 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Informally Romanized Language Identification
Apr 30, 2025



The Latin script is often used to informally write languages with non-Latin native scripts. In many cases (e.g., most languages in India), there is no conventional spelling of words in the Latin script, hence there will be high spelling variability in written text. Such romanization renders languages that are normally easily distinguished based on script highly confusable, such as Hindi and Urdu. In this work, we increase language identification (LID) accuracy for romanized text by improving the methods used to synthesize training sets. We find that training on synthetic samples which incorporate natural spelling variation yields higher LID system accuracy than including available naturally occurring examples in the training set, or even training higher capacity models. We demonstrate new state-of-the-art LID performance on romanized text from 20 Indic languages in the Bhasha-Abhijnaanam evaluation set (Madhani et al., 2023a), improving test F1 from the reported 74.7% (using a pretrained neural model) to 85.4% using a linear classifier trained solely on synthetic data and 88.2% when also training on available harvested text.
Towards Fast Inference: Exploring and Improving Blockwise Parallel Drafts
Apr 14, 2024



Despite the remarkable strides made by autoregressive language models, their potential is often hampered by the slow inference speeds inherent in sequential token generation. Blockwise parallel decoding (BPD) was proposed by Stern et al. (2018) as a way to improve inference speed of language models. In this paper, we make two contributions to understanding and improving BPD drafts. We first offer an analysis of the token distributions produced by the BPD prediction heads. Secondly, we use this analysis to inform algorithms to improve BPD inference speed by refining the BPD drafts using small n-gram or neural language models. We empirically show that these refined BPD drafts yield a higher average verified prefix length across tasks.
Weakly Supervised Headline Dependency Parsing
Jan 25, 2023



English news headlines form a register with unique syntactic properties that have been documented in linguistics literature since the 1930s. However, headlines have received surprisingly little attention from the NLP syntactic parsing community. We aim to bridge this gap by providing the first news headline corpus of Universal Dependencies annotated syntactic dependency trees, which enables us to evaluate existing state-of-the-art dependency parsers on news headlines. To improve English news headline parsing accuracies, we develop a projection method to bootstrap silver training data from unlabeled news headline-article lead sentence pairs. Models trained on silver headline parses demonstrate significant improvements in performance over models trained solely on gold-annotated long-form texts. Ultimately, we find that, although projected silver training data improves parser performance across different news outlets, the improvement is moderated by constructions idiosyncratic to outlet.
* Findings of EMNLP 2022
What Makes Data-to-Text Generation Hard for Pretrained Language Models?
May 23, 2022


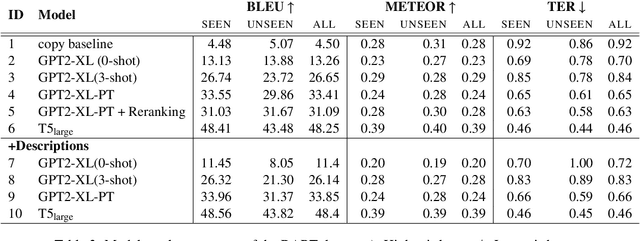
Expressing natural language descriptions of structured facts or relations -- data-to-text generation (D2T) -- increases the accessibility of structured knowledge repositories. Previous work shows that pre-trained language models(PLMs) perform remarkably well on this task after fine-tuning on a significant amount of task-specific training data. On the other hand, while auto-regressive PLMs can generalize from a few task examples, their efficacy at D2T is largely unexplored. Furthermore, we have an incomplete understanding of the limits of PLMs on D2T. In this work, we conduct an empirical study of both fine-tuned and auto-regressive PLMs on the DART multi-domain D2T dataset. We consider their performance as a function of the amount of task-specific data and how these data are incorporated into the models: zero and few-shot learning, and fine-tuning of model weights. In addition, we probe the limits of PLMs by measuring performance on subsets of the evaluation data: novel predicates and abstractive test examples. To improve the performance on these subsets, we investigate two techniques: providing predicate descriptions in the context and re-ranking generated candidates by information reflected in the source. Finally, we conduct a human evaluation of model errors and show that D2T generation tasks would benefit from datasets with more careful manual curation.
