from zero-shot transfer.
Faithful and Plausible Explanations of Medical Code Predictions
Apr 16, 2021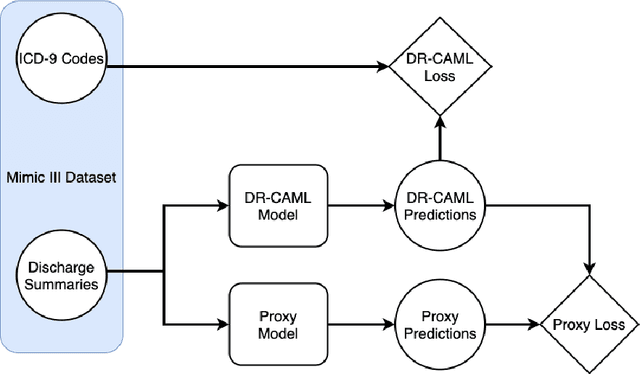

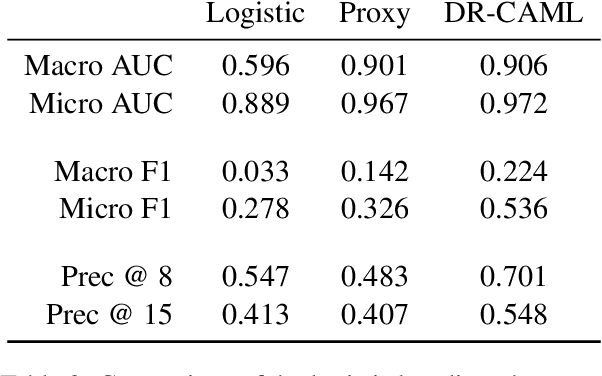
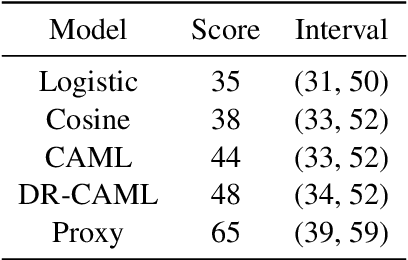
Machine learning models that offer excellent predictive performance often lack the interpretability necessary to support integrated human machine decision-making. In clinical medicine and other high-risk settings, domain experts may be unwilling to trust model predictions without explanations. Work in explainable AI must balance competing objectives along two different axes: 1) Explanations must balance faithfulness to the model's decision-making with their plausibility to a domain expert. 2) Domain experts desire local explanations of individual predictions and global explanations of behavior in aggregate. We propose to train a proxy model that mimics the behavior of the trained model and provides fine-grained control over these trade-offs. We evaluate our approach on the task of assigning ICD codes to clinical notes to demonstrate that explanations from the proxy model are faithful and replicate the trained model behavior.
Fine-tuning Encoders for Improved Monolingual and Zero-shot Polylingual Neural Topic Modeling
Apr 11, 2021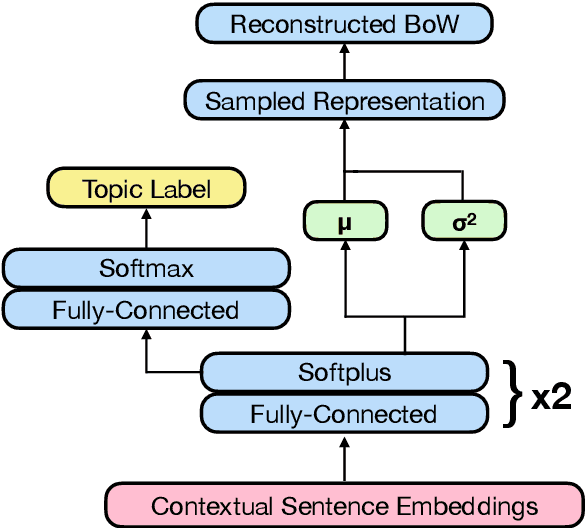
