 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Communication while Maximizing Performance in Multi-Agent Reinforcement Learning
Jun 18, 2021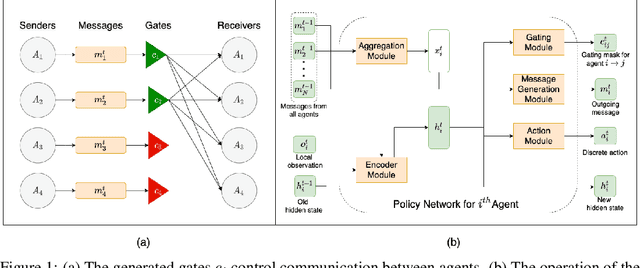

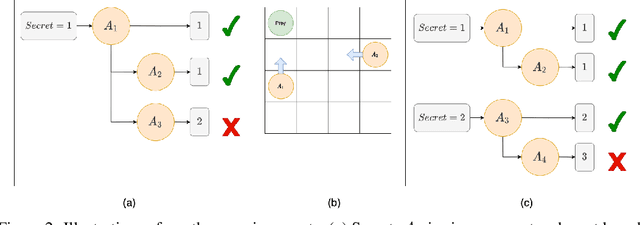
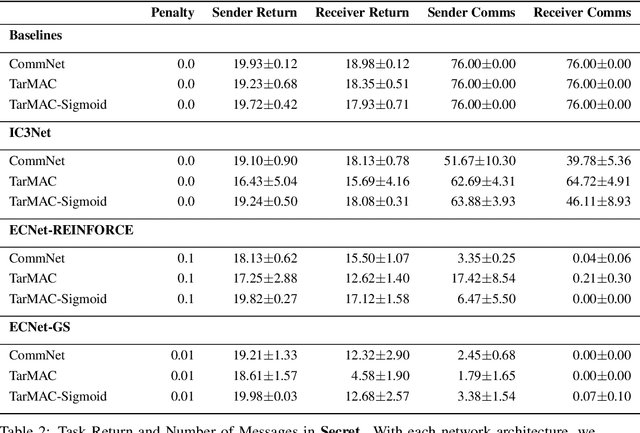
Inter-agent communication can significantly increase performance in multi-agent tasks that require co-ordination to achieve a shared goal. Prior work has shown that it is possible to learn inter-agent communication protocols using multi-agent reinforcement learning and message-passing network architectures. However, these models use an unconstrained broadcast communication model, in which an agent communicates with all other agents at every step, even when the task does not require it. In real-world applications, where communication may be limited by system constraints like bandwidth, power and network capacity, one might need to reduce the number of messages that are sent. In this work, we explore a simple method of minimizing communication while maximizing performance in multi-task learning: simultaneously optimizing a task-specific objective and a communication penalty. We show that the objectives can be optimized using Reinforce and the Gumbel-Softmax reparameterization. We introduce two techniques to stabilize training: 50% training and message forwarding. Training with the communication penalty on only 50% of the episodes prevents our models from turning off their outgoing messages. Second, repeating messages received previously helps models retain information, and further improves performance. With these techniques, we show that we can reduce communication by 75% with no loss of performance.