Comparing Euclidean and Hyperbolic Embeddings on the WordNet Nouns Hypernymy Graph
Sep 15, 2021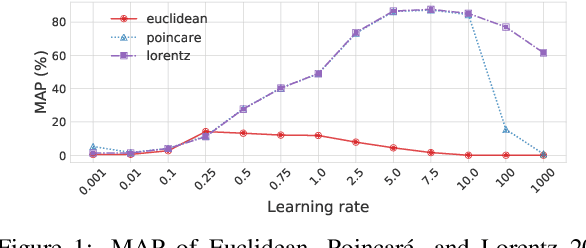
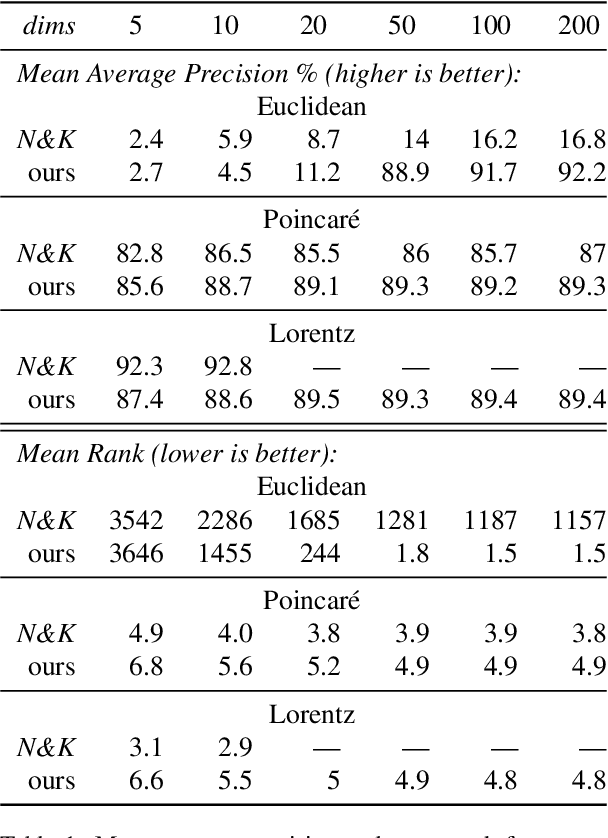

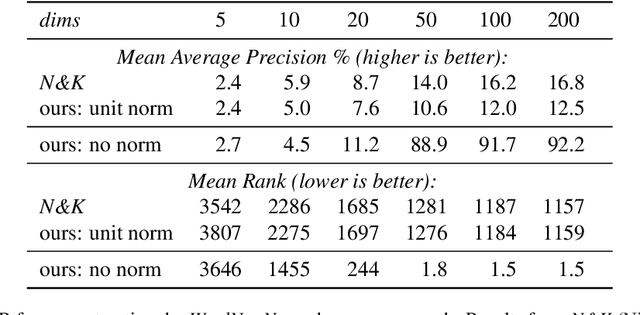
Nickel and Kiela (2017) present a new method for embedding tree nodes in the Poincare ball, and suggest that these hyperbolic embeddings are far more effective than Euclidean embeddings at embedding nodes in large, hierarchically structured graphs like the WordNet nouns hypernymy tree. This is especially true in low dimensions (Nickel and Kiela, 2017, Table 1). In this work, we seek to reproduce their experiments on embedding and reconstructing the WordNet nouns hypernymy graph. Counter to what they report, we find that Euclidean embeddings are able to represent this tree at least as well as Poincare embeddings, when allowed at least 50 dimensions. We note that this does not diminish the significance of their work given the impressive performance of hyperbolic embeddings in very low-dimensional settings. However, given the wide influence of their work, our aim here is to present an updated and more accurate comparison between the Euclidean and hyperbolic embeddings.