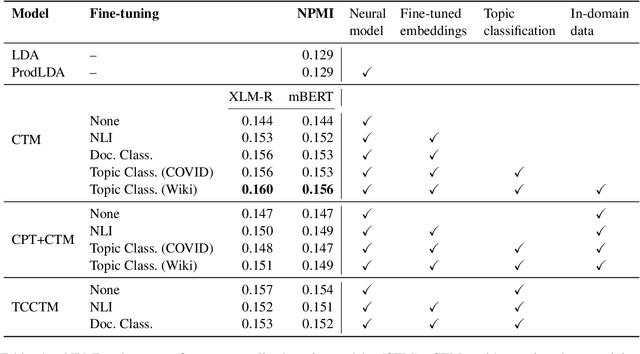
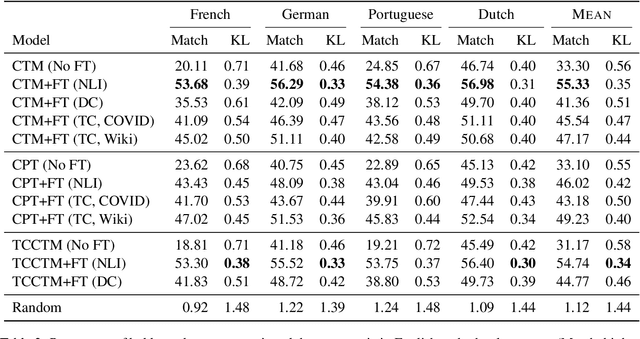
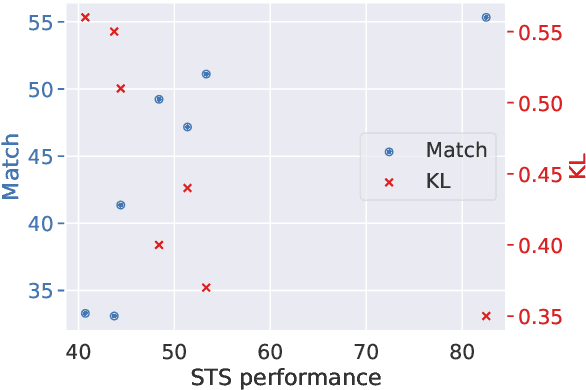
Neural topic models can augment or replace bag-of-words inputs with the learned representations of deep pre-trained transformer-based word prediction models. One added benefit when using representations from multilingual models is that they facilitate zero-shot polylingual topic modeling. However, while it has been widely observed that pre-trained embeddings should be fine-tuned to a given task, it is not immediately clear what supervision should look like for an unsupervised task such as topic modeling. Thus, we propose several methods for fine-tuning encoders to improve both monolingual and zero-shot polylingual neural topic modeling. We consider fine-tuning on auxiliary tasks, constructing a new topic classification task, integrating the topic classification objective directly into topic model training, and continued pre-training. We find that fine-tuning encoder representations on topic classification and integrating the topic classification task directly into topic modeling improves topic quality, and that fine-tuning encoder representations on any task is the most important factor for facilitating cross-lingual transfer.