Neuroevolution-Enhanced Multi-Objective Optimization for Mixed-Precision Quantization
Jun 14, 2021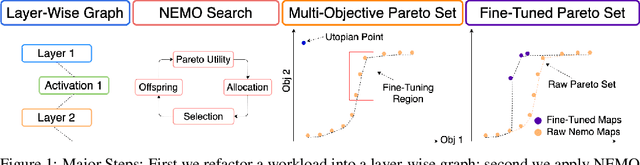
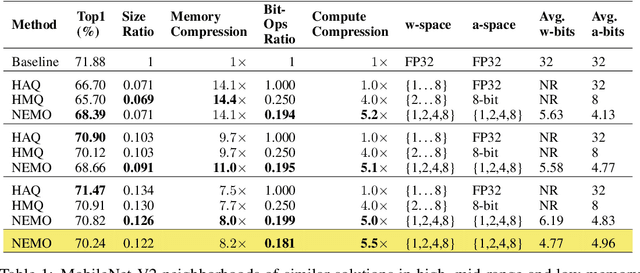
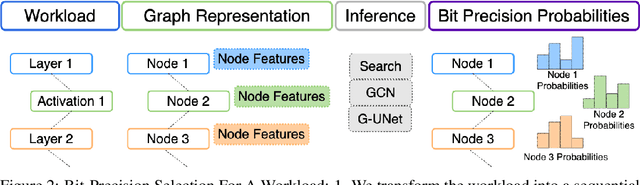
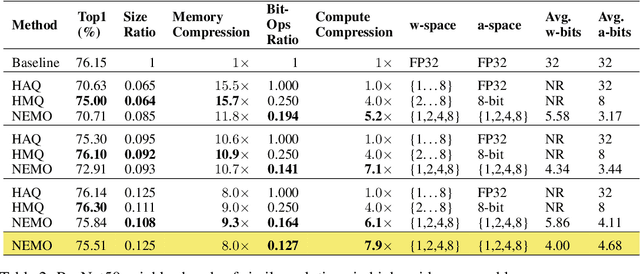
Mixed-precision quantization is a powerful tool to enable memory and compute savings of neural network workloads by deploying different sets of bit-width precisions on separate compute operations. Recent research has shown significant progress in applying mixed-precision quantization techniques to reduce the memory footprint of various workloads, while also preserving task performance. Prior work, however, has often ignored additional objectives, such as bit-operations, that are important for deployment of workloads on hardware. Here we present a flexible and scalable framework for automated mixed-precision quantization that optimizes multiple objectives. Our framework relies on Neuroevolution-Enhanced Multi-Objective Optimization (NEMO), a novel search method, to find Pareto optimal mixed-precision configurations for memory and bit-operations objectives. Within NEMO, a population is divided into structurally distinct sub-populations (species) which jointly form the Pareto frontier of solutions for the multi-objective problem. At each generation, species are re-sized in proportion to the goodness of their contribution to the Pareto frontier. This allows NEMO to leverage established search techniques and neuroevolution methods to continually improve the goodness of the Pareto frontier. In our experiments we apply a graph-based representation to describe the underlying workload, enabling us to deploy graph neural networks trained by NEMO to find Pareto optimal configurations for various workloads trained on ImageNet. Compared to the state-of-the-art, we achieve competitive results on memory compression and superior results for compute compression for MobileNet-V2, ResNet50 and ResNeXt-101-32x8d. A deeper analysis of the results obtained by NEMO also shows that both the graph representation and the species-based approach are critical in finding effective configurations for all workloads.
Instance based Generalization in Reinforcement Learning
Nov 02, 2020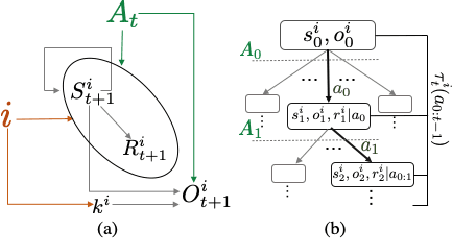
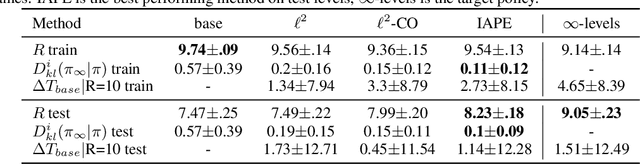
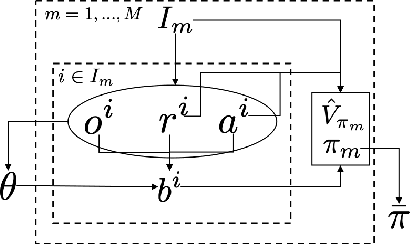

Agents trained via deep reinforcement learning (RL) routinely fail to generalize to unseen environments, even when these share the same underlying dynamics as the training levels. Understanding the generalization properties of RL is one of the challenges of modern machine learning. Towards this goal, we analyze policy learning in the context of Partially Observable Markov Decision Processes (POMDPs) and formalize the dynamics of training levels as instances. We prove that, independently of the exploration strategy, reusing instances introduces significant changes on the effective Markov dynamics the agent observes during training. Maximizing expected rewards impacts the learned belief state of the agent by inducing undesired instance specific speedrunning policies instead of generalizeable ones, which are suboptimal on the training set. We provide generalization bounds to the value gap in train and test environments based on the number of training instances, and use insights based on these to improve performance on unseen levels. We propose training a shared belief representation over an ensemble of specialized policies, from which we compute a consensus policy that is used for data collection, disallowing instance specific exploitation. We experimentally validate our theory, observations, and the proposed computational solution over the CoinRun benchmark.