Cross-Register Projection for Headline Part of Speech Tagging
Sep 15, 2021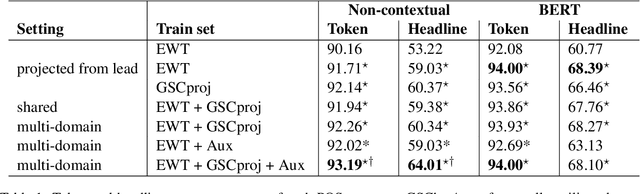
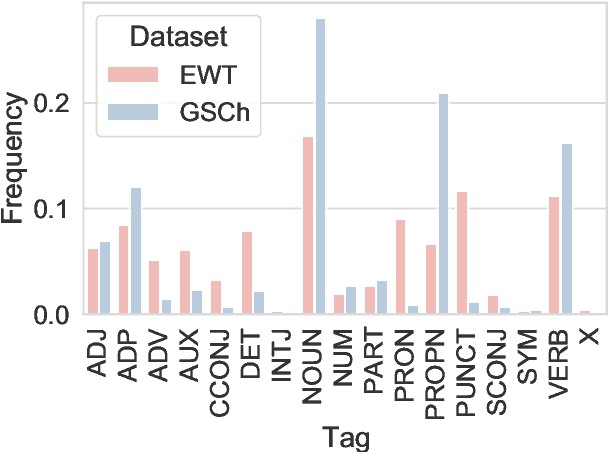
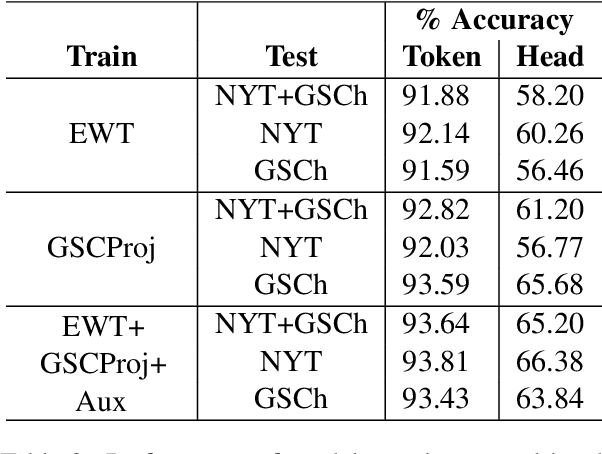
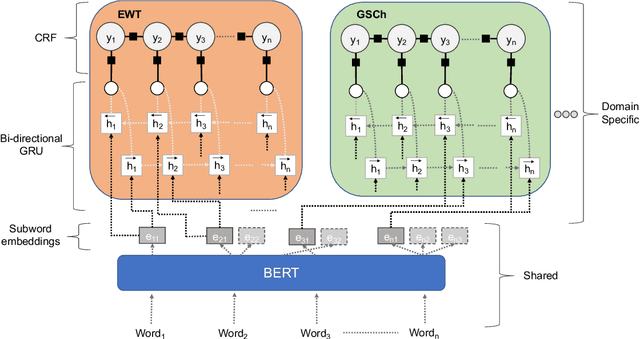
Part of speech (POS) tagging is a familiar NLP task. State of the art taggers routinely achieve token-level accuracies of over 97% on news body text, evidence that the problem is well understood. However, the register of English news headlines, "headlinese", is very different from the register of long-form text, causing POS tagging models to underperform on headlines. In this work, we automatically annotate news headlines with POS tags by projecting predicted tags from corresponding sentences in news bodies. We train a multi-domain POS tagger on both long-form and headline text and show that joint training on both registers improves over training on just one or naively concatenating training sets. We evaluate on a newly-annotated corpus of over 5,248 English news headlines from the Google sentence compression corpus, and show that our model yields a 23% relative error reduction per token and 19% per headline. In addition, we demonstrate that better headline POS tags can improve the performance of a syntax-based open information extraction system. We make POSH, the POS-tagged Headline corpus, available to encourage research in improved NLP models for news headlines.