Gender and Racial Fairness in Depression Research using Social Media
Mar 18, 2021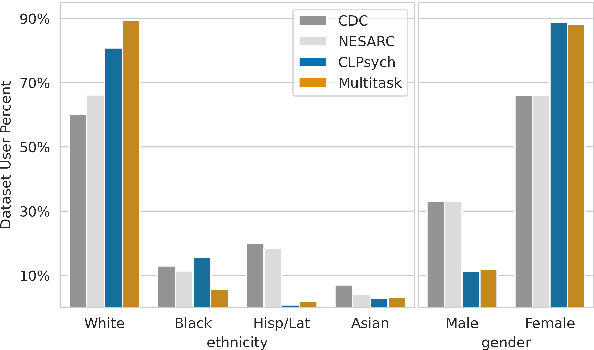
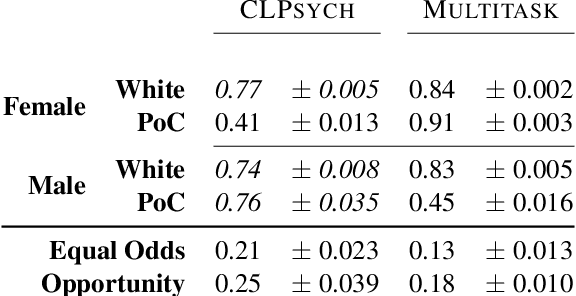
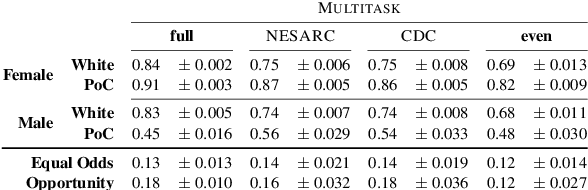
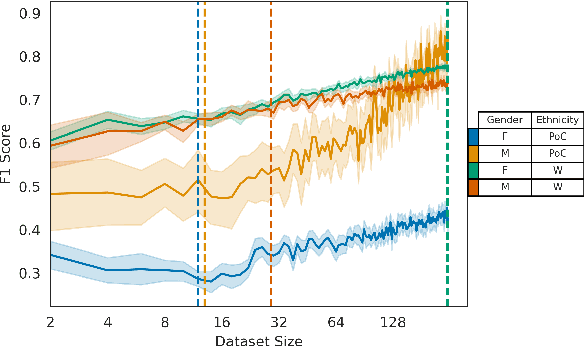
Multiple studies have demonstrated that behavior on internet-based social media platforms can be indicative of an individual's mental health status. The widespread availability of such data has spurred interest in mental health research from a computational lens. While previous research has raised concerns about possible biases in models produced from this data, no study has quantified how these biases actually manifest themselves with respect to different demographic groups, such as gender and racial/ethnic groups. Here, we analyze the fairness of depression classifiers trained on Twitter data with respect to gender and racial demographic groups. We find that model performance systematically differs for underrepresented groups and that these discrepancies cannot be fully explained by trivial data representation issues. Our study concludes with recommendations on how to avoid these biases in future research.
User Factor Adaptation for User Embedding via Multitask Learning
Feb 22, 2021
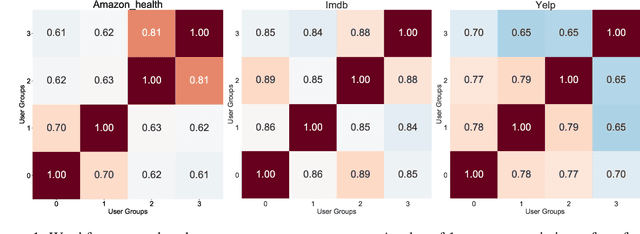
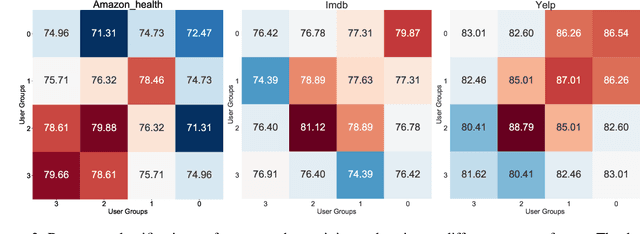
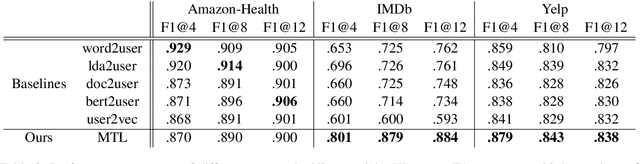
Language varies across users and their interested fields in social media data: words authored by a user across his/her interests may have different meanings (e.g., cool) or sentiments (e.g., fast). However, most of the existing methods to train user embeddings ignore the variations across user interests, such as product and movie categories (e.g., drama vs. action). In this study, we treat the user interest as domains and empirically examine how the user language can vary across the user factor in three English social media datasets. We then propose a user embedding model to account for the language variability of user interests via a multitask learning framework. The model learns user language and its variations without human supervision. While existing work mainly evaluated the user embedding by extrinsic tasks, we propose an intrinsic evaluation via clustering and evaluate user embeddings by an extrinsic task, text classification. The experiments on the three English-language social media datasets show that our proposed approach can generally outperform baselines via adapting the user factor.