Language-Conditioned Imitation Learning for Robot Manipulation Tasks
Oct 22, 2020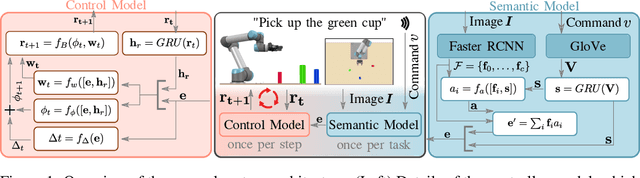
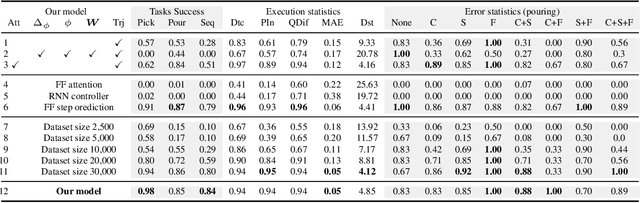
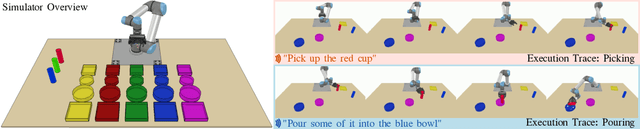
Imitation learning is a popular approach for teaching motor skills to robots. However, most approaches focus on extracting policy parameters from execution traces alone (i.e., motion trajectories and perceptual data). No adequate communication channel exists between the human expert and the robot to describe critical aspects of the task, such as the properties of the target object or the intended shape of the motion. Motivated by insights into the human teaching process, we introduce a method for incorporating unstructured natural language into imitation learning. At training time, the expert can provide demonstrations along with verbal descriptions in order to describe the underlying intent (e.g., "go to the large green bowl"). The training process then interrelates these two modalities to encode the correlations between language, perception, and motion. The resulting language-conditioned visuomotor policies can be conditioned at runtime on new human commands and instructions, which allows for more fine-grained control over the trained policies while also reducing situational ambiguity. We demonstrate in a set of simulation experiments how our approach can learn language-conditioned manipulation policies for a seven-degree-of-freedom robot arm and compare the results to a variety of alternative methods.