Diversity-Aware Batch Active Learning for Dependency Parsing
Apr 28, 2021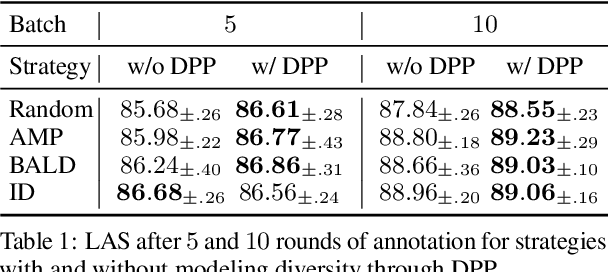
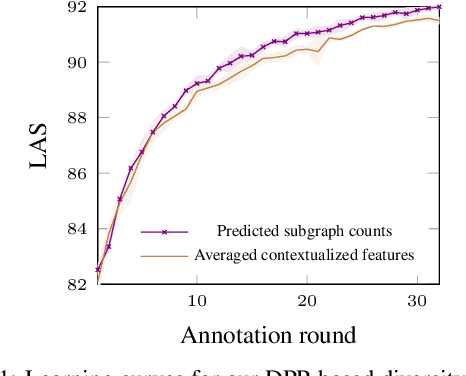
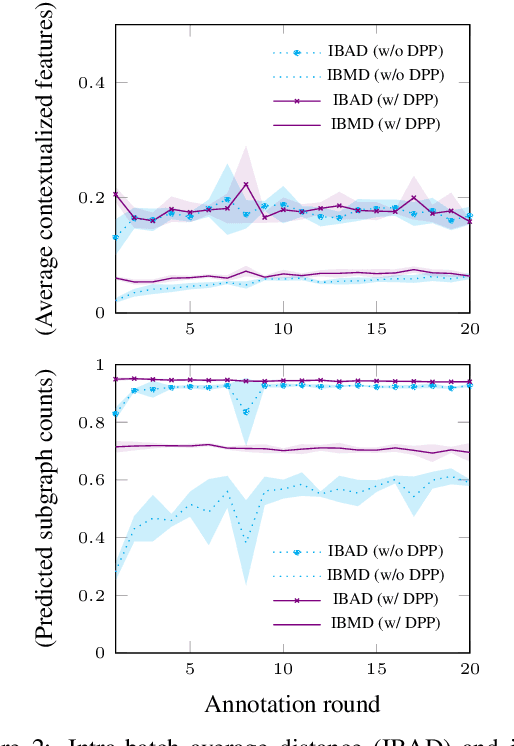
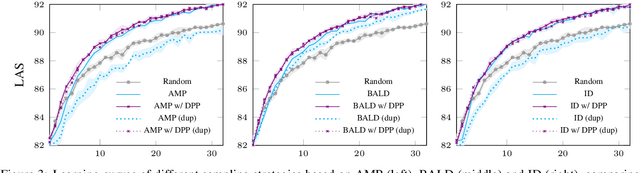
While the predictive performance of modern statistical dependency parsers relies heavily on the availability of expensive expert-annotated treebank data, not all annotations contribute equally to the training of the parsers. In this paper, we attempt to reduce the number of labeled examples needed to train a strong dependency parser using batch active learning (AL). In particular, we investigate whether enforcing diversity in the sampled batches, using determinantal point processes (DPPs), can improve over their diversity-agnostic counterparts. Simulation experiments on an English newswire corpus show that selecting diverse batches with DPPs is superior to strong selection strategies that do not enforce batch diversity, especially during the initial stages of the learning process. Additionally, our diversityaware strategy is robust under a corpus duplication setting, where diversity-agnostic sampling strategies exhibit significant degradation.