Motion2Vec: Semi-Supervised Representation Learning from Surgical Videos
May 31, 2020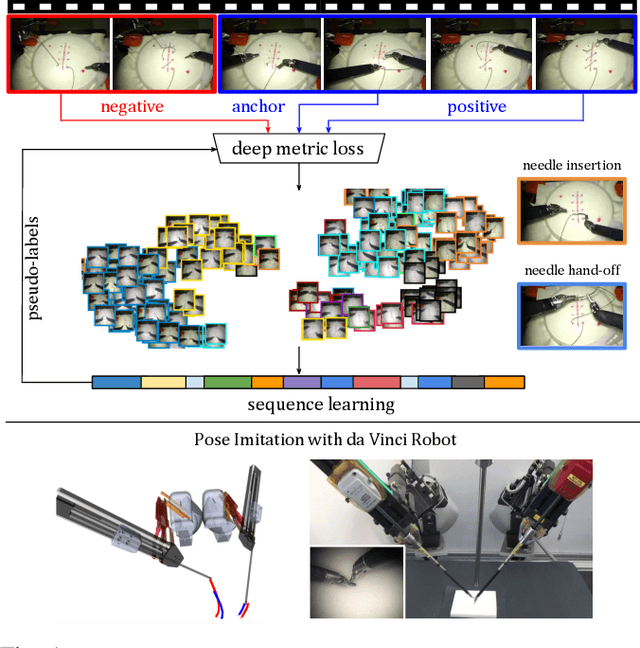
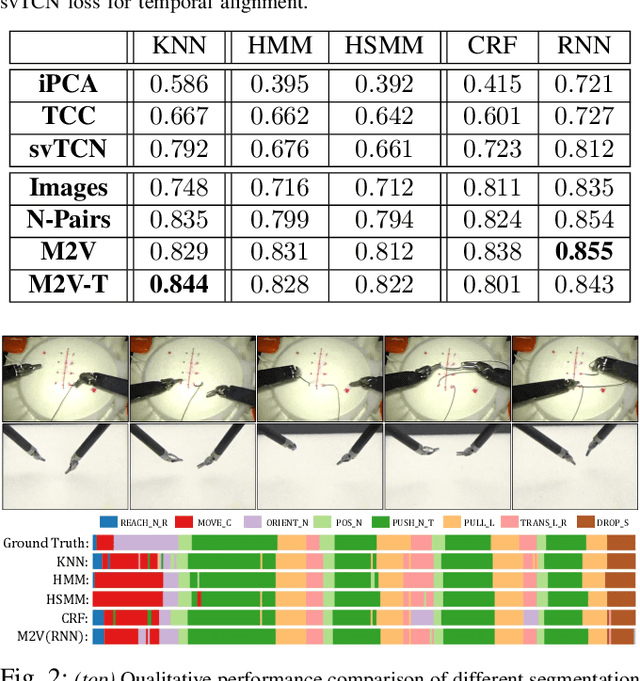
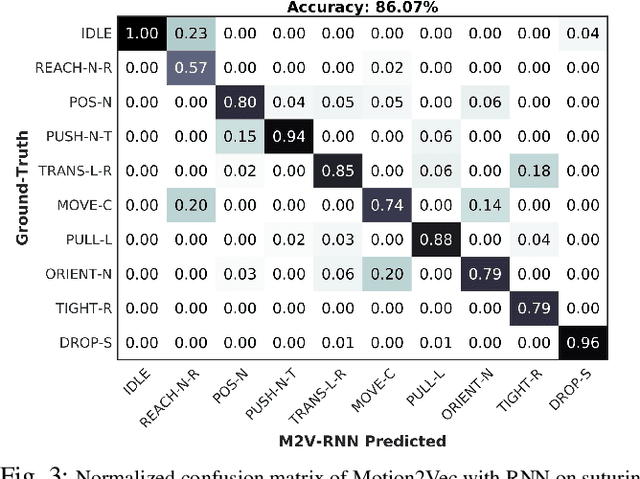
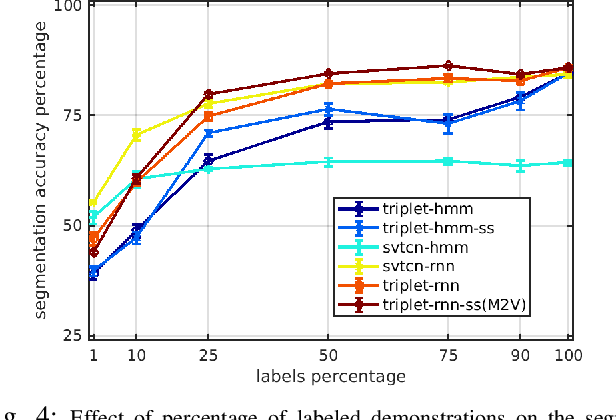
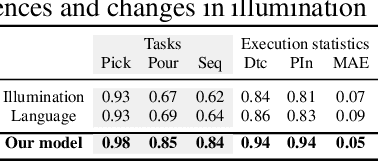
Learning meaningful visual representations in an embedding space can facilitate generalization in downstream tasks such as action segmentation and imitation. In this paper, we learn a motion-centric representation of surgical video demonstrations by grouping them into action segments/sub-goals/options in a semi-supervised manner. We present Motion2Vec, an algorithm that learns a deep embedding feature space from video observations by minimizing a metric learning loss in a Siamese network: images from the same action segment are pulled together while pushed away from randomly sampled images of other segments, while respecting the temporal ordering of the images. The embeddings are iteratively segmented with a recurrent neural network for a given parametrization of the embedding space after pre-training the Siamese network. We only use a small set of labeled video segments to semantically align the embedding space and assign pseudo-labels to the remaining unlabeled data by inference on the learned model parameters. We demonstrate the use of this representation to imitate surgical suturing motions from publicly available videos of the JIGSAWS dataset. Results give 85.5 % segmentation accuracy on average suggesting performance improvement over several state-of-the-art baselines, while kinematic pose imitation gives 0.94 centimeter error in position per observation on the test set. Videos, code and data are available at https://sites.google.com/view/motion2vec
Imitation Learning of Robot Policies by Combining Language, Vision and Demonstration
Nov 26, 2019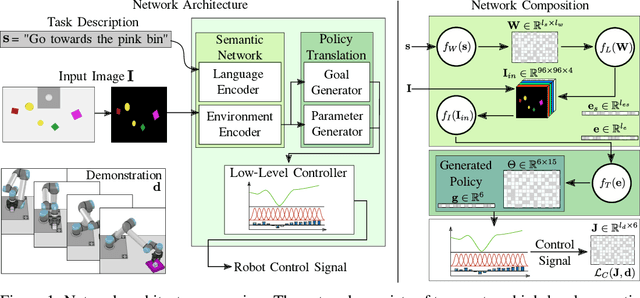
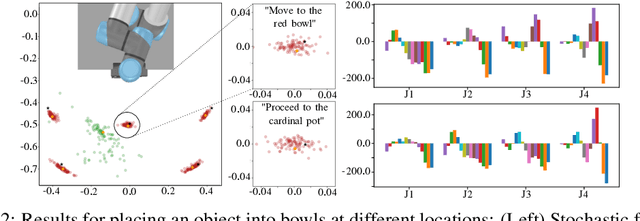
In this work we propose a novel end-to-end imitation learning approach which combines natural language, vision, and motion information to produce an abstract representation of a task, which in turn is used to synthesize specific motion controllers at run-time. This multimodal approach enables generalization to a wide variety of environmental conditions and allows an end-user to direct a robot policy through verbal communication. We empirically validate our approach with an extensive set of simulations and show that it achieves a high task success rate over a variety of conditions while remaining amenable to probabilistic interpretability.
On Training Flexible Robots using Deep Reinforcement Learning
Jul 13, 2019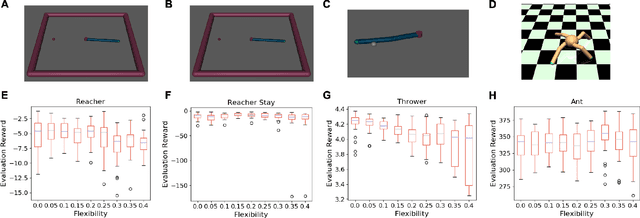


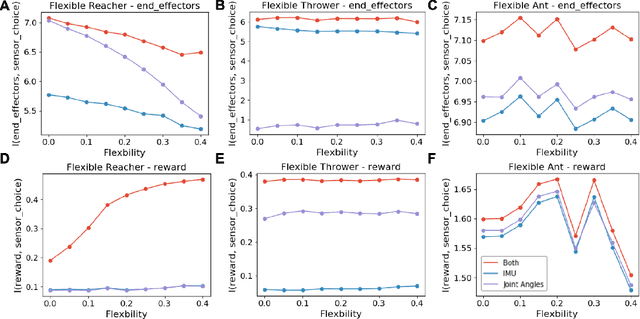
The use of robotics in controlled environments has flourished over the last several decades and training robots to perform tasks using control strategies developed from dynamical models of their hardware have proven very effective. However, in many real-world settings, the uncertainties of the environment, the safety requirements and generalized capabilities that are expected of robots make rigid industrial robots unsuitable. This created great research interest into developing control strategies for flexible robot hardware for which building dynamical models are challenging. In this paper, inspired by the success of deep reinforcement learning (DRL) in other areas, we systematically study the efficacy of policy search methods using DRL in training flexible robots. Our results indicate that DRL is successfully able to learn efficient and robust policies for complex tasks at various degrees of flexibility. We also note that DRL using Deep Deterministic Policy Gradients can be sensitive to the choice of sensors and adding more informative sensors does not necessarily make the task easier to learn.