* NAACL 2021
kōan: A Corrected CBOW Implementation
Dec 30, 2020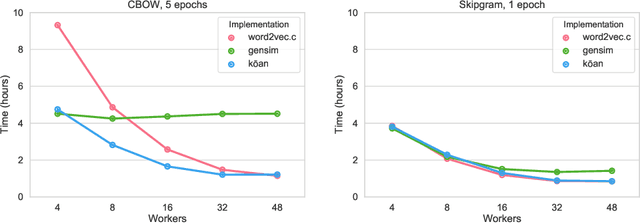

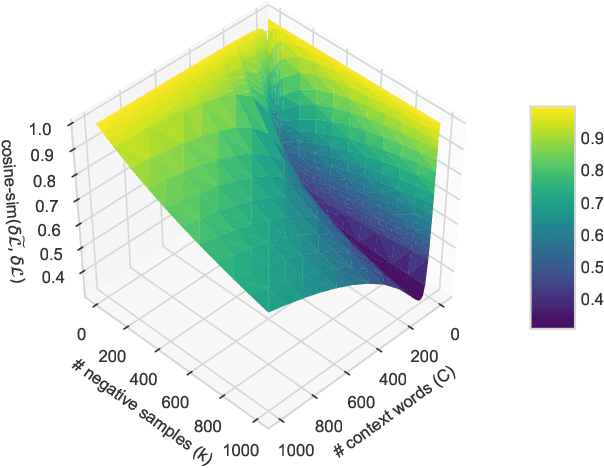
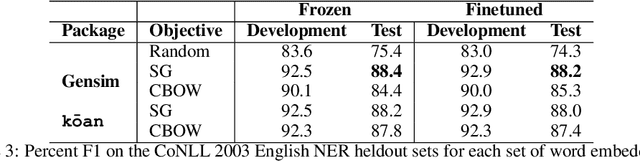
It is a common belief in the NLP community that continuous bag-of-words (CBOW) word embeddings tend to underperform skip-gram (SG) embeddings. We find that this belief is founded less on theoretical differences in their training objectives but more on faulty CBOW implementations in standard software libraries such as the official implementation word2vec.c and Gensim. We show that our correct implementation of CBOW yields word embeddings that are fully competitive with SG on various intrinsic and extrinsic tasks while being more than three times as fast to train. We release our implementation, k\=oan, at https://github.com/bloomberg/koan.
Learning Representations of Social Media Users
Dec 02, 2018
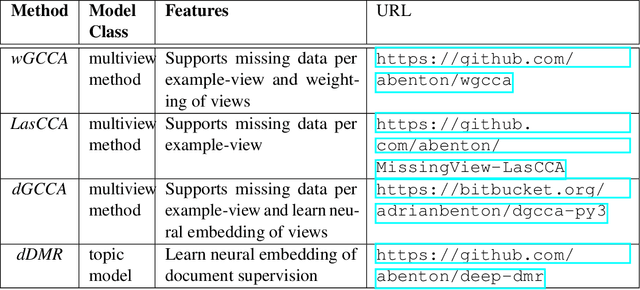
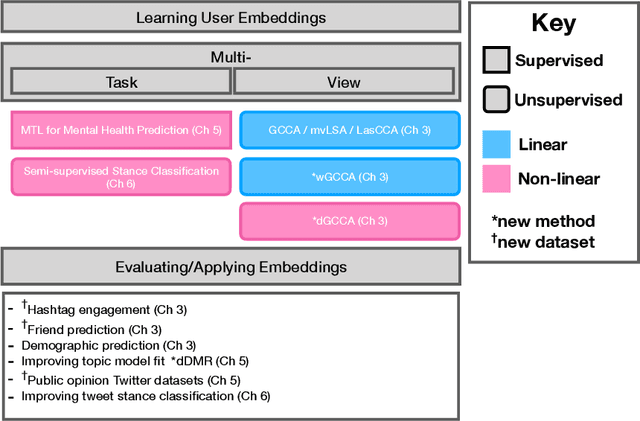
User representations are routinely used in recommendation systems by platform developers, targeted advertisements by marketers, and by public policy researchers to gauge public opinion across demographic groups. Computer scientists consider the problem of inferring user representations more abstractly; how does one extract a stable user representation - effective for many downstream tasks - from a medium as noisy and complicated as social media? The quality of a user representation is ultimately task-dependent (e.g. does it improve classifier performance, make more accurate recommendations in a recommendation system) but there are proxies that are less sensitive to the specific task. Is the representation predictive of latent properties such as a person's demographic features, socioeconomic class, or mental health state? Is it predictive of the user's future behavior? In this thesis, we begin by showing how user representations can be learned from multiple types of user behavior on social media. We apply several extensions of generalized canonical correlation analysis to learn these representations and evaluate them at three tasks: predicting future hashtag mentions, friending behavior, and demographic features. We then show how user features can be employed as distant supervision to improve topic model fit. Finally, we show how user features can be integrated into and improve existing classifiers in the multitask learning framework. We treat user representations - ground truth gender and mental health features - as auxiliary tasks to improve mental health state prediction. We also use distributed user representations learned in the first chapter to improve tweet-level stance classifiers, showing that distant user information can inform classification tasks at the granularity of a single message.