Goal-conditioned Imitation Learning
Jun 13, 2019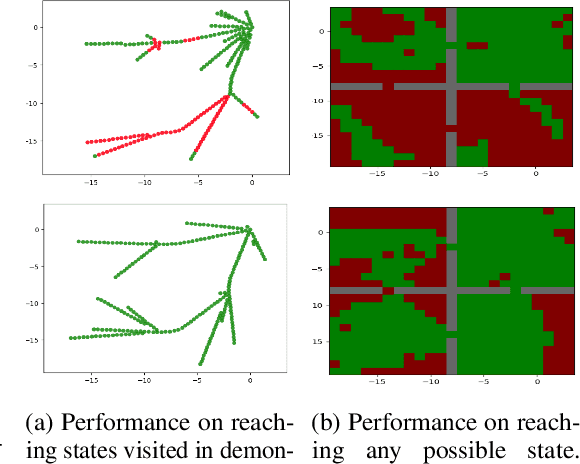

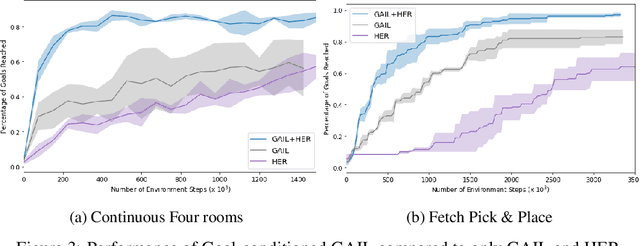
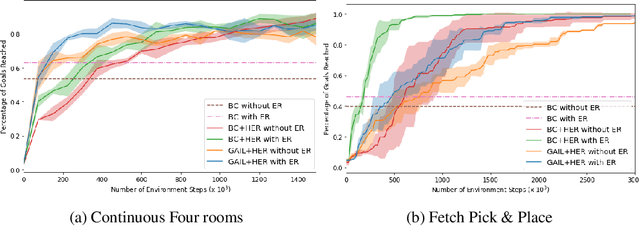
Designing rewards for Reinforcement Learning (RL) is challenging because it needs to convey the desired task, be efficient to optimize, and be easy to compute. The latter is particularly problematic when applying RL to robotics, where detecting whether the desired configuration is reached might require considerable supervision and instrumentation. Furthermore, we are often interested in being able to reach a wide range of configurations, hence setting up a different reward every time might be unpractical. Methods like Hindsight Experience Replay (HER) have recently shown promise to learn policies able to reach many goals, without the need of a reward. Unfortunately, without tricks like resetting to points along the trajectory, HER might take a very long time to discover how to reach certain areas of the state-space. In this work we investigate different approaches to incorporate demonstrations to drastically speed up the convergence to a policy able to reach any goal, also surpassing the performance of an agent trained with other Imitation Learning algorithms. Furthermore, our method can be used when only trajectories without expert actions are available, which can leverage kinestetic or third person demonstration. The code is available at https://sites.google.com/view/goalconditioned-il/ .