Multi-Task Learning for Mental Health using Social Media Text
Dec 10, 2017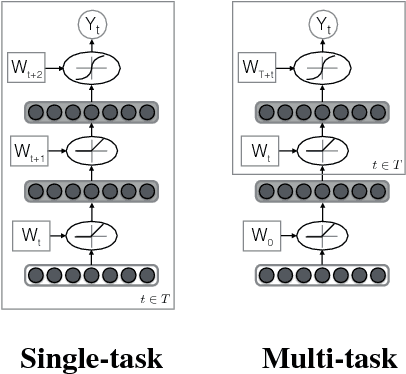
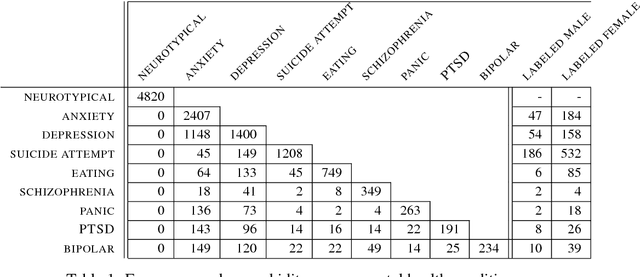
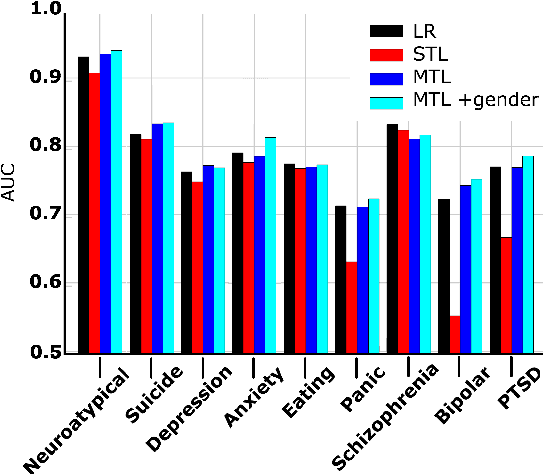
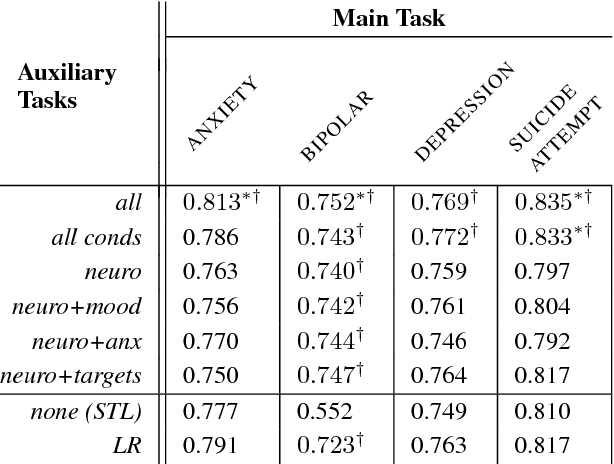
We introduce initial groundwork for estimating suicide risk and mental health in a deep learning framework. By modeling multiple conditions, the system learns to make predictions about suicide risk and mental health at a low false positive rate. Conditions are modeled as tasks in a multi-task learning (MTL) framework, with gender prediction as an additional auxiliary task. We demonstrate the effectiveness of multi-task learning by comparison to a well-tuned single-task baseline with the same number of parameters. Our best MTL model predicts potential suicide attempt, as well as the presence of atypical mental health, with AUC > 0.8. We also find additional large improvements using multi-task learning on mental health tasks with limited training data.